SHAP per variabili target binarie e multiclasse
SHAP per target binari e multiclassi
Una guida al codice e all’interpretazione dei plot SHAP quando il modello predice una variabile target categorica
I valori SHAP rappresentano il contributo di una caratteristica del modello per una previsione. Per le variabili target binarie, interpretiamo questi valori in termini di log odds. Per i target multiclasse, usiamo la funzione softmax. Faremo le seguenti cose:
- Discuteremo in modo più approfondito queste interpretazioni
- Forniremo il codice per visualizzare i plot SHAP
- Esploreremo nuovi modi di aggregare i valori SHAP per target multiclasse
Puoi anche guardare questo video sull’argomento:
Tutorial SHAP precedente
Continuiamo da un tutorial SHAP precedente. Approfondisce i plot SHAP per una variabile target continua. Vedrai che questi plot e le loro intuizioni sono simili per le variabili target categoriche. Puoi anche trovare il progetto completo su GitHub.
Introduzione a SHAP con Python
Come creare e interpretare i plot SHAP: waterfall, force, mean SHAP, beeswarm e dependence
towardsdatascience.com
- Quantizza i modelli di Llama con GGML e llama.cpp
- Modelli di linguaggio e amici Gorilla, HuggingGPT, TaskMatrix e altro
- Analisi della complessità delle serie temporali utilizzando l’entropia
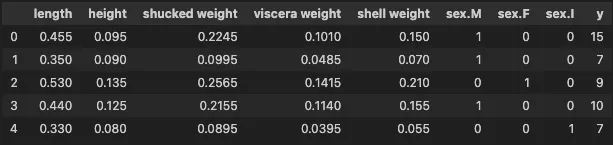
Per riassumere, abbiamo usato SHAP per spiegare un modello costruito utilizzando il dataset abalone. Questo contiene 4.177 istanze e puoi vedere esempi delle caratteristiche qui sotto. Utilizziamo le 8 caratteristiche per prevedere y — il numero di anelli nel guscio dell’abalone. Gli anelli sono correlati all’età dell’abalone. In questo tutorial, divideremo y in gruppi diversi per creare variabili target binarie e multiclasse.
Variabile target binaria
Per la variabile target continua, abbiamo visto che ogni istanza aveva 8 valori SHAP — uno per ogni caratteristica del modello. Come si vede nella Figura 1, se sommiamo questi valori e la previsione media E[f(x)] otteniamo la previsione per quell’istanza f(x). Per le variabili target binarie, abbiamo la stessa proprietà. La differenza è che interpretiamo i valori in termini di log odds di una previsione positiva.
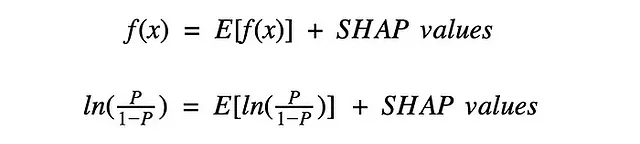
Per capire questo, immergiamoci in un plot SHAP. Iniziamo creando una variabile target binaria (riga 2). Creiamo due gruppi in base a y:
- 1 se l’abalone ha un numero di anelli superiore alla media
- 0 altrimenti
#Variabile target binariay_bin = [1 if y_>10 else 0 for y_ in y]Utilizziamo questa variabile target e le 8 caratteristiche per addestrare un classificatore XGBoost (righe 2-3). Questo modello aveva un’accuratezza del 96,6%.
#Addestramento del modello model_bin = xgb.XGBClassifier(objective="binary:logistic")model_bin.fit(X, y_bin)Ora calcoliamo i valori SHAP (righe 2-3). Stampiamo la forma di questo oggetto (riga 5) che restituisce (4177, 8). Quindi, proprio come per la variabile target continua, abbiamo un valore SHAP per ogni previsione e caratteristica. In seguito, vedremo come questo è diverso per una variabile target multiclasse.
