Suggerimenti pratici per migliorare l’Analisi Esplorativa dei Dati
Suggerimenti per migliorare l'Analisi Esplorativa dei Dati
Una breve guida per facilitare e migliorare l’EDA
Introduzione
L’analisi esplorativa dei dati (EDA) è un passaggio obbligatorio prima di utilizzare qualsiasi modello di apprendimento automatico. Il processo di EDA richiede concentrazione e pazienza da parte degli analisti e degli scienziati dei dati: prima di ottenere informazioni significative dai dati analizzati, spesso è necessario dedicare molto tempo all’utilizzo attivo di una o più librerie di visualizzazione.
In questo post, condividerò con te alcuni consigli su come semplificare la procedura di EDA e renderla più veloce, basati sulla mia esperienza personale. In particolare, ti darò tre importanti consigli che ho imparato lottando contro l’EDA:
- Utilizza grafici non banali adatti alla tua attività;
- Applica appieno le funzionalità della libreria di visualizzazione;
- Cerca un modo più veloce per ottenere gli stessi risultati.
Nota: per creare infografiche in questo post, utilizzeremo i Dati sulla Generazione di Energia Eolica da Kaggle [2]. Cominciamo!
Consiglio 1: Non avere paura di utilizzare grafici non banali
Ho imparato come applicare questo consiglio quando ho lavorato a un articolo di ricerca relativo all’analisi e alla previsione dell’energia eolica [1]. Durante l’EDA per questo progetto, mi sono trovato nella necessità di creare una matrice di riepilogo che riflettesse tutte le relazioni tra i parametri del vento al fine di individuare quali di essi influenzassero maggiormente gli altri. La prima idea che mi è venuta in mente è stata quella di costruire una “buona vecchia” matrice di correlazione che avevo visto in molti progetti di Data Science / Data Analysis.
- Metriche di valutazione per i sistemi di raccomandazione – Una panoramica
- Svolta nell’intersezione di visione e linguaggio presentazione del progetto All-Seeing
- Una guida completa a MLOps
Come sai, una matrice di correlazione viene utilizzata per quantificare e riassumere le relazioni lineari tra le variabili. Nel frammento di codice seguente, la funzione corrcoef è stata utilizzata sulle colonne delle caratteristiche dei Dati sulla Generazione di Energia Eolica. Qui ho anche applicato la funzione heatmap di Seaborn per rappresentare la matrice di correlazione come una mappa di calore:
import matplotlib.pyplot as pltimport seaborn as snsimport pandas as pdimport numpy as np# leggi i datidata = pd.read_csv('T1.csv')print(data)# rinomina le colonne per abbreviare i lorotitoli data.rename(columns={'LV ActivePower (kW)':'P', 'Wind Speed (m/s)':'Ws', 'Theoretical_Power_Curve (KWh)':'Power_curve', 'Wind Direction (°)': 'Wa'},inplace=True)cols = ['P', 'Ws', 'Power_curve', 'Wa']# costruisci la matricematrice_di_correlazione = np.corrcoef(data[cols].values.T)hm = sns.heatmap(matrice_di_correlazione, cbar=True, annot=True, square=True, fmt='.3f', annot_kws={'size': 15}, cmap='Blues', yticklabels=['P', 'Ws', 'Power_curve', 'Wa'], xticklabels=['P', 'Ws', 'Power_curve', 'Wa'])# salva la figuraplt.savefig('immagine.png', dpi=600, bbox_inches='tight')plt.show()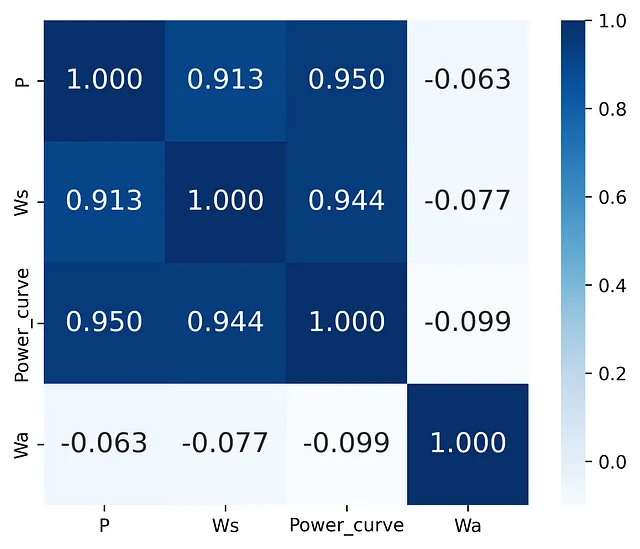
Analizzando i risultati grafici ottenuti, si può concludere che la velocità del vento e la potenza attiva hanno una forte correlazione, ma penso che molti saranno d’accordo con me nel dire che questa non è un’interpretazione facile dei risultati quando si utilizza questo tipo di visualizzazione, perché qui abbiamo solo numeri.
