Ottimizzazione della memorizzazione dei dati Esplorazione dei tipi di dati e della normalizzazione in SQL
Ottimizzazione della memorizzazione dei dati e normalizzazione in SQL.

Nel secolo presente, i dati sono il nuovo petrolio. Ottimizzare questo archivio dati è sempre critico per ottenerne una buona performance. Optare per tipi di dati adatti e applicare il processo di normalizzazione corretto è essenziale per decidere la sua performance.
Questo articolo studierà i tipi di dati più importanti e comunemente utilizzati e comprenderà il processo di normalizzazione.
- Efficienti modelli di lingua piccoli il parametro 1.3 miliardi di phi-1.5 di Microsoft
- Ricercatori dell’Università di Tokyo presentano una nuova tecnica per proteggere le applicazioni sensibili basate sull’intelligenza artificiale AI dagli attacchi degli aggressori.
- Tracciamento degli esperimenti di Machine Learning utilizzando MLflow
Tipi di dati in SQL
Ci sono principalmente due tipi di dati in SQL: Stringa e Numerico. Oltre a questi, ci sono tipi di dati aggiuntivi come Booleano, Data e Ora, Array, Intervallo, XML, ecc.
Tipi di dati stringa
Questi tipi di dati vengono utilizzati per memorizzare stringhe di caratteri. La stringa è spesso implementata come un tipo di dati array e contiene una sequenza di elementi, tipicamente caratteri.
- CHAR(n):
È una stringa di lunghezza fissa che può contenere caratteri, numeri e caratteri speciali. n indica la lunghezza massima della stringa in caratteri che può contenere.
Il suo intervallo massimo va da 0 a 255 caratteri e il problema con questo tipo di dati è che occupa tutto lo spazio specificato, anche se la lunghezza effettiva della stringa è inferiore. La lunghezza extra della stringa viene riempita con spazio di memoria extra.
- VARCHAR(n):
Varchar è simile a Char ma può supportare stringhe di dimensione variabile e non c’è alcun riempimento. La dimensione di archiviazione di questo tipo di dati è uguale alla lunghezza effettiva della stringa.
Può memorizzare fino a un massimo di 65535 caratteri. A causa della sua natura di dimensione variabile, le sue prestazioni non sono buone come il tipo di dati CHAR.
- BINARY(n):
È simile al tipo di dati CHAR ma accetta solo stringhe binarie o dati binari. Può essere utilizzato per memorizzare immagini, file o qualsiasi oggetto serializzato. C’è un altro tipo di dati VARBINARY(n) che è simile al tipo di dati VARCHAR ma accetta anche solo stringhe binarie o dati binari.
- TEXT(n):
Questo tipo di dati viene utilizzato anche per memorizzare le stringhe ma ha una dimensione massima di 65535 byte.
- BLOB(n): Stands for Binary Large Object e contiene dati fino a 65535 byte.
Oltre a questi ci sono altri tipi di dati, come LONGTEXT e LONGBLOB, che possono memorizzare ancora più caratteri.
Tipi di dati numerici
- INT():
Può memorizzare un intero numerico, che è di 4 byte (32 bit). Qui n indica la larghezza di visualizzazione, che può essere un massimo di 255. Specifica il numero minimo di caratteri utilizzati per visualizzare i valori interi.
Intervallo:
- a) -2147483648 <= Intero con segno <= 2147483647
- b) 0 <= Intero senza segno <= 4294967295
- BIGINT():
Può memorizzare un grande intero di dimensioni fino a 64 bit.
Intervallo:
- a) -9223372036854775808 <= Big Integer con segno <= 9223372036854775807
- b) 0 <= Big Integer senza segno <= 18446744073709551615
- FLOAT():
Può memorizzare numeri in virgola mobile con posizioni decimali approssimate con una certa precisione. Ha alcuni piccoli errori di arrotondamento, quindi non è adatto dove è richiesta una precisione esatta.
- DOUBLE():
Questo tipo di dato rappresenta numeri a virgola mobile con doppia precisione. Può memorizzare valori decimali con una precisione maggiore rispetto al tipo di dato FLOAT.