#Otteniamo i valori SHAP
explainer = shap.Explainer(model_bin)
shap_values_bin = explainer(X)
print(shap_values_bin.shape) #output: (4177, 8)Visualizziamo un grafico waterfall per la prima istanza (riga 6). Possiamo vedere il risultato nella Figura 2. Notare che il codice è lo stesso per la variabile continua. A parte i numeri, il grafico waterfall ha un aspetto simile.
# grafico waterfall per la prima istanza
shap.plots.waterfall(shap_values_bin[0])Ora E[f(x)] = -0.789 rappresenta il valore medio dei log-odds predetti su tutti i 4.177 abaloni. Questo è il log-odds di una previsione positiva (1). Per questo specifico abalone, il modello ha previsto una probabilità di 0.3958 che avesse un numero di anelli superiore alla media (cioè P = 0.3958). Questo ci dà un log-odds predetto di f(x) = ln(0.3958/(1–0.3958)) = -0.423.
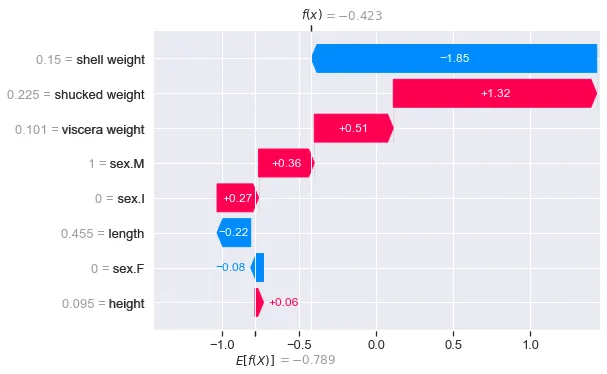
Quindi, i valori SHAP rappresentano la differenza tra i log-odds predetti e i log-odds medi predetti. I valori SHAP positivi aumentano i log-odds. Ad esempio, il peso sgusciato aumenta i log-odds di 1.32. In altre parole, questa caratteristica ha aumentato la probabilità che il modello preveda un numero di anelli superiore alla media. Allo stesso modo, i valori negativi diminuiscono i log-odds.
Possiamo anche aggregare questi valori nello stesso modo di prima. La buona notizia è che le interpretazioni dei grafici come beeswarm o mean SHAP saranno le stesse. Bisogna solo ricordare che stiamo lavorando con i log-odds. Ora vediamo come cambia questa interpretazione per le variabili target multiclasse.
Variabile target multiclasse
Iniziamo creando una nuova variabile target (y_cat) con 3 categorie: giovane (0), VoAGI (1) e vecchio (2). Come prima, addestriamo un classificatore XGBoost per prevedere questa variabile target (righe 5-6).
#Variabile target categoricay_cat = [2 if y_>12 else 1 if y_>8 else 0 for y_ in y]#Addestramento del modello
model_cat = xgb.XGBClassifier(objective="binary:logistic")
model_cat.fit(X, y_cat)Per questo modello, non possiamo più parlare di una “previsione positiva”. Possiamo vedere questo se otteniamo la probabilità prevista per la prima istanza (riga 2). Otteniamo [0.2562, 0.1571, 0.5866]. In questo caso, la terza probabilità è la più alta e quindi l’abalone viene predetto come vecchio (2). Ciò significa che per i valori SHAP non possiamo considerare solo i valori per la classe positiva.
# otteniamo le previsioni di probabilità
model_cat.predict_proba(X)[0]Possiamo vedere questo quando calcoliamo i valori SHAP (righe 2-3). Il codice è lo stesso del modello binario. Tuttavia, quando otteniamo la forma (riga 5) otteniamo (4177, 8, 3). Ora abbiamo un valore SHAP per ogni istanza, caratteristica e classe.
#Otteniamo i valori SHAP
explainer = shap.Explainer(model_cat)
shap_values_cat= explainer(X)
print(np.shape(shap_values_cat))Come risultato, dobbiamo visualizzare i valori SHAP per ogni classe in grafici waterfall separati. Facciamo questo per la prima istanza nel codice seguente.