Un’ottima alternativa alla matrice di correlazione sarebbe la matrice di scatterplot, che consente di visualizzare le correlazioni tra le varie caratteristiche di un set di dati in un unico posto. In questo caso, dovrebbe essere utilizzato sns.pairplot:
import matplotlib.pyplot as pltimport seaborn as snsimport pandas as pd# leggi i datidata = pd.read_csv('T1.csv')print(data)# rinomina le colonne per abbreviare i lorotitoli data.rename(columns={'LV ActivePower (kW)':'P', 'Wind Speed (m/s)':'Ws', 'Theoretical_Power_Curve (KWh)':'Power_curve', 'Wind Direction (°)': 'Wa'},inplace=True)cols = ['P', 'Ws', 'Power_curve', 'Wa']# costruisci la matricens.pairplot(data[cols], height=2.5)plt.tight_layout()# salva la figuraplt.savefig('immagine2.png', dpi=600, bbox_inches='tight')plt.show()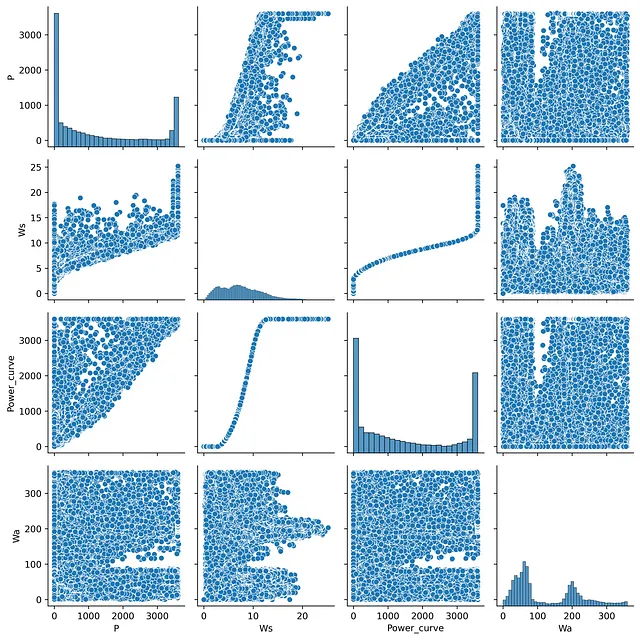
Osservando la matrice di scatterplot, è possibile valutare rapidamente come i dati sono distribuiti e se contengono o meno valori anomali. Tuttavia, il principale svantaggio di questo tipo di grafici è legato alla presenza di duplicati dovuti all’approccio di rappresentazione dei dati a coppie.
Alla fine, ho deciso di combinare i grafici sopra in uno solo, in cui la parte inferiore sinistra conterrà gli scatter plot dei parametri selezionati, mentre la parte superiore destra conterrà bolle di diverse dimensioni e colori: cerchi più grandi indicano una correlazione lineare più forte tra i parametri studiati. La diagonale della matrice mostrerà la distribuzione di ciascuna caratteristica: un picco stretto qui indicherebbe che quel particolare parametro non cambia molto, mentre altre caratteristiche cambiano.
