Diffusione stabile di XL su Mac con quantizzazione avanzata di Core ML
Stabile diffusione XL su Mac con Core ML avanzato
Stable Diffusion XL è stato rilasciato ieri ed è fantastico. Può generare immagini di alta qualità di dimensioni grandi (1024×1024); l’aderenza alle istruzioni è stata migliorata grazie a nuovi trucchi; può facilmente produrre immagini molto scure o molto luminose grazie alle ultime ricerche sugli scheduler di rumore; ed è open source!
Il lato negativo è che il modello è molto più grande e quindi più lento e difficile da eseguire su hardware di consumo. Utilizzando l’ultima versione della libreria diffusers di Hugging Face, è possibile eseguire Stable Diffusion XL su hardware CUDA con 16 GB di RAM GPU, rendendo possibile utilizzarlo sul livello gratuito di Colab.
I mesi scorsi hanno dimostrato che le persone sono chiaramente interessate a eseguire modelli di ML in locale per una varietà di motivi, tra cui la privacy, la comodità, la facilità di sperimentazione o l’uso senza limiti. Abbiamo lavorato duramente sia presso Apple che presso Hugging Face per esplorare questo spazio. Abbiamo mostrato come eseguire Stable Diffusion su Apple Silicon, o come sfruttare gli ultimi progressi in Core ML per migliorare dimensioni e prestazioni con palettizzazione a 6 bit.
Per Stable Diffusion XL abbiamo fatto alcune cose:
- La sfidante che mira a detronizzare la supremazia di OpenAI LLM XLSTM
- Ricercatori dell’Imperial College di Londra e di DeepMind hanno progettato un framework di intelligenza artificiale che utilizza il linguaggio come strumento di ragionamento principale di un agente di RL.
- Svelando il futuro dell’analisi del testo Trendy Topic Modeling con BERT
- Portato il modello di base in Core ML in modo da poterlo utilizzare nelle tue app native Swift.
- Aggiornato il repository di conversione e inferenza di Apple in modo da poter convertire i modelli da soli, inclusi eventuali fine-tuning di tuo interesse.
- Aggiornato l’app demo di Hugging Face per mostrare come utilizzare i nuovi modelli Core ML Stable Diffusion XL scaricati dall’Hub.
- Esplorato la palettizzazione a bit misti, una tecnica di compressione avanzata che consente di ottenere importanti riduzioni delle dimensioni minimizzando e controllando la perdita di qualità che si incorre. Puoi applicare la stessa tecnica ai tuoi modelli!
Tutto è open source e disponibile oggi, procediamo.
Contenuti
- Utilizzare modelli SD XL dall’Hub di Hugging Face
- Cosa significa palettizzazione a bit misti?
- Come vengono creati i ricettari a bit misti?
- Conversione di modelli fine-tuned
- Risorse pubblicate
Utilizzare modelli SD XL dall’Hub di Hugging Face
Come parte di questo rilascio, abbiamo pubblicato due diverse versioni di Stable Diffusion XL in Core ML.
apple/coreml-stable-diffusion-xl-baseè un flusso di lavoro completo, senza alcuna quantizzazione.apple/coreml-stable-diffusion-mixed-bit-palettizationcontiene (tra gli altri artefatti) un flusso di lavoro completo in cui l’UNet è stato sostituito con una ricetta di palettizzazione a bit misti che raggiunge una compressione equivalente a 4,5 bit per parametro. Le dimensioni sono diminuite da 4,8 a 1,4 GB, una riduzione del 71%, e secondo noi la qualità è comunque ottima.
Entrambi i modelli possono essere testati utilizzando l’app di inferenza a riga di comando Swift di Apple o l’app demo di Hugging Face. Questo è un esempio di quest’ultima utilizzando il nuovo flusso di lavoro Stable Diffusion XL:
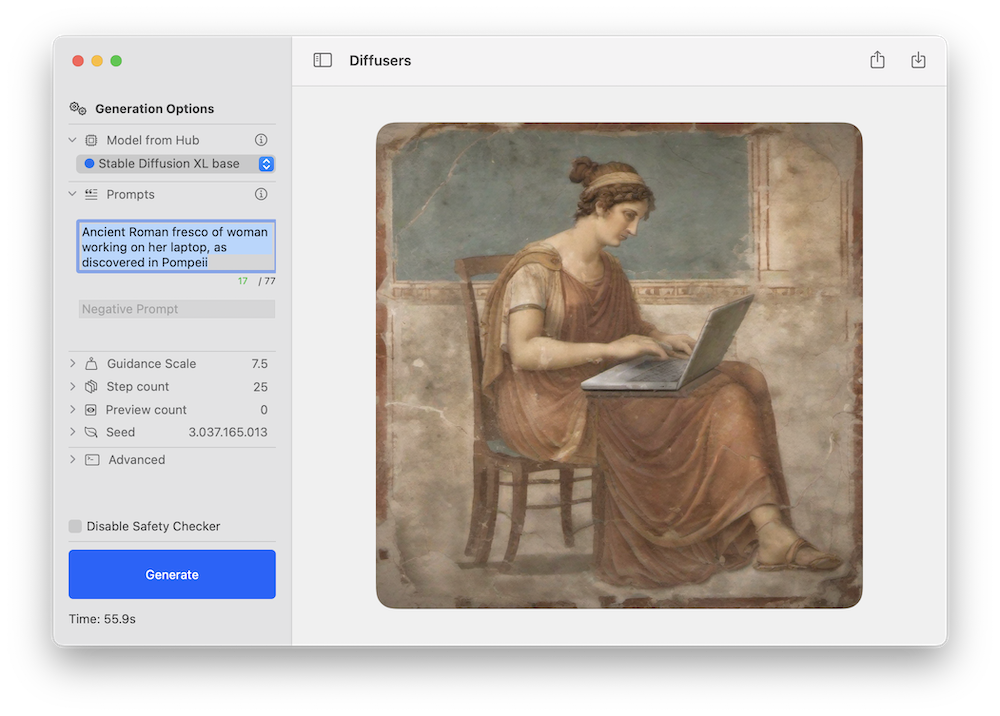
Come con i precedenti rilasci di Stable Diffusion, ci aspettiamo che la comunità crei nuove versioni fine-tuned per diversi domini e molte di esse saranno convertite in Core ML. Puoi tenere d’occhio questo filtro nell’Hub per esplorare!