# grafico waterfall per la classe 0
shap.plots.waterfall(shap_values_cat[0,:,0])# grafico waterfall per la classe 1
shap.plots.waterfall(shap_values_cat[0,:,1])# grafico waterfall per la classe 2
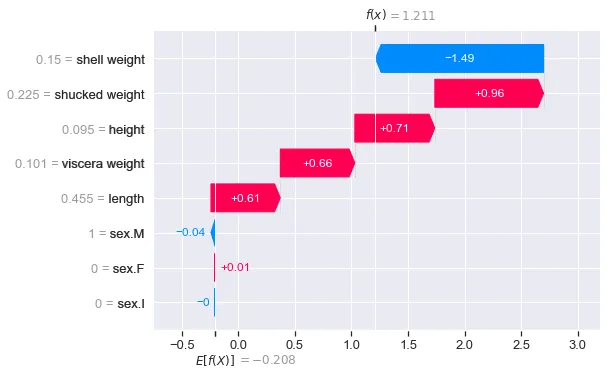
shap.plots.waterfall(shap_values_cat[0,:,2])La Figura 3 mostra il grafico waterfall per la classe 0. I valori spiegano come ogni caratteristica ha contribuito alla previsione del modello per questa classe, rispetto alla previsione media per questa classe. Abbiamo visto che la probabilità per questa classe era relativamente bassa (cioè 0.2562). Possiamo vedere che la caratteristica “peso sgusciato” ha dato il contributo più significativo a questa bassa probabilità.
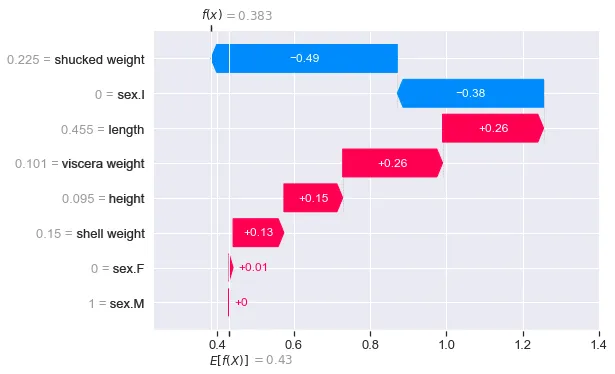
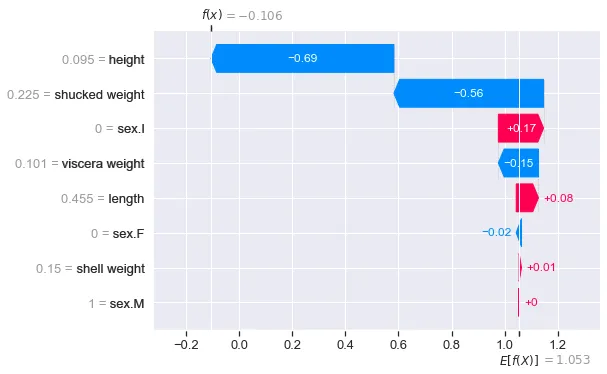
La figura 4 mostra l’output per le altre classi. Si noterà che f(x) = 1.211 è il valore più grande per la classe 2. Questo ha senso perché abbiamo visto che la probabilità per questa classe era anche la più grande (0.5866). Quando si analizzano i valori SHAP per questa istanza, può essere utile concentrarsi su questo grafico a cascata. È la previsione di classe per questa abalone.