Il codice per costruire questa matrice di riepilogo è riportato di seguito. Qui la mappa è composta da tre parti: fig.map_lower, fig.map_diag, fig.map_upper:
import pandas as pdimport matplotlib.pyplot as pltimport seaborn as sns# leggi i dati data = pd.read_csv('T1.csv')print(data)# rinomina le colonne per abbreviarne i titoli data.rename(columns={'LV ActivePower (kW)':'P', 'Wind Speed (m/s)':'Ws', 'Theoretical_Power_Curve (KWh)':'Power_curve', 'Wind Direction (°)': 'Wa'},inplace=True)cols = ['P', 'Ws', 'Power_curve', 'Wa']# costruisci la matricedef correlation_dots(*args, **kwargs): corr_r = args[0].corr(args[1], 'pearson') ax = plt.gca() ax.set_axis_off() marker_size = abs(corr_r) * 3000 ax.scatter([.5], [.5], marker_size, [corr_r], alpha=0.5, cmap = 'Blues', vmin = -1, vmax = 1, transform = ax.transAxes) font_size = abs(corr_r) * 40 + 5sns.set(style = 'white', font_scale = 1.6)fig = sns.PairGrid(data, aspect = 1.4, diag_sharey = False)fig.map_lower(sns.regplot)fig.map_diag(sns.histplot)fig.map_upper(correlation_dots)# salva l'immagineplt.savefig('image3.jpg', dpi = 600, bbox_inches = 'tight')plt.show()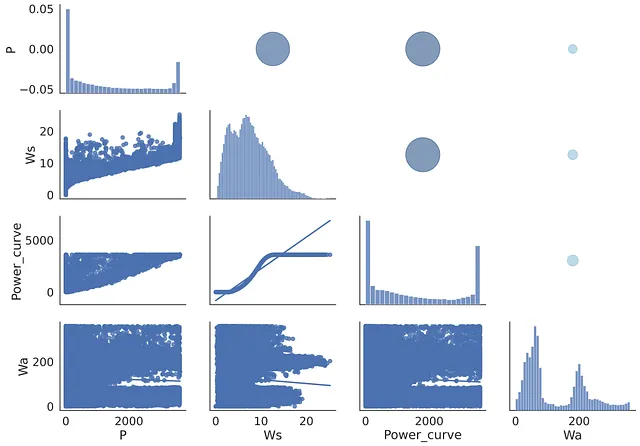
La matrice di riepilogo combina i vantaggi dei due diagrammi precedentemente studiati: la sua parte inferiore (sinistra) imita la matrice di scatterplot, mentre il suo frammento superiore (destro) riflette graficamente i risultati numerici della matrice di correlazione.
Suggerimento 2: Utilizza appieno le funzionalità della libreria di visualizzazione
Di tanto in tanto devo presentare i risultati dell’EDA a colleghi e clienti, quindi la visualizzazione è un assistente fondamentale per me in questo compito. Cerco sempre di aggiungere vari elementi ai diagrammi, come frecce e note, per renderli ancora più attraenti e leggibili.
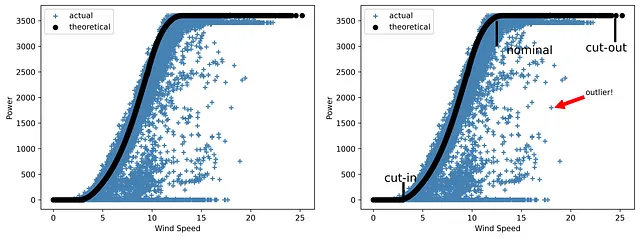
Torniamo al caso di implementazione dell’EDA per un progetto eolico discusso in precedenza. Quando si tratta di energia eolica, uno dei parametri più importanti è una curva di potenza. La curva di potenza di una turbina eolica (o dell’intero parco eolico) è un grafico che mostra la quantità di elettricità generata a diverse velocità del vento. È importante notare che le turbine non funzionano a basse velocità del vento. La loro accensione è associata a una velocità di avviamento, che di solito si trova nell’intervallo da 2,5 a 5 m/s. Alle velocità comprese tra 12 e 15 m/s si raggiunge la potenza nominale. Infine, ogni turbina ha un limite superiore di velocità del vento a cui può funzionare in sicurezza. Una volta raggiunto questo limite di velocità di spegnimento, la turbina eolica non produrrà elettricità a meno che la sua velocità non torni nell’intervallo di funzionamento.