- DECIMAL(n, d):
Questo tipo di dato rappresenta numeri decimali esatti con una precisione fissa indicata da d. Il parametro d specifica il numero di cifre dopo il punto decimale e il parametro n indica la dimensione del numero. Il valore massimo per d è 30 e il suo valore predefinito è 0.
Alcuni altri Tipi di Dati
- BOOLEAN:
Questo tipo di dato memorizza solo due stati, True o False. Viene utilizzato per eseguire operazioni logiche.
- ENUM:
Sta per Enumerazione. Consente di scegliere un valore dalla lista delle opzioni predefinite. Assicura anche che il valore memorizzato sia solo tra le opzioni specificate.
Ad esempio, consideriamo un attributo color che può essere solo 'Rosso', 'Verde' o 'Blu'. Quando inseriamo questi valori in ENUM, il valore del color può essere solo tra questi colori specificati.
- XML:
XML sta per eXtensible Markup Language. Questo tipo di dato viene utilizzato per memorizzare dati XML utilizzati per la rappresentazione di dati strutturati.
- AutoNumber:
È un numero intero che incrementa automaticamente il suo valore quando viene aggiunto ogni record. Viene utilizzato per generare numeri unici o sequenziali.
- Hyperlink:
Può memorizzare gli hyperlink di file e pagine web.
Questo completa la nostra discussione sui Tipi di Dati SQL. Ci sono molti altri tipi di dati, ma quelli che abbiamo discusso sono i più comunemente utilizzati.
Normalizzazione in SQL
La normalizzazione è il processo di eliminazione di ridondanze, inconsistenze ed anomalie dal database. La ridondanza significa la presenza di valori duplicati dello stesso dato, mentre le inconsistenze nel database rappresentano lo stesso dato esistente in formati multipli in tabelle multiple.
Le anomalie del database possono essere definite come qualsiasi cambiamento improvviso o discrepanza nel database che non dovrebbe esistere. Questi cambiamenti possono essere causati da vari motivi, come la corruzione dei dati, un guasto hardware, errori software, ecc. Le anomalie possono portare a gravi conseguenze, come la perdita o l’incoerenza dei dati, quindi è essenziale rilevarle e correggerle il prima possibile. Ci sono principalmente tre tipi di anomalie. Ne discuteremo brevemente ciascuna, ma se desideri leggere ulteriormente, consulta questo articolo.
- Anomalia di Inserimento:
Quando la riga appena inserita crea un’incoerenza nella tabella, si verifica un’anomalia di inserimento. Ad esempio, vogliamo aggiungere un dipendente a un’organizzazione, ma il suo reparto non gli è stato assegnato. In quel caso, non possiamo aggiungere quel dipendente alla tabella, creando così un’anomalia di inserimento.
- Anomalia di Cancellazione:
L’anomalia di cancellazione si verifica quando vogliamo cancellare alcune righe dalla tabella e alcuni altri dati devono essere eliminati dal database.
- Anomalia di Aggiornamento:
Questa anomalia si verifica quando vogliamo aggiornare alcune righe e ciò porta a un’incoerenza nel database.
Il processo di normalizzazione comprende una serie di linee guida che rendono il design del database efficiente, ottimizzato e privo di ridondanze e anomalie. Ci sono diversi tipi di normalizzazione come 1NF, 2NF, 3NF, BCNF, ecc.
1. Prima Forma Normale (1NF)
La prima forma normale garantisce che la tabella non contenga attributi composti o multivalore. Ciò significa che è presente un solo valore in un singolo attributo. Una relazione è in prima forma normale se ogni attributo è unico.
Ad esempio-
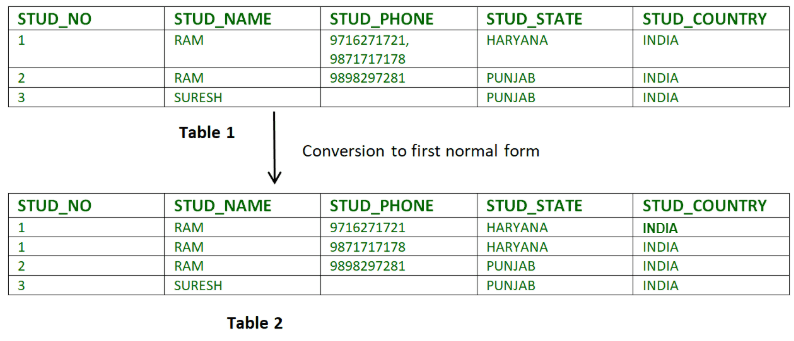
Nella Tabella 1, l’attributo STUD_PHONE contiene più di un numero di telefono. Ma nella Tabella 2, questo attributo è decomposto nella prima forma normale.