Interpretare i valori con Softmax
Essendo ora alle prese con più classi, f(x) è espresso in termini di softmax. Possiamo convertire i valori softmax in probabilità utilizzando la seguente funzione. fx fornisce i tre valori di f(x) nei grafici a cascata sopra. Il risultato è [0.2562, 0.1571, 0.5866]. Le stesse probabilità predette che abbiamo visto per l’istanza 0!
def softmax(x): """Calcola i valori softmax per ogni insieme di punteggi in x""" e_x = np.exp(x - np.max(x)) return e_x / e_x.sum(axis=0)# convertire softmax in probabilitàfx = [0.383,-0.106,1.211]softmax(fx)Aggregazione dei valori SHAP multiclasse
Questi valori SHAP possono essere aggregati utilizzando uno qualsiasi dei grafici SHAP. Tuttavia, come nel caso del grafico a cascata, ci saranno grafici individuali per ogni classe. Analizzarli può essere tedioso, specialmente se si hanno molte categorie nella variabile target. Pertanto, concluderemo discutendo alcuni altri approcci di aggregazione.
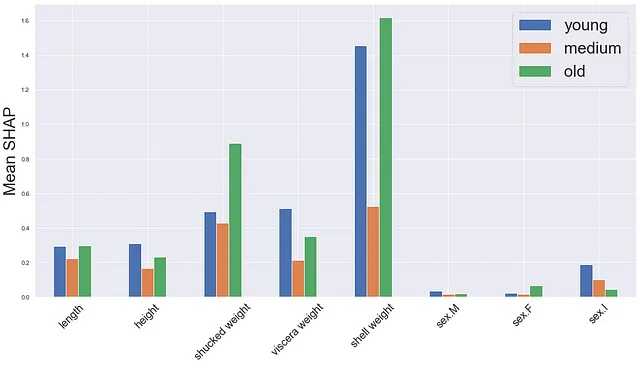
Il primo è una versione del grafico SHAP medio. Calcoliamo la media assoluta dei valori SHAP per ogni classe separatamente (linee 2-4). Quindi creiamo un grafico a barre con una barra per ogni classe e caratteristica.
# calcola i valori SHAP medi per ogni classemean_0 = np.mean(np.abs(shap_values_cat.values[:,:,0]),axis=0)mean_1 = np.mean(np.abs(shap_values_cat.values[:,:,1]),axis=0)mean_2 = np.mean(np.abs(shap_values_cat.values[:,:,2]),axis=0)df = pd.DataFrame({'small':mean_0,'VoAGI':mean_1,'large':mean_2})# mostra i valori SHAP medifig,ax = plt.subplots(1,1,figsize=(20,10))df.plot.bar(ax=ax)ax.set_ylabel('Media SHAP',size = 30)ax.set_xticklabels(X.columns,rotation=45,size=20)ax.legend(fontsize=30)Possiamo vedere l’output in Figura 5. Una cosa da menzionare è che ogni barra rappresenta la media su tutte le previsioni. Tuttavia, la classe prevista effettiva sarà diversa in ogni caso. Quindi, potresti finire per distorcere le medie con valori SHAP che non spiegano la classe prevista. Questo è potenzialmente il motivo per cui stiamo vedendo medie più basse per la classe VoAGI.
Per aggirare questo problema, possiamo concentrarci sui valori SHAP per la classe predetta. Iniziamo ottenendo la classe predetta per ogni istanza (riga 2). Creiamo un nuovo insieme di valori shap (new_shap_values). Questo viene fatto iterando sui valori originali e selezionando solo l’insieme corrispondente alla previsione per quella istanza (righe 5-7).
# ottenere le previsioni del modello
preds = model_cat.predict(X)
new_shap_values = []
for i, pred in enumerate(preds):
# ottenere i valori shap per la classe predetta
new_shap_values.append(shap_values_cat.values[i][:,pred])Poi sostituiamo i valori SHAP nell’oggetto originale (riga 2). Ora, se produciamo in output la forma, otteniamo (4177, 8). In altre parole, siamo tornati a un solo insieme di valori SHAP per istanza.
