Riconoscimento del linguaggio parlato su Mozilla Common Voice – Trasformazioni audio.
Riconoscimento linguaggio parlato su Mozilla Common Voice - Trasformazioni audio.
Questo è il terzo articolo sul riconoscimento del linguaggio parlato basato sul dataset Mozilla Common Voice. Nella Parte I, abbiamo discusso la selezione dei dati e la loro pre-elaborazione, e nella Parte II abbiamo analizzato le prestazioni di diversi classificatori di reti neurali.
Il modello finale ha raggiunto un’accuratezza del 92% e un’accuratezza pairwise del 97%. Poiché questo modello soffre di una varianza leggermente elevata, l’accuratezza potrebbe potenzialmente essere migliorata aggiungendo più dati. Un modo molto comune per ottenere dati aggiuntivi è sintetizzarli attraverso l’esecuzione di varie trasformazioni sul dataset disponibile.
In questo articolo, prenderemo in considerazione 5 trasformazioni popolari per l’aumento dei dati audio: aggiunta di rumore, cambio di velocità, cambio di tonalità, mascheratura temporale e taglio e incolla.
Il quaderno di esercitazione può essere trovato qui.
- Stability AI svela StableLM Alpha in giapponese un balzo in avanti nel modello di lingua giapponese.
- Top 10 estensioni di VS Code per aumentare la produttività del 10x
- Il team di PlayHT presenta un modello di intelligenza artificiale con il concetto di emozioni per l’IA vocale generativa questo ti permetterà di controllare e dirigere la generazione del discorso con una particolare emozione.
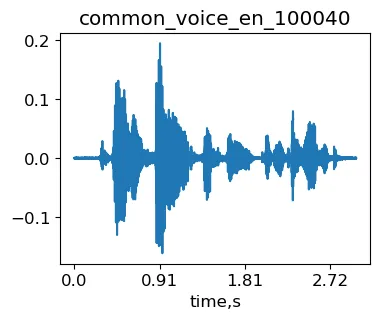
A scopo illustrativo, utilizzeremo l’esempio common_voice_en_100040 dal dataset Mozilla Common Voice (MCV). Questa è la frase “Il fuoco ardente era stato spento”.
import librosa as lrimport IPythonsignal, sr = lr.load('./transformed/common_voice_en_100040.wav', res_type='kaiser_fast') #carica il segnaleIPython.display.Audio(signal, rate=sr)Esempio originale common_voice_en_100040 da MCV.
Aggiunta di rumore
L’aggiunta di rumore è l’aumento audio più semplice. La quantità di rumore è caratterizzata dal rapporto segnale-rumore (SNR) – il rapporto tra l’ampiezza massima del segnale e la deviazione standard del rumore. Genereremo diversi livelli di rumore, definiti con SNR, e vedremo come cambiano il segnale.
SNRs = (5,10,100,1000) #Rapporto segnale-rumore: ampiezza massima su rumore stdnoisy_signal = {}for snr in SNRs: noise_std = max(abs(signal))/snr #ottieni la deviazione standard del rumore noise = noise_std*np.random.randn(len(signal),) #genera rumore con la deviazione standard data noisy_signal[snr] = signal+noiseIPython.display.display(IPython.display.Audio(noisy_signal[5], rate=sr))IPython.display.display(IPython.display.Audio(noisy_signal[1000], rate=sr))Segnali ottenuti sovrapponendo rumore con SNR=5 e SNR=1000 sull’esempio originale MCV common_voice_en_100040 (generato dall’autore).
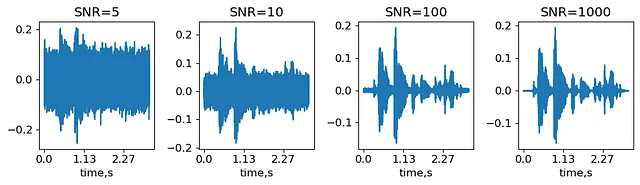
Quindi, SNR=1000 suona quasi come l’audio non disturbato, mentre con SNR=5 si possono distinguere solo le parti più forti del segnale. In pratica, il livello di SNR è un iperparametro che dipende dal dataset e dal classificatore scelto.
Cambiare la velocità
Il modo più semplice per cambiare la velocità è semplicemente fingere che il segnale abbia un diverso tasso di campionamento. Tuttavia, questo cambierà anche la tonalità (quanto basso / alto in frequenza suona l’audio). Aumentando il tasso di campionamento, la voce suonerà più alta. Per illustrare questo, “aumenteremo” il tasso di campionamento per il nostro esempio di 1,5:
IPython.display.Audio(signal, rate=sr*1.5)Segnale ottenuto utilizzando un tasso di campionamento falso per l’esempio originale MCV common_voice_en_100040 (generato dall’autore).
Cambiare la velocità senza influenzare la tonalità è più complicato. È necessario utilizzare l’algoritmo Phase Vocoder (PV). In breve, il segnale in ingresso viene prima suddiviso in frame sovrapposti. Quindi, lo spettro all’interno di ciascun frame viene calcolato applicando la Trasformata di Fourier Veloce (FFT). La velocità di riproduzione viene quindi modificata risintetizzando i frame a un tasso diverso. Poiché il contenuto in frequenza di ciascun frame non viene influenzato, la tonalità rimane la stessa. Il PV interpola tra i frame e utilizza le informazioni di fase per ottenere la fluidità.
Per i nostri esperimenti, utilizzeremo la funzione di stretching del tempo stretch_wo_loop da questa implementazione PV.
stretching_factor = 1.3signal_stretched = stretch_wo_loop(signal, stretching_factor)IPython.display.Audio(signal_stretched, rate=sr)Segnale ottenuto variando la velocità del campione originale MCV common_voice_en_100040 (generato dall’autore).