Stable Diffusion XL funziona su Mac Apple Silicon con la versione beta pubblica di macOS 14. Attualmente utilizza l’implementazione di attenzione ORIGINAL, che è destinata a unità di calcolo CPU + GPU. Nota che la fase di raffinamento non è ancora stata portata.
A titolo di riferimento, questi sono i risultati delle prestazioni che abbiamo ottenuto su diversi dispositivi:
Cosa significa palettizzazione a bit misti?
Il mese scorso abbiamo discusso della palettizzazione a 6 bit, un metodo di quantizzazione post-training che converte pesi a 16 bit in soli 6 bit per parametro. Questo consente una riduzione importante delle dimensioni del modello, ma andare oltre è complicato perché la qualità del modello viene sempre più influenzata man mano che il numero di bit diminuisce.
Un’opzione per ridurre ulteriormente le dimensioni del modello è utilizzare la quantizzazione durante il training, che consiste nel imparare le tabelle di quantizzazione durante il fine-tuning del modello. Questo funziona molto bene, ma è necessario eseguire una fase di fine-tuning per ogni modello che si desidera convertire.
Abbiamo esplorato una diversa alternativa: palettizzazione a bit misti. Invece di utilizzare 6 bit per parametro, esaminiamo il modello e decidiamo quanti bit di quantizzazione utilizzare per ogni layer. Prendiamo la decisione in base a quanto ciascun layer contribuisce al degrado complessivo della qualità, che misuriamo confrontando il PSNR tra il modello quantizzato e il modello originale in modalità float16, per un insieme di pochi input. Esploriamo diverse profondità di bit, per layer: 1 (!), 2, 4 e 8. Se un layer degrada significativamente quando si utilizzano, ad esempio, 2 bit, passiamo a 4 e così via. Alcuni layer potrebbero essere mantenuti in modalità a 16 bit se sono fondamentali per preservare la qualità.
Utilizzando questo metodo, possiamo ottenere quantizzazioni efficaci, ad esempio, di 2,8 bit in media, e misuriamo l’impatto sul degrado per ogni combinazione che proviamo. Ciò ci permette di essere meglio informati sulla migliore quantizzazione da utilizzare per i nostri obiettivi di qualità e dimensioni.
Per illustrare il metodo, consideriamo le seguenti “ricette” di quantizzazione che abbiamo ottenuto da una delle nostre analisi (spiegheremo in seguito come sono state generate):
{
"model_version": "stabilityai/stable-diffusion-xl-base-1.0",
"baselines": {
"originale": 82.2,
"lineare_8bit": 66.025,
"ricetta_6.55_bit_palettamista": 79.9,
"ricetta_4.50_bit_palettamista": 75.8,
"ricetta_3.41_bit_palettamista": 71.7,
},
}Ciò che ci viene detto è che la qualità del modello originale, misurata dal PSNR in float16, è di circa 82 dB. Eseguire una quantizzazione lineare a 8 bit la riduce a 66 dB. Ma poi abbiamo una ricetta che comprime a 6,55 bit per parametro, in media, mantenendo il PSNR a 80 dB. Le seconde e terze ricette riducono ulteriormente le dimensioni del modello, pur mantenendo un PSNR superiore a quello della quantizzazione lineare a 8 bit.
Per esempi visivi, questi sono i risultati sulla prompt una foto di alta qualità di un cane che fa surf eseguendo ciascuna delle tre ricette con lo stesso seed:
Alcune conclusioni iniziali:
- A nostro parere, tutte le immagini hanno una buona qualità in termini di quanto realistiche appaiono. Le versioni 6.55 e 4.50 sono simili alla versione a 16 bit da questo punto di vista.