Il dataset studiato include sia la curva di potenza teorica (che è una curva tipica del produttore senza valori anomali) che la curva effettiva ottenuta se rappresentiamo la potenza eolica in funzione della velocità. Quest’ultima di solito contiene molti punti al di fuori della forma teorica ideale, che potrebbero essere causati da guasti delle turbine, misurazioni SCADA errate o manutenzione non programmata.
Ora creeremo un’immagine che mostrerà entrambi i tipi di curva di potenza – prima senza alcun elemento aggiuntivo, ad eccezione della legenda:
import pandas as pdimport matplotlib.pyplot as plt# leggere i dati dati = pd.read_csv('T1.csv')print(data)# rinominare le colonne per renderle più brevi data.rename(columns={'LV ActivePower (kW)':'P', 'Wind Speed (m/s)':'Ws', 'Theoretical_Power_Curve (KWh)':'Power_curve', 'Wind Direction (°)': 'Wa'},inplace=True)# costruire il grafico plt.scatter(data['Ws'], data['P'], color='steelblue', marker='+', label='reale')plt.scatter(data['Ws'], data['Power_curve'], color='black', label='teorica')plt.xlabel('Velocità del vento')plt.ylabel('Potenza')plt.legend(loc='best')# salvare il graficoplt.savefig('immagine4.png', dpi=600, bbox_inches='tight')plt.show()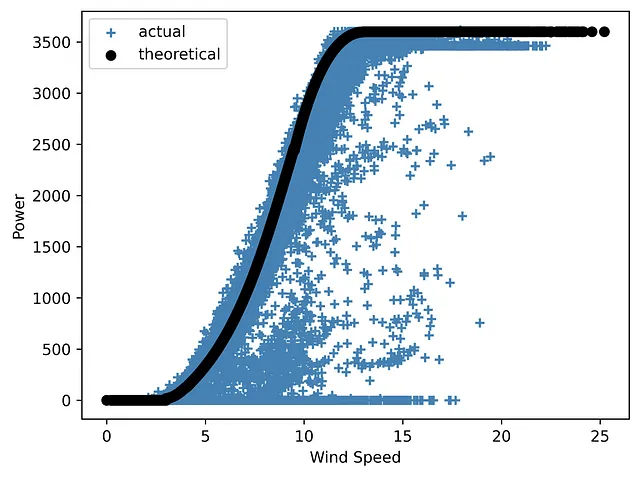
Come puoi vedere, il grafico ha bisogno di una spiegazione, poiché non contiene dettagli aggiuntivi.
Ma cosa succede se aggiungiamo delle linee per evidenziare le tre aree principali del grafico con le velocità di cut-in, nominali e cut-out marcate, oltre a una nota con una freccia per mostrare uno degli outliers?