# sostituire i valori shap
shap_values_cat.values = np.array(new_shap_values)
print(shap_values_cat.shape)Un vantaggio di questo approccio è che è facile da utilizzare con i grafici SHAP incorporati. Ad esempio, il grafico SHAP medio nella Figura 6. Possiamo interpretare questi valori come il contributo medio di una caratteristica alla classe predetta.
shap.plots.bar(shap_values_cat)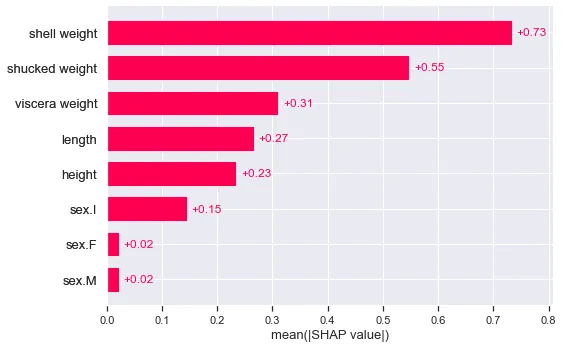
Possiamo anche utilizzare il grafico a dispersione (“beeswarm”). Tuttavia, notiamo che non vediamo una chiara relazione tra i valori SHAP e i valori della caratteristica. Questo perché le caratteristiche avranno diverse relazioni a seconda della classe predetta. Gli abalone più vecchi saranno più grandi. Quindi, ad esempio, i pesi delle conchiglie grandi porteranno a una maggiore probabilità di una previsione per un abalone vecchio (2). Il contrario è vero per le previsioni di abalone giovani (0).
shap.plots.beeswarm(shap_values_cat)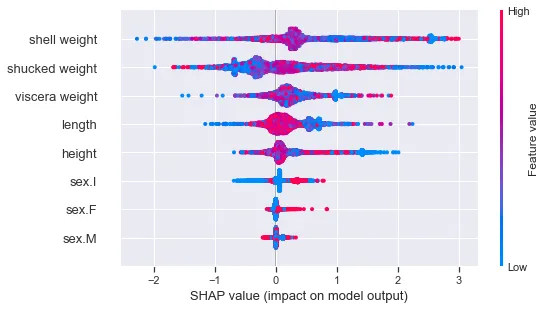
Quindi speriamo che sia chiaro come interpretare i valori SHAP per variabili target binarie e multiclass. Tuttavia, potresti chiederti perché vengono forniti in termini di log odds e softmax. Potrebbe avere più senso interpretarli entrambi in termini di probabilità.
Ciò deriva dal modo in cui vengono calcolati i valori SHAP. Cioè contemporaneamente da un modello lineare. Se dovessimo prevedere una variabile binaria o multiclasse con un modello lineare, useremmo rispettivamente una regressione logistica o softmax. Queste funzioni di collegamento sono differenziabili e ci permettono di formulare le previsioni del modello come un’equazione lineare di parametri e caratteristiche. Allo stesso modo, queste proprietà vengono utilizzate per stimare in modo efficiente i valori SHAP.
Per saperne di più su shap:
Nuovi grafici SHAP: Violino e Heatmap
Cosa possono dirti i grafici nella versione 0.42.1 di SHAP sul tuo modello
towardsdatascience.com
Limitazioni di SHAP
Come SHAP è influenzato dalle dipendenze tra le caratteristiche, dall’inferenza causale e dai pregiudizi umani
towardsdatascience.com
Utilizzo di SHAP per il debug di un modello di regressione di immagini PyTorch
Utilizzo di DeepShap per comprendere e migliorare il modello che alimenta un’auto autonoma
towardsdatascience.com
Spero che tu abbia apprezzato questo articolo! Puoi supportarmi diventando uno dei miei membri referenti 🙂
Unisciti a VoAGI con il mio link di referral — Conor O’Sullivan
Come membro di VoAGI, una parte della tua quota di iscrizione va agli scrittori che leggi e ottieni accesso completo ad ogni storia…
conorosullyds.medium.com
| Twitter | YouTube | Newsletter — iscriviti per accedere GRATUITAMENTE a un corso Python SHAP
Riferimenti
Stackoverflow Come interpretare il valore base di un problema di classificazione multi-classe quando si utilizza SHAP?https://stackoverflow.com/questions/65029216/how-to-interpret-base-value-of-multi-class-classification-problem-when-using-sha/65034362#65034362