2. Seconda Forma Normale
La tabella deve essere nella prima forma normale e non devono esserci dipendenze parziali nelle relazioni. La dipendenza parziale significa che l’attributo non primo (attributi che non fanno parte della chiave candidata) è parzialmente dipendente o dipende da un sottoinsieme appropriato della chiave candidata. Perché le relazioni siano nella seconda forma normale, gli attributi non primi devono essere completamente funzionali e dipendenti dall’intera chiave candidata.
Ad esempio, considera una tabella chiamata Impiegati che ha i seguenti attributi.
IDImpiegato (Chiave Primaria)
IDProgetto (Chiave Primaria)
NomeImpiegato
NomeProgetto
OreLavorate
Qui l’IDImpiegato e l’IDProgetto insieme formano la chiave primaria. Tuttavia, puoi notare una dipendenza parziale tra NomeImpiegato e IDImpiegato. Significa che il NomeImpiegato dipende solo dalla parte della chiave primaria (cioè IDImpiegato). Per una dipendenza completa, il NomeImpiegato deve dipendere sia da IDImpiegato che da IDProgetto. Quindi, questo viola il principio della seconda forma normale.
Per rendere questa relazione nella seconda forma normale, dobbiamo dividere le tabelle in due tabelle separate. La prima tabella contiene tutti i dettagli degli impiegati, e la seconda contiene tutti i dettagli dei progetti.
Quindi, la tabella Impiegato ha i seguenti attributi,
IDImpiegato (Chiave Primaria)
NomeImpiegato
E la tabella Progetto ha i seguenti attributi,
IDProgetto (Chiave Primaria)
NomeProgetto
OreLavorate
Ora puoi vedere che la dipendenza parziale viene rimossa creando due tabelle indipendenti. E gli attributi non primi di entrambe le tabelle dipendono dall’intero insieme della chiave primaria.
3. Terza Forma Normale
Dopo la 2NF, le relazioni possono ancora avere anomalie di aggiornamento. Ciò può accadere se aggiorniamo solo una tupla e non l’altra. Ciò porterebbe a un’incoerenza nel database.
La condizione per la terza forma normale è che la tabella dovrebbe essere nella 2NF e non ci deve essere dipendenza transitiva per gli attributi non primi. La dipendenza transitiva si verifica quando un attributo non primo dipende da un altro attributo non primo anziché dipendere direttamente dall’attributo primario. Gli attributi primi sono gli attributi che fanno parte della chiave candidata.
Considera una relazione R(A, B, C), dove A è la chiave primaria e B & C sono gli attributi non primi. Se A→B e B→C sono due Dipendenze Funzionali, allora A→C sarà la dipendenza transitiva. Significa che l’attributo C non è determinato direttamente da A. B funge da intermediario tra loro.
Se una tabella presenta una dipendenza transitiva, possiamo portare la tabella nella 3NF suddividendola in relazioni indipendenti separate.
4. Forma Normale di Boyce-Codd
Anche se la 2NF e la 3NF eliminano la maggior parte delle ridondanze, le ridondanze non vengono eliminate al 100%. La ridondanza può verificarsi se il LHS della dipendenza funzionale non è una chiave candidata o superchiave. Una Chiave Candidata si forma dagli attributi primi e la Superchiave è un superset della chiave candidata. Per risolvere questo problema, è disponibile un altro tipo di dipendenza funzionale chiamata Forma Normale di Boyce-Codd (BCNF).
Perché una tabella sia in BCNF, il lato sinistro di una dipendenza funzionale deve essere una chiave candidata o una superchiave. Ad esempio, per una dipendenza funzionale X→Y, X deve essere una chiave candidata o una superchiave.
