Quantizza i modelli di Llama con GGML e llama.cpp
Quantizza i modelli di Llama con GGML e llama.cpp' -> 'Quantizza modelli Llama con GGML e llama.cpp
GGML vs. GPTQ vs. NF4

A causa delle dimensioni massive dei Large Language Models (LLM), la quantizzazione è diventata una tecnica essenziale per eseguirli in modo efficiente. Riducendo la precisione dei pesi, è possibile risparmiare memoria e accelerare l’elaborazione, preservando al contempo la maggior parte delle prestazioni del modello. Di recente, la quantizzazione a 8 bit e 4 bit ha aperto la possibilità di eseguire LLM su hardware per consumatori. Abbinata al rilascio dei modelli Llama e alle tecniche di ottimizzazione dei parametri (LoRA, QLoRA), ciò ha creato un ricco ecosistema di LLM locali che ora competono con GPT-3.5 e GPT-4 di OpenAI.
Oltre all’approccio ingenuo trattato in questo articolo, esistono tre tecniche principali di quantizzazione: NF4, GPTQ e GGML. NF4 è un metodo statico utilizzato da QLoRA per caricare un modello con precisione a 4 bit per eseguire l’ottimizzazione dei parametri. In un articolo precedente, abbiamo esplorato il metodo GPTQ e quantizzato il nostro modello per eseguirlo su una GPU per consumatori. In questo articolo, presenteremo la tecnica GGML, vedremo come quantizzare i modelli Llama e forniremo consigli e trucchi per ottenere i migliori risultati.
Puoi trovare il codice su Google Colab e GitHub.
Cos’è GGML?
GGML è una libreria C focalizzata sull’apprendimento automatico. È stata creata da Georgi Gerganov, dalle cui iniziali “GG” prende il nome. Questa libreria non fornisce solo elementi fondamentali per l’apprendimento automatico, come i tensori, ma anche un formato binario unico per distribuire LLM.
- Modelli di linguaggio e amici Gorilla, HuggingGPT, TaskMatrix e altro
- Analisi della complessità delle serie temporali utilizzando l’entropia
- Come progettare una roadmap per un progetto di Machine Learning
Questo formato è stato recentemente modificato in GGUF. Questo nuovo formato è progettato per essere estendibile, in modo che le nuove funzionalità non dovrebbero rompere la compatibilità con i modelli esistenti. Centralizza anche tutti i metadati in un unico file, come i token speciali, i parametri di scaling RoPE, ecc. In breve, risponde a alcuni problemi storici e dovrebbe essere a prova di futuro. Per ulteriori informazioni, puoi leggere le specifiche a questo indirizzo. Nel resto dell’articolo, chiameremo “modelli GGML” tutti i modelli che utilizzano GGUF o i formati precedenti.
GGML è stato progettato per essere utilizzato in combinazione con la libreria llama.cpp, anch’essa creata da Georgi Gerganov. La libreria è scritta in C/C++ per un’elaborazione efficiente dei modelli Llama. Può caricare i modelli GGML e eseguirli su una CPU. Originariamente, questa era la principale differenza rispetto ai modelli GPTQ, che vengono caricati ed eseguiti su una GPU. Tuttavia, ora è possibile spostare alcune parti del tuo LLM sulla GPU con llama.cpp. A titolo di esempio, ci sono 35 livelli per un modello con 7b di parametri. Ciò accelera notevolmente l’elaborazione e ti consente di eseguire LLM che non rientrano nella tua VRAM.
Se preferisci gli strumenti da riga di comando, llama.cpp e il supporto GGUF sono stati integrati in molte interfacce grafiche, come oobabooga’s text-generation-web-ui, koboldcpp, LM Studio o ctransformers. Puoi semplicemente caricare i tuoi modelli GGML con questi strumenti e interagire con essi in modo simile a ChatGPT. Fortunatamente, molti modelli quantizzati sono direttamente disponibili su Hugging Face Hub. Noterai rapidamente che la maggior parte di essi sono quantizzati da TheBloke, una figura popolare nella comunità LLM.
Nella sezione successiva, vedremo come quantizzare i nostri stessi modelli ed eseguirli su una GPU per consumatori.
Come quantizzare LLM con GGML?