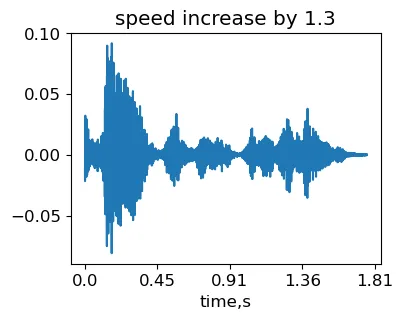
Quindi, la durata del segnale è diminuita poiché abbiamo aumentato la velocità. Tuttavia, si può sentire che l’intonazione non è cambiata. Notare che quando il fattore di stretching è sostanziale, l’interpolazione di fase tra i frame potrebbe non funzionare bene. Di conseguenza, possono apparire artefatti di eco nell’audio trasformato.
Cambiamento di intonazione
Per modificare l’intonazione senza influire sulla velocità, possiamo utilizzare lo stesso stretching temporale PV, ma fingere che il segnale abbia una diversa frequenza di campionamento in modo che la durata totale del segnale rimanga la stessa:
IPython.display.Audio(signal_stretched, rate=sr/stretching_factor)Segnale ottenuto variando l’intonazione del campione originale MCV common_voice_en_100040 (generato dall’autore).
Perché ci preoccupiamo mai di questo PV quando librosa ha già le funzioni time_stretch e pitch_shift? Beh, queste funzioni trasformano il segnale nuovamente nel dominio temporale. Quando è necessario calcolare le embedding successivamente, si perderà tempo con trasformate di Fourier ridondanti. D’altra parte, è facile modificare la funzione stretch_wo_loop in modo che restituisca l’output di Fourier senza effettuare la trasformata inversa. Si potrebbe probabilmente anche cercare nel codice di librosa per ottenere risultati simili.
Time masking e cut & splice
Queste due trasformazioni sono state proposte inizialmente nel dominio delle frequenze (Park et al. 2019). L’idea era di risparmiare tempo sull’FFT utilizzando spettri precomputati per le aumentazioni audio. Per semplicità, mostreremo come queste trasformazioni funzionano nel dominio temporale. Le operazioni elencate possono essere facilmente trasferite nel dominio delle frequenze sostituendo l’asse temporale con gli indici dei frame.
Time masking
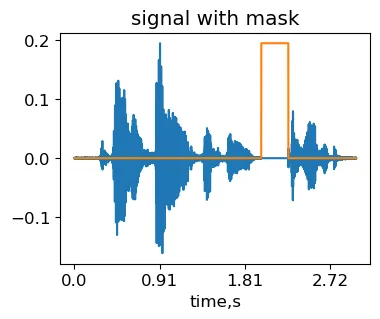
L’idea del time masking è coprire una regione casuale nel segnale. La rete neurale ha quindi meno possibilità di apprendere variazioni temporali specifiche del segnale che non sono generalizzabili.
max_mask_length = 0.3 #durata massima del mask, proporzione della lunghezza del segnaleL = len(signal)mask_length = int(L*np.random.rand()*max_mask_length) #scelta casuale della lunghezza del maskmask_start = int((L-mask_length)*np.random.rand()) #scelta casuale della posizione del maskmasked_signal = signal.copy()masked_signal[mask_start:mask_start+mask_length] = 0IPython.display.Audio(masked_signal, rate=sr)Segnale ottenuto applicando la trasformazione del time mask sul campione originale MCV common_voice_en_100040 (generato dall’autore).
Cut & splice
L’idea è sostituire una regione selezionata casualmente del segnale con un frammento casuale da un altro segnale con la stessa etichetta. L’implementazione è quasi la stessa del time masking, tranne che viene inserito un pezzo di un altro segnale al posto del mask.
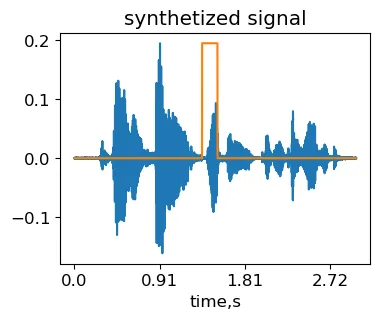
other_signal, sr = lr.load('./common_voice_en_100038.wav', res_type='kaiser_fast') #carica il secondo segnaledurata_massima_fragmento = 0.3 #durata massima del frammento, proporzione della lunghezza del segnaleL = min(len(signal), len(other_signal))mask_length = int(L*np.random.rand()*max_fragment_length) #scelta casuale della lunghezza del maskmask_start = int((L-mask_length)*np.random.rand()) #scelta casuale della posizione del masksynth_signal = signal.copy()synth_signal[mask_start:mask_start+mask_length] = other_signal[mask_start:mask_start+mask_length]IPython.display.Audio(synth_signal, rate=sr)Segnale sintetico ottenuto applicando la trasformazione di cut&splice al campione MCV originale common_voice_en_100040 (generato dall’autore).
La tabella qui di seguito mostra l’accuratezza del modello AttNN sul set di validazione per ciascuna di queste trasformazioni con valori tipici dei parametri:

Come si può vedere, nessuna delle trasformazioni ha cambiato significativamente l’accuratezza della nostra configurazione di riconoscimento vocale basata su MCV. Tuttavia, è possibile che queste trasformazioni possano migliorare le prestazioni su altri dataset. Infine, quando si cercano iperparametri ottimali, ha senso provare queste trasformazioni una per volta anziché una ricerca casuale/griglia. Dopo di ciò, le trasformazioni efficaci possono essere combinate insieme.