- Lo stesso seed produce una composizione equivalente, ma non preserverà gli stessi dettagli. Ad esempio, le razze di cane potrebbero essere diverse.
- L’aderenza alla prompt potrebbe degradare aumentando la compressione. In questo esempio, la versione aggressiva 3.41 perde la tavola. Il PSNR confronta solo quanto differiscono complessivamente i pixel, ma non si preoccupa degli oggetti nelle immagini. È necessario esaminare i risultati e valutarli per il proprio caso d’uso.
Questa tecnica è ottima per Stable Diffusion XL perché possiamo mantenere circa le stesse dimensioni di UNet anche se il numero di parametri è triplicato rispetto alla versione precedente. Ma non è esclusiva! Puoi applicare il metodo a qualsiasi modello Stable Diffusion Core ML.
Come vengono create le ricette a bit misti?
Il grafico seguente mostra la potenza del segnale (PSNR in dB) rispetto alla riduzione delle dimensioni del modello (% delle dimensioni float16) per stabilityai/stable-diffusion-xl-base-1.0. Le curve {1,2,4,6,8}-bit sono generate palettizzando progressivamente più layer utilizzando una palette con un numero fisso di bit. I layer sono stati ordinati in ordine crescente del loro impatto isolato sulla potenza del segnale end-to-end, in modo da ritardare il
La palettizzazione a bit misti viene eseguita in due fasi: analisi ed applicazione.
Lo scopo della fase di analisi è trovare punti nella curva a bit misti (quella marrone sopra tutte le altre nella figura) in modo da poter scegliere il compromesso desiderato tra qualità e dimensione. Come menzionato nella sezione precedente, iteriamo attraverso i livelli e selezioniamo le profondità di bit più basse che producono risultati superiori ad una data soglia di PSNR. Ripetiamo il processo per diverse soglie per ottenere diverse strategie di quantizzazione. Il risultato del processo è quindi un insieme di ricette di quantizzazione, dove ogni ricetta è semplicemente un dizionario JSON che dettaglia il numero di bit da utilizzare per ciascun livello nel modello. I livelli con pochi parametri vengono ignorati e mantenuti in float16 per semplicità.
La fase di applicazione semplicemente attraversa la ricetta e applica la palettizzazione con il numero di bit specificato nella struttura JSON.
L’analisi è un processo lungo e richiede una GPU (mps o cuda), poiché dobbiamo eseguire l’inferenza più volte. Una volta completato, l’applicazione della ricetta può essere eseguita in pochi minuti.
Forniamo script per ciascuna di queste fasi:
mixed_bit_compression_pre_analysis.pymixed_bit_compression_apply.py
Conversione di modelli pre-allenati
Se hai precedentemente convertito modelli Stable Diffusion in Core ML, il processo per XL utilizzando il convertitore da riga di comando è molto simile. C’è un nuovo flag per indicare se il modello appartiene alla famiglia XL, e devi usare --attention-implementation ORIGINAL se è il caso.
Per una introduzione al processo, consulta le istruzioni nel repository o uno dei nostri precedenti post sul blog, e assicurati di utilizzare i flag sopra.
Esecuzione della palettizzazione a bit misti
Dopo aver convertito modelli Stable Diffusion o Stable Diffusion XL in Core ML, è possibile applicare facoltativamente la palettizzazione a bit misti utilizzando gli script sopra menzionati.
Poiché il processo di analisi è lento, abbiamo preparato delle ricette per i modelli più popolari:
- Ricette per Stable Diffusion 1.5
- Ricette per Stable Diffusion 2.1
- Ricette per Stable Diffusion XL 1.0 base
Puoi scaricarle ed applicarle localmente per sperimentare.
Inoltre, abbiamo applicato le tre migliori ricette dell’analisi di Stable Diffusion XL alla versione Core ML dell’UNet, e le abbiamo pubblicate qui. Sentiti libero di giocarci e vedere come funzionano per te!
Infine, come menzionato nell’introduzione, abbiamo creato un completo flusso di lavoro Stable Diffusion XL Core ML che utilizza una ricetta da 4.5 bit.
Risorse pubblicate
apple/ml-stable-diffusion, di Apple. Libreria di conversione e inferenza per Swift (e Python).huggingface/swift-coreml-diffusers. App dimostrativa di Hugging Face, costruita sopra il pacchetto di Apple.- Stable Diffusion XL 1.0 base (versione Core ML). Modello pronto per l’esecuzione utilizzando i repository sopra menzionati e altre app di terze parti.
- Stable Diffusion XL 1.0 base, con palettizzazione a bit misti (Core ML). Lo stesso modello di cui sopra, con UNet quantizzato con una palettizzazione efficace di 4.5 bit (in media).
- Ulteriori UNet con palettizzazione a bit misti.
- Ricette di palettizzazione a bit misti, precalcolate per modelli popolari e pronte all’uso.
mixed_bit_compression_pre_analysis.py. Script per eseguire l’analisi a bit misti e la generazione delle ricette.mixed_bit_compression_apply.py. Script per applicare le ricette calcolate durante la fase di analisi.