Diamo uno sguardo ai file all’interno del repository TheBloke/Llama-2–13B-chat-GGML. Possiamo vedere 14 diversi modelli GGML, corrispondenti a diversi tipi di quantizzazione. Seguono una particolare convenzione di denominazione: “q” + il numero di bit utilizzati per archiviare i pesi (precisione) + una variante particolare. Ecco una lista di tutti i possibili metodi di quantizzazione e i relativi casi d’uso, basati su schede dei modelli realizzate da TheBloke:
q2_k: Utilizza Q4_K per i tensori attention.vw e feed_forward.w2, Q2_K per gli altri tensori.q3_k_l: Utilizza Q5_K per i tensori attention.wv, attention.wo e feed_forward.w2, altrimenti Q3_Kq3_k_m: Utilizza Q4_K per i tensori attention.wv, attention.wo e feed_forward.w2, altrimenti Q3_Kq3_k_s: Utilizza Q3_K per tutti i tensoriq4_0: Metodo di quantizzazione originale, 4-bit.q4_1: Maggiore precisione rispetto a q4_0 ma non così alta come q5_0. Tuttavia ha un’inferenza più rapida rispetto ai modelli q5.q4_k_m: Utilizza Q6_K per metà dei tensori attention.wv e feed_forward.w2, altrimenti Q4_Kq4_k_s: Utilizza Q4_K per tutti i tensoriq5_0: Maggiore precisione, utilizzo di risorse più elevato e inferenza più lenta.q5_1: Ancora maggiore precisione, utilizzo di risorse più elevato e inferenza più lenta.q5_k_m: Utilizza Q6_K per metà dei tensori attention.wv e feed_forward.w2, altrimenti Q5_Kq5_k_s: Utilizza Q5_K per tutti i tensoriq6_k: Utilizza Q8_K per tutti i tensoriq8_0: Quasi indistinguibile da float16. Utilizzo di risorse elevato e lento. Non raccomandato per la maggior parte degli utenti.
Come regola generale, raccomando di utilizzare Q5_K_M in quanto preserva la maggior parte delle prestazioni del modello. In alternativa, è possibile utilizzare Q4_K_M se si desidera risparmiare memoria. In generale, le versioni K_M sono migliori delle versioni K_S. Non posso raccomandare le versioni Q2 o Q3, in quanto diminuiscono drasticamente le prestazioni del modello.
Ora che sappiamo di più sui tipi di quantizzazione disponibili, vediamo come utilizzarli su un modello reale. È possibile eseguire il codice seguente su una GPU T4 gratuita su Google Colab. Il primo passo consiste nel compilare llama.cpp e installare le librerie necessarie nel nostro ambiente Python.
# Installa llama.cpp!git clone https://github.com/ggerganov/llama.cpp!cd llama.cpp && git pull && make clean && LLAMA_CUBLAS=1 make!pip install -r llama.cpp/requirements.txtOra possiamo scaricare il nostro modello. Utilizzeremo il modello che abbiamo messo a punto nell’articolo precedente, mlabonne/EvolCodeLlama-7b.
MODEL_ID = "mlabonne/EvolCodeLlama-7b"# Scarica il modello!git lfs install!git clone https://huggingface.co/{MODEL_ID}Questo passaggio potrebbe richiedere un po’ di tempo. Una volta completato, dobbiamo convertire i nostri pesi nel formato GGML FP16.
MODEL_NAME = MODEL_ID.split('/')[-1]GGML_VERSION = "gguf"# Converti in fp16fp16 = f"{MODEL_NAME}/{MODEL_NAME.lower()}.{GGML_VERSION}.fp16.bin"!python llama.cpp/convert.py {MODEL_NAME} --outtype f16 --outfile {fp16}Infine, possiamo quantizzare il modello utilizzando uno o più metodi. In questo caso, utilizzeremo i metodi Q4_K_M e Q5_K_M che ho raccomandato in precedenza. Questo è l’unico passaggio che richiede effettivamente una GPU.
QUANTIZATION_METHODS = ["q4_k_m", "q5_k_m"]for method in QUANTIZATION_METHODS: qtype = f"{MODEL_NAME}/{MODEL_NAME.lower()}.{GGML_VERSION}.{method}.bin" !./llama.cpp/quantize {fp16} {qtype} {method}I nostri due modelli quantizzati sono ora pronti per l’inferenza. Possiamo verificare la dimensione dei file bin per vedere quanto li abbiamo compressi. Il modello FP16 occupa 13.5 GB, mentre il modello Q4_K_M occupa 4.08 GB (3.3 volte più piccolo) e il modello Q5_K_M occupa 4.78 GB (2.8 volte più piccolo).