Vediamo come apparirà il grafico in questo caso:
import pandas as pdimport matplotlib.pyplot as plt# leggere i dati dati = pd.read_csv('T1.csv')print(data)# rinominare le colonne per renderle più brevi data.rename(columns={'LV ActivePower (kW)':'P', 'Wind Speed (m/s)':'Ws', 'Theoretical_Power_Curve (KWh)':'Power_curve', 'Wind Direction (°)': 'Wa'},inplace=True)# costruire il grafico plt.scatter(data['Ws'], data['P'], color='steelblue', marker='+', label='reale')plt.scatter(data['Ws'], data['Power_curve'], color='black', label='teorica')# aggiungere linee verticali, note di testo e una frecciaplt.vlines(x=3.05, ymin=10, ymax=350, lw=3, color='black')plt.text(1.1, 355, r"cut-in", fontsize=15)plt.vlines(x=12.5, ymin=3000, ymax=3500, lw=3, color='black')plt.text(13.5, 2850, r"nominal", fontsize=15)plt.vlines(x=24.5, ymin=3080, ymax=3550, lw=3, color='black')plt.text(21.5, 2900, r"cut-out", fontsize=15)plt.annotate('outlier!', xy=(18.4,1805), xytext=(21.5,2050), arrowprops={'color':'red'})plt.xlabel('Velocità del vento')plt.ylabel('Potenza')plt.legend(loc='best')# salvare il graficoplt.savefig('immagine4_2.png', dpi=600, bbox_inches='tight')plt.show()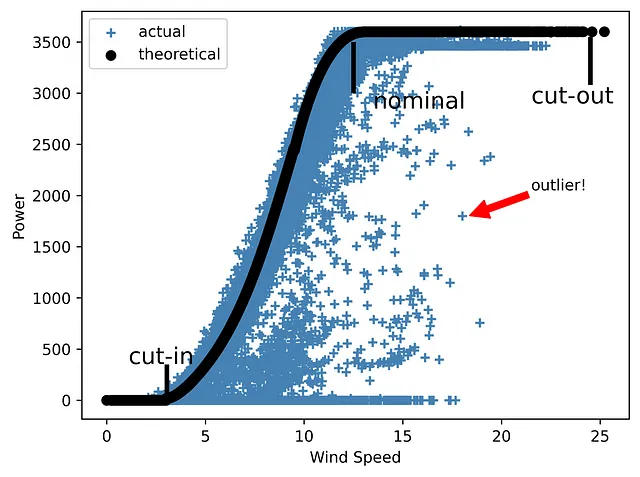
Suggerimento 3: Trova sempre un modo più veloce per fare le stesse cose
Quando si analizzano i dati del vento, spesso si desidera avere informazioni complete sul potenziale dell’energia eolica. Pertanto, oltre alla dinamica dell’energia eolica, è necessario avere un grafico che mostri come la velocità del vento dipende dalla direzione del vento.
Per illustrare le variazioni nella potenza del vento, è possibile utilizzare il seguente codice:
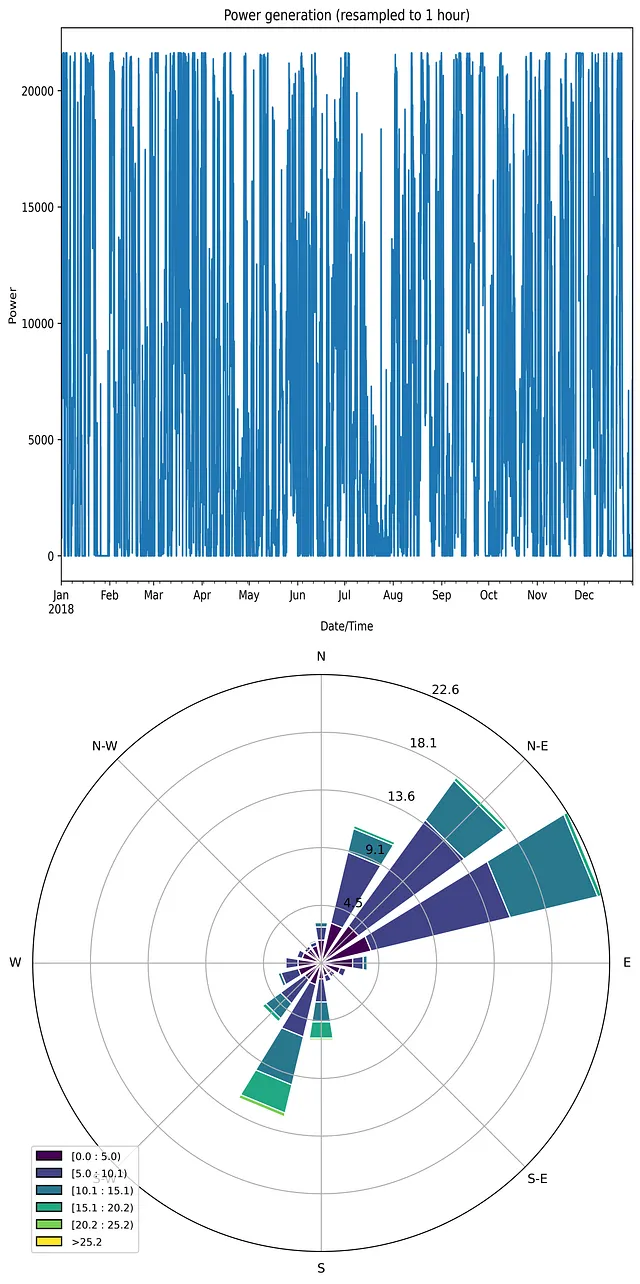