Considera una tabella Impiegato che contiene i seguenti attributi.
- IDImpiegato (chiave primaria)
- NomeImpiegato
- Dipartimento
- Responsabile del Dipartimento
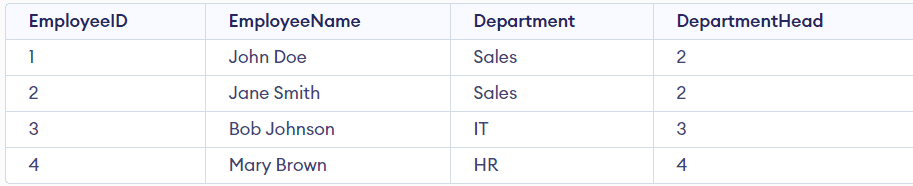
L’EmployeeID è la chiave primaria che identifica univocamente ogni riga. L’attributo Dipartimento rappresenta il dipartimento di un determinato dipendente, mentre l’attributo Capo Dipartimento rappresenta l’Employee ID del dipendente che è il capo di quel dipartimento specifico.
Ora verificheremo se questa tabella è nella BCNF (Boyce-Codd Normal Form). La condizione è che il LHS (lato sinistro) della dipendenza funzionale deve essere una superchiave. Di seguito sono riportate le due dipendenze funzionali di quella tabella.
Dipendenza Funzionale 1: Employee ID → Employee Name, Department, Department Head
Dipendenza Funzionale 2: Department → Department Head
Per la Dipendenza Funzionale 1, l’EmployeeID è la chiave primaria, che è anche una superchiave. Ma per la Dipendenza Funzionale 2, il Dipartimento non è una superchiave perché più dipendenti possono trovarsi nello stesso dipartimento.
Quindi questa tabella viola la condizione della BCNF. Per soddisfare la proprietà della BCNF, è necessario suddividere quella tabella in due tabelle separate: Employees e Departments. La tabella Employees contiene l’EmployeeID, l’EmployeeName e il Dipartimento, mentre la tabella Department avrà il Dipartimento e il Capo Dipartimento.
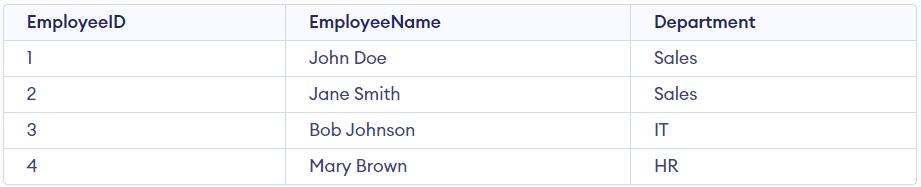

Ora possiamo vedere in entrambe le tabelle che tutte le dipendenze funzionali dipendono dalle chiavi primarie, cioè non ci sono dipendenze non banali.
Abbiamo coperto tutte le famose tecniche di normalizzazione, ma oltre a queste, ci sono altre due forme normali, ovvero la 4NF e la 5NF. Se vuoi saperne di più su di esse, consulta questo articolo di GeeksForGeeks.
Conclusione
Abbiamo discusso dei tipi di dati più comunemente utilizzati in SQL e delle tecniche di normalizzazione significative nei sistemi di gestione di database. Durante la progettazione di un sistema di database, miriamo a renderlo scalabile, riducendo al minimo la ridondanza e garantendo l’integrità dei dati.
Possiamo creare un equilibrio delicato tra archiviazione, precisione e consumo di memoria selezionando i tipi di dati appropriati. Inoltre, il processo di normalizzazione aiuta a eliminare le anomalie dei dati e rende lo schema più organizzato.
È tutto per oggi. Fino ad allora, continua a leggere e continua a imparare. Aryan Garg è uno studente di Ingegneria Elettrica B.Tech., attualmente all’ultimo anno del suo corso di laurea. Il suo interesse è nel campo dello sviluppo web e dell’apprendimento automatico. Ha coltivato questo interesse ed è desideroso di lavorare ulteriormente in queste direzioni.