Utilizziamo llama.cpp per eseguirli in modo efficiente. Poiché stiamo utilizzando una GPU con 16 GB di VRAM, possiamo spostare ogni layer sulla GPU. In questo caso, rappresenta 35 layer (modello con 7 miliardi di parametri), quindi useremo il parametro -ngl 35. Nel blocco di codice seguente, inseriremo anche un prompt e il metodo di quantizzazione che vogliamo utilizzare.
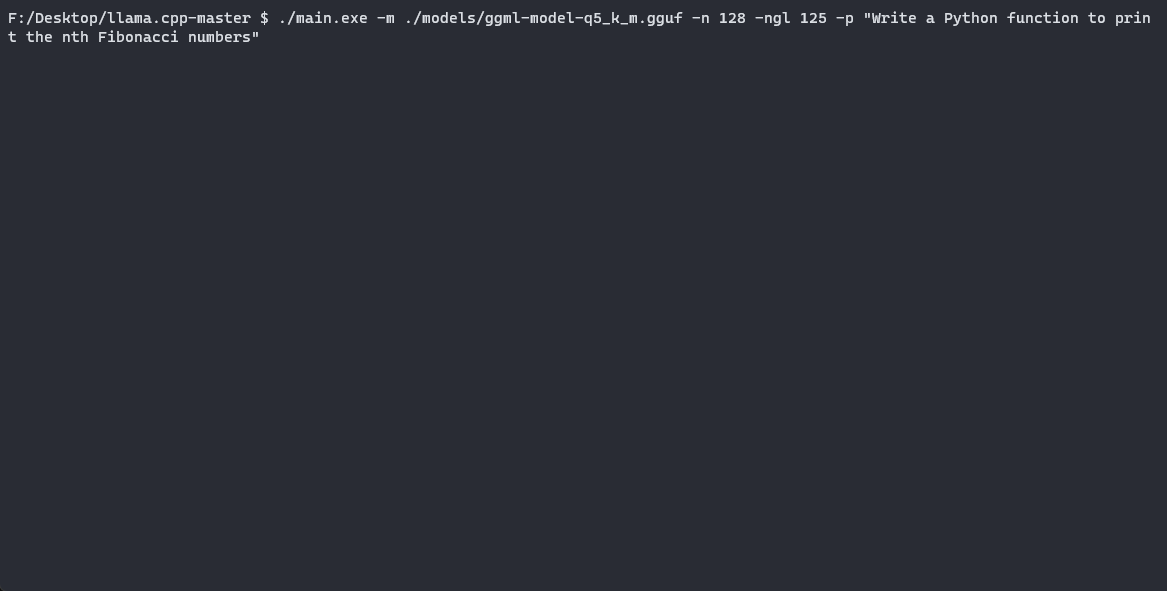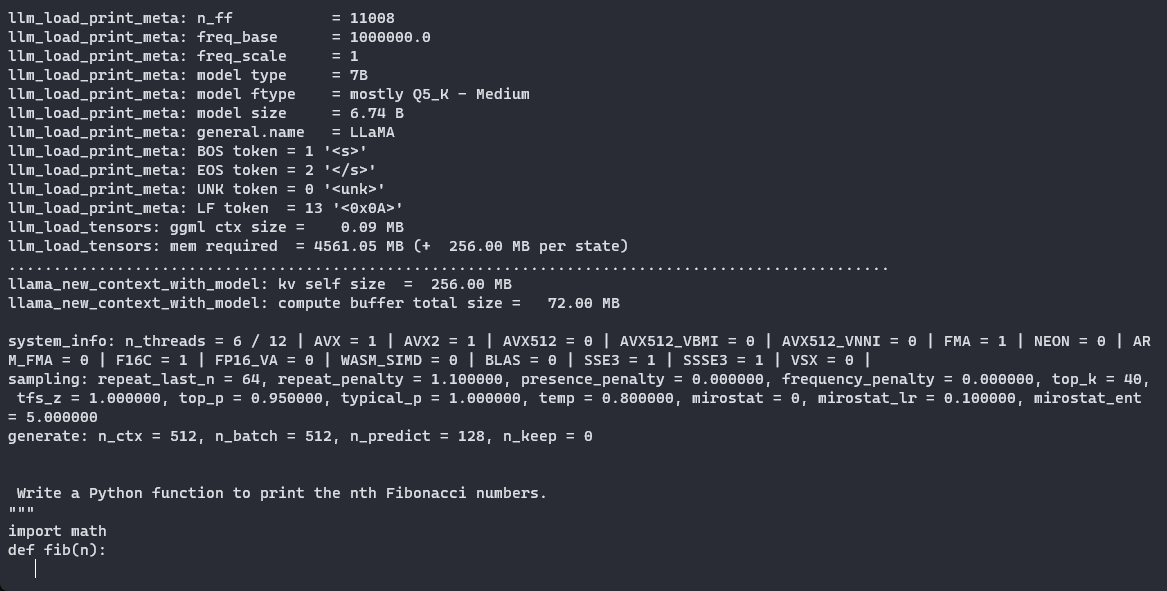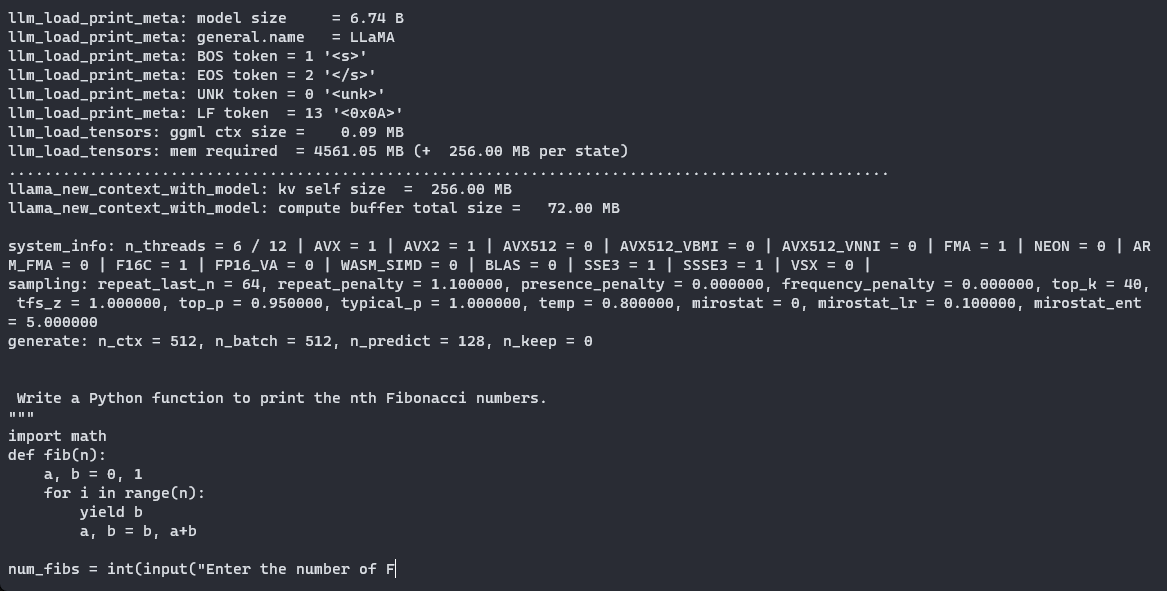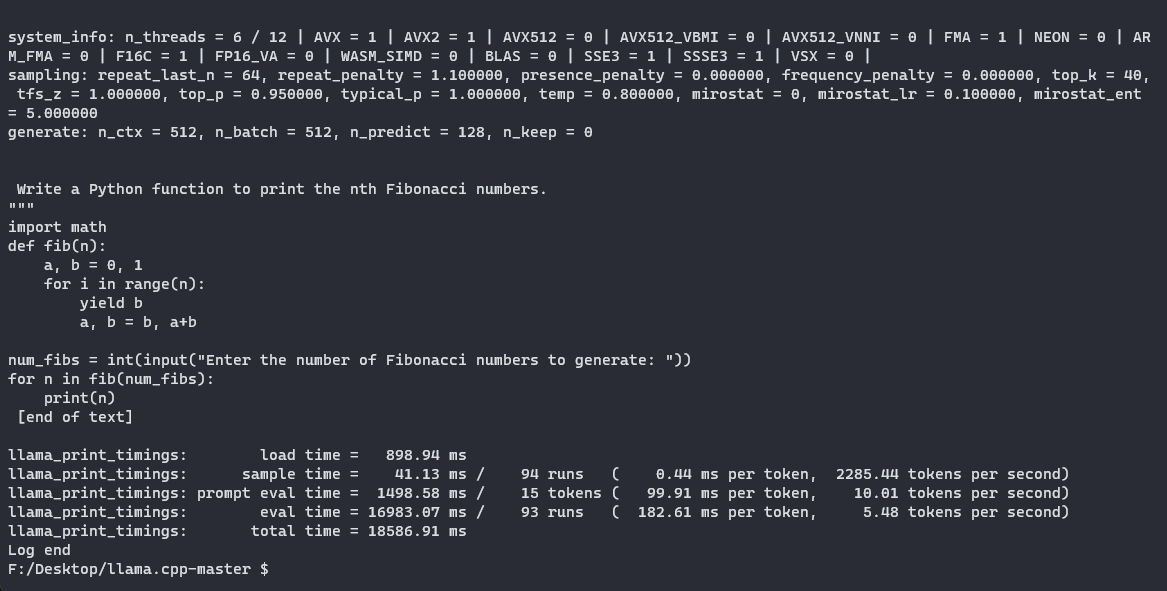
import osmodel_list = [file for file in os.listdir(MODEL_NAME) if GGML_VERSION in file]prompt = input("Inserisci il tuo prompt: ")chosen_method = input("Specificare il metodo di quantizzazione da utilizzare per eseguire il modello (opzioni: " + ", ".join(model_list) + "): ")# Verifica che il metodo scelto sia presente nella listaif chosen_method not in model_list: print("Metodo scelto non valido!")else: qtype = f"{MODEL_NAME}/{MODEL_NAME.lower()}.