import pandas as pdimport matplotlib.pyplot as plt# leggere i dati dati = pd.read_csv('T1.csv')print(data)# rinominare le colonne per renderle più brevi data.rename(columns={'LV ActivePower (kW)':'P', 'Wind Speed (m/s)':'Ws', 'Theoretical_Power_Curve (KWh)':'Power_curve', 'Wind Direction (°)': 'Wa'},inplace=True)# ridimensionare i dati da 10 minuti a misurazioni orarie data['Date/Time'] = pd.to_datetime(data['Date/Time'])fig = plt.figure(figsize=(10,8))group_data = (data.set_index('Date/Time')).resample('H')['P'].sum()# tracciare la dinamica della potenza del ventogroup_data.plot(kind='line')plt.ylabel('Potenza')plt.xlabel('Data/Ora')plt.title('Generazione di energia (ridimensionata a 1 ora)')# salvare il graficoplt.savefig('potenza_vento.png', dpi=600, bbox_inches='tight')plt.show()Di seguito è riportato il grafico risultante:
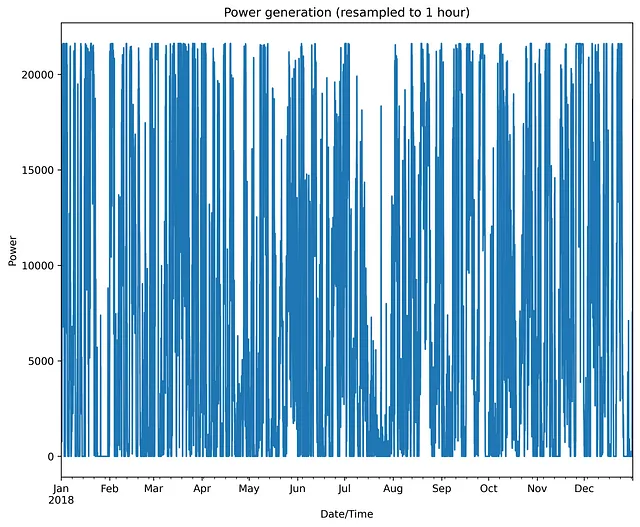
Come si può notare, il profilo della dinamica dell’energia eolica ha una forma complessa e irregolare.
Una rosa dei venti, o un grafico a rosa polare, è un diagramma speciale per rappresentare la distribuzione dei dati meteorologici, tipicamente velocità del vento per direzione [3]. Esiste un modulo semplice windrose per la libreria matplotlib, che consente di creare facilmente questo tipo di visualizzazioni, ad esempio:
import pandas as pdimport matplotlib.pyplot as pltimport numpy as npfrom windrose import WindroseAxes# leggi i dati data = pd.read_csv('T1.csv')print(data)# rinomina le colonne per rendere i titoli più brevi data.rename(columns={'LV ActivePower (kW)':'P', 'Wind Speed (m/s)':'Ws', 'Theoretical_Power_Curve (KWh)':'Power_curve', 'Wind Direction (°)': 'Wa'}, inplace=True)wd = data['Wa']ws = data['Ws']# disegna una rosa dei venti normalizzata sotto forma di istogramma a barre sovrapposteax = WindroseAxes.from_ax()ax.bar(wd, ws, normed=True, opening=0.8, edgecolor='white')ax.set_legend()# salva l'immagineplt.savefig('windrose.png', dpi = 600, bbox_inches = 'tight')plt.show()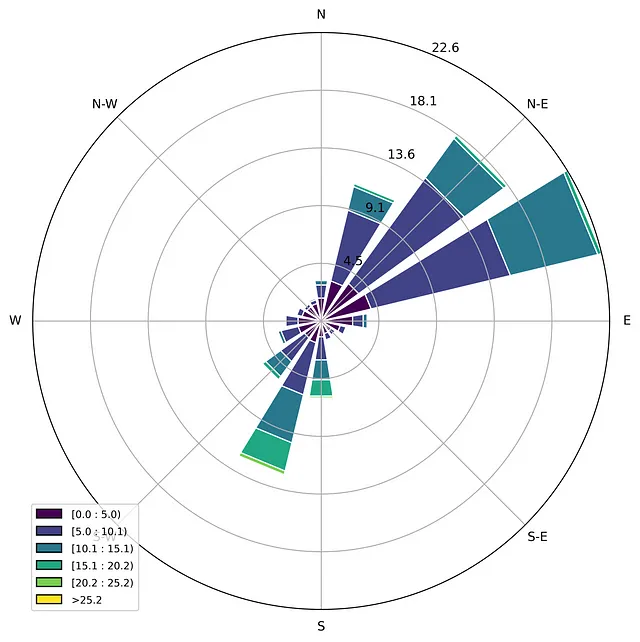
