Ricercatori di Intelligenza Artificiale (IA) dell’Università di Cornell propongono un nuovo framework di rete neurale per affrontare il problema del video matting
Ricercatori di IA dell'Università di Cornell propongono framework per il video matting.


La modifica di immagini e video sono due delle applicazioni più popolari per gli utenti di computer. Con l’avvento dell’Apprendimento Automatico (ML) e dell’Apprendimento Profondo (DL), la modifica di immagini e video è stata progressivamente studiata attraverso diverse architetture di reti neurali. Fino a molto recentemente, la maggior parte dei modelli DL per la modifica di immagini e video erano supervisionati e, più specificamente, richiedevano che i dati di addestramento contenessero coppie di dati di input e output da utilizzare per apprendere i dettagli della trasformazione desiderata. Di recente, sono stati proposti framework di apprendimento end-to-end, che richiedono come input solo un’immagine singola per apprendere la mappatura verso l’output modificato desiderato.
Il “matting” video è una specifica attività appartenente alla modifica video. Il termine “matting” risale al XIX secolo quando lastre di vetro di vernice opaca venivano posizionate davanti a una telecamera durante le riprese per creare l’illusione di un ambiente che non era presente nella location delle riprese. Oggi, la composizione di più immagini digitali segue procedimenti simili. Una formula composita viene sfruttata per sfumare l’intensità del primo piano e dello sfondo di ciascuna immagine, espressa come una combinazione lineare dei due componenti.
Anche se molto potente, questo processo ha alcune limitazioni. Richiede una fattorizzazione inequivocabile dell’immagine in strati di primo piano e sfondo, che vengono quindi considerati trattabili in modo indipendente. In alcune situazioni come il matting video, quindi una sequenza di frame temporali e spaziali dipendenti, la decomposizione degli strati diventa un compito complesso.
- Cosa significa distribuire un modello di Machine Learning?
- Traduzione immagine-immagine basata su schizzi trasformazione di schizzi astratti in immagini fotorealistiche con GANs
- Migliori strumenti di controllo delle versioni dei dati per la ricerca di apprendimento automatico nel 2023
Gli obiettivi di questo articolo sono l’illuminazione di questo processo e l’aumento dell’accuratezza della decomposizione. Gli autori propongono il factor matting, una variante del problema del matting che scompone il video in componenti più indipendenti per attività di modifica successive. Per affrontare questo problema, presentano FactorMatte, un framework facile da usare che combina prior di matting classici con prior condizionali basate su deformazioni attese in una scena. La formulazione classica di Bayes, ad esempio, riferendosi all’estimazione della massima probabilità a posteriori, viene estesa per rimuovere l’assunzione limitante sull’indipendenza del primo piano e dello sfondo. La maggior parte degli approcci inoltre assume che gli strati di sfondo rimangano statici nel tempo, il che è limitante per la maggior parte delle sequenze video.
Per superare queste limitazioni, FactorMatte si basa su due moduli: una rete di decomposizione che scompone il video in uno o più strati per ciascun componente e un insieme di discriminatori basati su patch che rappresentano prior condizionali su ciascun componente. Il flusso di architettura è raffigurato di seguito.