{GGML_VERSION}.{method}.bin" !./llama.cpp/main -m {qtype} -n 128 --color -ngl 35 -p "{prompt}"Chiediamo al modello di “Scrivere una funzione Python per stampare i numeri di Fibonacci in posizione n” utilizzando il metodo Q5_K_M. Se guardiamo i log, possiamo confermare che abbiamo spostato con successo i nostri layer grazie alla riga “llm_load_tensors: spostati 35/35 layer sulla GPU”. Ecco il codice generato dal modello:
def fib(n): if n == 0 or n == 1: return n return fib(n - 2) + fib(n - 1)for i in range(1, 10): print(fib(i))Non si trattava di un prompt molto complesso, ma ha prodotto con successo un pezzo di codice funzionante in poco tempo. Con questa GGML, è possibile utilizzare il proprio LLM locale come assistente in un terminale utilizzando la modalità interattiva (-i). Nota che ciò funziona anche su MacBook con Metal Performance Shaders (MPS) di Apple, che è un’ottima opzione per eseguire LLM.
Infine, possiamo caricare il nostro modello quantizzato in un nuovo repository su Hugging Face Hub con il suffisso “-GGUF”. Prima, effettuiamo l’accesso e modifichiamo il blocco di codice seguente per corrispondere al tuo nome utente.
!pip install -q huggingface_hubusername = "mlabonne"from huggingface_hub import notebook_login, create_repo, HfApinotebook_login()Ora possiamo creare il repository e caricare i nostri modelli. Utilizziamo il parametro allow_patterns per filtrare i file da caricare, in modo da non caricare l’intera directory.
api = HfApi()# Creazione del repositorycreate_repo( repo_id=f"{username}/{MODEL_NAME}-GGML", repo_type="model", exist_ok=True)# Caricamento dei modelli binapi.upload_folder( folder_path=MODEL_NAME, repo_id=f"{username}/{MODEL_NAME}-GGML", allow_patterns=f"*{GGML_VERSION}*",)Abbiamo quantizzato, eseguito e caricato modelli GGML con successo su Hugging Face Hub! Nella prossima sezione, esploreremo come GGML effettivamente quantizza questi modelli.