Osservando la mappa della rosa dei venti, si può notare che ci sono due direzioni principali del vento: nord-est e sud-ovest.
Ma come unire queste due immagini in una singola immagine? L’opzione più ovvia è utilizzare add_subplot. Tuttavia, a causa delle peculiarità della libreria windrose, non è un compito immediato:
import pandas as pdimport matplotlib.pyplot as pltimport numpy as npfrom windrose import WindroseAxes# leggi i dati data = pd.read_csv('T1.csv')print(data)# rinomina le colonne per rendere i titoli più brevi data.rename(columns={'LV ActivePower (kW)':'P', 'Wind Speed (m/s)':'Ws', 'Theoretical_Power_Curve (KWh)':'Power_curve', 'Wind Direction (°)': 'Wa'}, inplace=True)data['Date/Time'] = pd.to_datetime(data['Date/Time'])fig = plt.figure(figsize=(10,8))# disegna entrambi i grafici come sottograficiax1 = fig.add_subplot(211)group_data = (data.set_index('Date/Time')).resample('H')['P'].sum()group_data.plot(kind='line')ax1.set_ylabel('Potenza')ax1.set_xlabel('Data/Ora')ax1.set_title('Generazione di energia (campionata ogni 1 ora)')ax2 = fig.add_subplot(212, projection='windrose')wd = data['Wa']ws = data['Ws']ax = WindroseAxes.from_ax()ax2.bar(wd, ws, normed=True, opening=0.8, edgecolor='white')ax2.set_legend()# salva l'immagineplt.savefig('image5.png', dpi=600, bbox_inches='tight')plt.show()In questo caso, il risultato appare così:
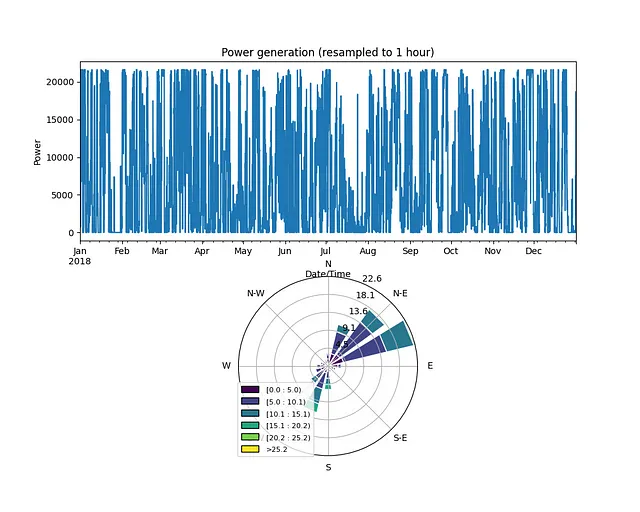
Il principale svantaggio qui è che i due sottografici differiscono in dimensione e a causa di ciò abbiamo molto spazio vuoto bianco intorno al grafico della rosa dei venti.