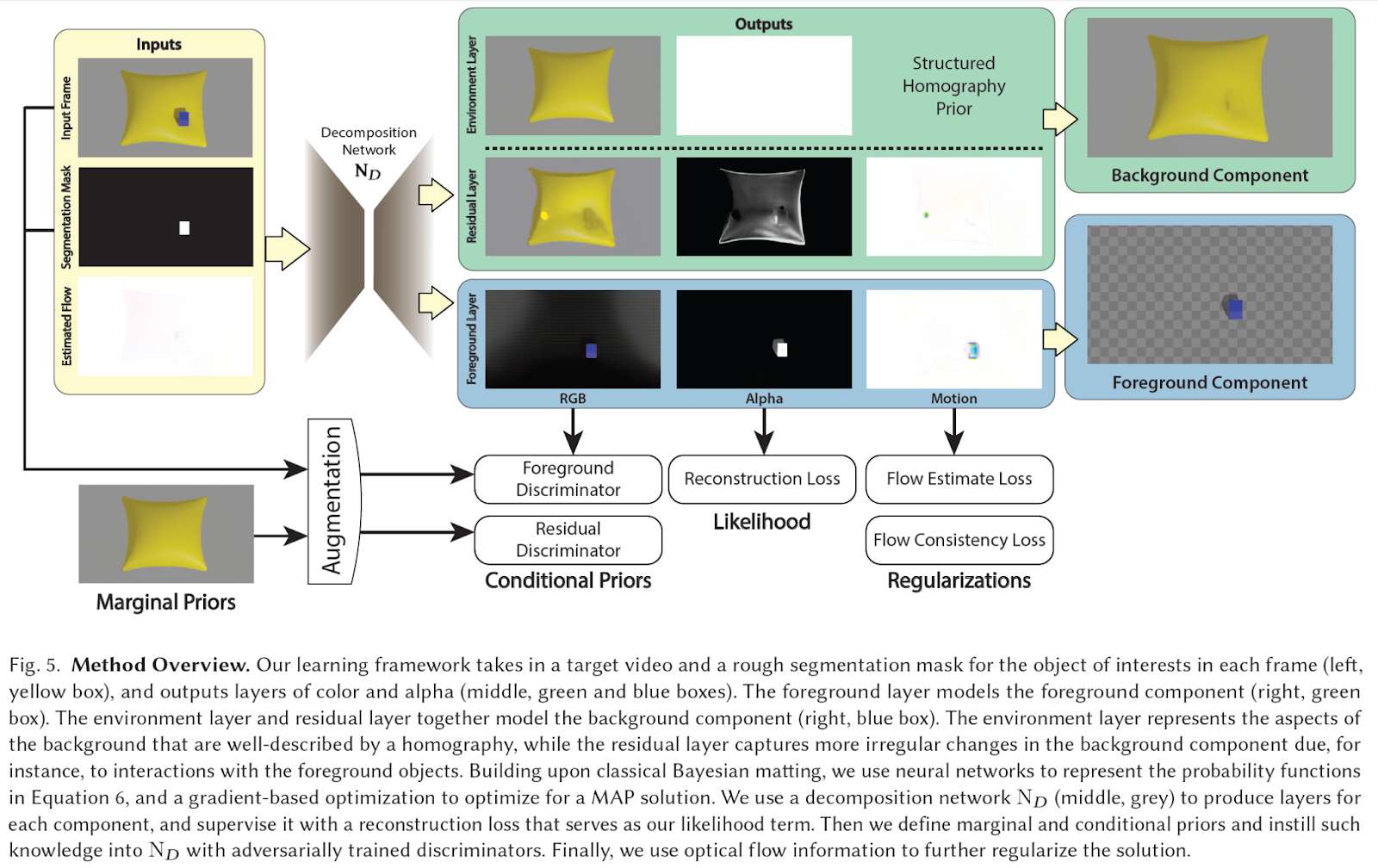
L’input alla rete di decomposizione è composto da un video e una maschera di segmentazione approssimativa per l’oggetto di interesse frame per frame (a sinistra, riquadro giallo). Con queste informazioni, la rete produce strati di colore e alfa (a sinistra, riquadri verdi e blu) basati su una perdita di ricostruzione. Lo strato del primo piano modella il componente del primo piano (a destra, riquadro verde), mentre lo strato dell’ambiente e lo strato residuo insieme modellano il componente dello sfondo (a destra, riquadro blu). Lo strato dell’ambiente rappresenta gli aspetti simili a statici dello sfondo, mentre lo strato residuo cattura cambiamenti più irregolari nel componente dello sfondo dovuti alle interazioni con gli oggetti del primo piano (la deformazione del cuscino nella figura). Per ciascuno di questi strati, è stato allenato un discriminatore per apprendere le rispettive prior marginali.
L’esito del matting per alcuni campioni selezionati è presentato nella figura seguente.

Anche se FactorMatte non è perfetto, i risultati prodotti sono chiaramente più accurati rispetto all’approccio di base (OmniMatte). In tutti gli esempi forniti, gli strati di sfondo e primo piano presentano una separazione netta tra di loro, cosa che non può essere affermata per la soluzione confrontata. Inoltre, sono state condotte ulteriori analisi per dimostrare l’efficacia della soluzione proposta.
Questo è stato il riassunto di FactorMatte, un nuovo framework per affrontare il problema del video matting. Se sei interessato, puoi trovare ulteriori informazioni ai seguenti link.