Quantizzazione con GGML
Il modo in cui GGML quantizza i pesi non è sofisticato come quello di GPTQ. Fondamentalmente, raggruppa blocchi di valori e li arrotonda a una precisione inferiore. Alcune tecniche, come Q4_K_M e Q5_K_M, implementano una precisione superiore per i layer critici. In questo caso, ogni peso viene memorizzato con una precisione di 4 bit, ad eccezione della metà dei tensori attention.wv e feed_forward.w2. Sperimentalmente, questa precisione mista si dimostra un buon compromesso tra precisione e utilizzo delle risorse.
Se guardiamo nel file ggml.c, possiamo vedere come vengono definiti i blocchi. Ad esempio, la struttura block_q4_0 è definita come:
#define QK4_0 32typedef struct { ggml_fp16_t d; // delta uint8_t qs[QK4_0 / 2]; // nibbles / quants} block_q4_0;In GGML, i pesi vengono elaborati in blocchi, ciascuno composto da 32 valori. Per ogni blocco, viene derivato un fattore di scala (delta) dal valore di peso più grande. Tutti i pesi nel blocco vengono quindi scalati, quantizzati e confezionati in modo efficiente per la memorizzazione (nibbles). Questo approccio riduce significativamente i requisiti di memoria consentendo al contempo una conversione relativamente semplice e deterministica tra i pesi originali e quelli quantizzati.
Ora che sappiamo di più sul processo di quantizzazione, possiamo confrontare i risultati con NF4 e GPTQ.
NF4 vs. GGML vs. GPTQ
Quali tecniche sono migliori per la quantizzazione a 4 bit? Per rispondere a questa domanda, dobbiamo introdurre i diversi backend che eseguono questi LLMs quantizzati. Per i modelli GGML, llama.cpp con i modelli Q4_K_M è la scelta giusta. Per i modelli GPTQ, abbiamo due opzioni: AutoGPTQ o ExLlama. Infine, i modelli NF4 possono essere eseguiti direttamente in transformers con il flag --load-in-4bit.
Oobabooga ha eseguito più esperimenti in un eccellente articolo sul blog che confronta diversi modelli in termini di perplessità (più bassa è meglio):

Sulla base di questi risultati, possiamo dire che i modelli GGML hanno un leggero vantaggio in termini di perplessità. La differenza non è particolarmente significativa, ecco perché è meglio concentrarsi sulla velocità di generazione in termini di token/secondo. La migliore tecnica dipende dalla tua GPU: se hai abbastanza VRAM per adattare l’intero modello quantizzato, GPTQ con ExLlama sarà il più veloce. Se non è il caso, puoi spostare alcuni strati e utilizzare i modelli GGML con llama.cpp per eseguire il tuo LLM.
Conclusioni
In questo articolo, abbiamo introdotto la libreria GGML e il nuovo formato GGUF per archiviare efficientemente questi modelli quantizzati. Lo abbiamo utilizzato per quantizzare il nostro modello Llama in diversi formati (Q4_K_M e Q5_K_M). Abbiamo poi eseguito il modello GGML e caricato i nostri file bin su Hugging Face Hub. Infine, abbiamo approfondito il codice di GGML per capire come quantizza effettivamente i pesi e lo abbiamo confrontato con NF4 e GPTQ.
La quantizzazione è un vettore formidabile per democratizzare i LLM abbassando il costo di esecuzione. In futuro, la precisione mista e altre tecniche continueranno a migliorare le prestazioni che possiamo ottenere con pesi quantizzati. Fino ad allora, spero che tu abbia apprezzato la lettura di questo articolo e abbia imparato qualcosa di nuovo.
Se sei interessato a contenuti tecnici sui LLM, seguimi su VoAGI.
Articoli sulla quantizzazione
Parte 1: Introduzione alla quantizzazione dei pesi
Riduzione delle dimensioni dei modelli di linguaggio di grandi dimensioni con quantizzazione a 8 bit
towardsdatascience.com
Parte 2: Quantizzazione a 4 bit con GPTQ
Quantizza i tuoi LLM personali utilizzando AutoGPTQ
towardsdatascience.com
Scopri di più sul machine learning e supporta il mio lavoro con un solo click – diventa un membro di VoAGI qui:
Unisciti a VoAGI con il mio link di riferimento – Maxime Labonne
Come membro di VoAGI, una parte della tua quota di iscrizione va agli scrittori che leggi e hai accesso completo ad ogni storia…
VoAGI.com