Per semplificare le cose, consiglio di adottare un approccio diverso, utilizzando la libreria Python Imaging Library (PIL) [4] con soli 11 (!) righe di codice:
import numpy as np
import PIL
from PIL import Image
# elenca le immagini da unire
list_im = ['wind_power.png', 'windrose.png']
imgs = [PIL.Image.open(i) for i in list_im]
# ridimensiona tutte le immagini per farle corrispondere alla più piccola
min_shape = sorted([(np.sum(i.size), i.size) for i in imgs])[0][1]
imgs_comb = np.vstack((np.asarray(i.resize(min_shape)) for i in imgs))
images_comb = PIL.Image.fromarray(imgs_comb)
# salva l'immagine
images_comb.save('image5_2.png', dpi=(600,600))
In questo caso l’output è un po’ più carino, perché due immagini hanno le stesse dimensioni, dato che il codice sceglie quella più piccola e ridimensiona le altre per farle corrispondere:
A proposito, lavorando con PIL è possibile utilizzare anche una concatenazione orizzontale. Ad esempio, confrontiamo e confrontiamo due grafici delle curve di potenza “silenziose” e “parlanti” tra loro:
import numpy as np
import PIL
from PIL import Image
list_im = ['image4.png', 'image4_2.png']
imgs = [PIL.Image.open(i) for i in list_im]
# scegli l'immagine più piccola e ridimensiona le altre per farle corrispondere (può essere arbitraria la forma dell'immagine qui)
min_shape = sorted([(np.sum(i.size), i.size) for i in imgs])[0][1]
imgs_comb = np.hstack((np.asarray(i.resize(min_shape)) for i in imgs))
# salva l'immagine
imgs_comb = PIL.Image.fromarray(imgs_comb)
imgs_comb.save('image4_merged.png', dpi=(600,600))
Conclusioni
In questo post ho condiviso con te tre consigli su come rendere più semplice il processo di EDA. Spero che tu abbia trovato utili questi consigli e che inizierai a applicarli anche alle tue attività di analisi dei dati.
Questi suggerimenti si adattano perfettamente alla formula che cerco sempre di applicare durante l’EDA: personalizza → elenca → ottimizza.
Beh, potresti chiederti, perché tutto questo è importante? Posso dire che in realtà è importante, perché:
- È molto importante personalizzare i tuoi grafici alle esigenze particolari che stai affrontando in quel momento. Ad esempio, anziché creare tonnellate di infografiche, pensa a come puoi combinarne diverse in una sola, come abbiamo fatto creando una matrice di riepilogo, che combina i punti di forza sia del grafico a dispersione che dei grafici di correlazione.
- Tutti i tuoi grafici dovrebbero parlare da soli. Pertanto, devi sapere come elencare le informazioni importanti nel grafico per renderlo dettagliato e ben leggibile. Confronta quanto è grande la differenza tra le curve di potenza “silenziose” e “parlanti”.
- E infine, ogni specialista dei dati dovrebbe imparare come ottimizzare il processo di EDA per rendere le cose più veloci (e la vita più facile). Se devi unire due immagini in una, non è necessario utilizzare l’opzione
add_subplotogni volta.
Cosa altro? Posso sicuramente dire che l’EDA è un passo molto creativo e interessante nel lavoro con i dati (senza dimenticare che è anche molto importante).
Lascia che le tue infografiche brillino come diamanti e non dimenticare di goderti il processo!
Elenco delle referenze
- Articolo “Data-driven applications for wind energy analysis and prediction: The case of “La Haute Borne” wind farm”. https://doi.org/10.1016/j.dche.2022.100048
- Dati generati dalla potenza del vento: https://www.kaggle.com/datasets/bhavikjikadara/wind-power-generated-data?resource=download
- Tutorial sulla libreria windrose: https://windrose.readthedocs.io/en/latest/index.html
- Libreria PIL: https://pillow.readthedocs.io/en/stable/index.html
Grazie per la lettura!






