Traduzione immagine-immagine basata su schizzi trasformazione di schizzi astratti in immagini fotorealistiche con GANs
Traduzione immagine-immagine con GANs trasformazione di schizzi astratti in immagini fotorealistiche


Alcune persone sono abili nel disegno a mano libera, mentre altre possono essere talentuose in altre attività. Quando si presenta loro un’immagine di una scarpa, le persone possono tracciare linee semplici per rappresentare la foto, ma la qualità dei disegni può variare. Al contrario, gli esseri umani hanno la capacità intrinseca di visualizzare un’immagine realistica basata anche su un disegno astratto, una competenza sviluppata in milioni di anni di evoluzione.
Con l’avvento dell’IA e dei modelli generativi, generare un’immagine fotorealistica da disegni astratti rientra nel contesto più ampio della letteratura sulla traduzione da immagine a immagine. Questo problema è stato esplorato in lavori precedenti come pix2pix, CycleGAN, MUNIT e BicycleGAN. Alcuni di questi approcci precedenti, comprese le varianti specifiche per i disegni a mano libera, hanno affermato di affrontare problemi simili generando edgemap fotografici, che evidenziano i contorni e i contorni significativi degli oggetti in un disegno. Queste edgemap sono immagini dettagliate, il che implica che questi modelli non considerano disegni astratti ma si concentrano su quelli raffinati.
L’articolo presentato in questo articolo si concentra sulla traduzione da immagine a immagine basata su disegni a mano libera ma con una distinzione cruciale dagli approcci citati. Si concentra sulla generazione di immagini direttamente da disegni astratti umani anziché utilizzare edgemap fotografiche. Secondo gli autori, i modelli addestrati con edgemap producono foto fotorealistiche di alta qualità con edgemap, ma risultati irrealistici con disegni a mano libera amatoriali. Questo risultato è dovuto al fatto che tutti gli approcci precedenti assumono un allineamento dei pixel durante la traduzione. Di conseguenza, i risultati generati riflettono accuratamente la capacità di disegno (o la mancanza di essa) dell’individuo, portando a risultati scadenti per i non artisti.
- Migliori strumenti di controllo delle versioni dei dati per la ricerca di apprendimento automatico nel 2023
- Incontra FathomNet un database di immagini open-source che utilizza algoritmi di intelligenza artificiale e apprendimento automatico per aiutare a elaborare il backlog di dati visivi per la comprensione del nostro oceano e dei suoi abitanti.
- I ricercatori presso l’Università di Michigan State hanno sviluppato ‘DANCE’, una libreria Python per supportare modelli di apprendimento profondo per l’analisi dell’espressione genica a livello di singola cellula su larga scala.
Di conseguenza, un artista non addestrato non otterrà mai un risultato soddisfacente con questi modelli. Tuttavia, il nuovo approccio di intelligenza artificiale presentato in questo articolo cerca di democratizzare la tecnologia di generazione di foto da disegno a mano libera.
La sua architettura è presentata nella figura qui sotto.
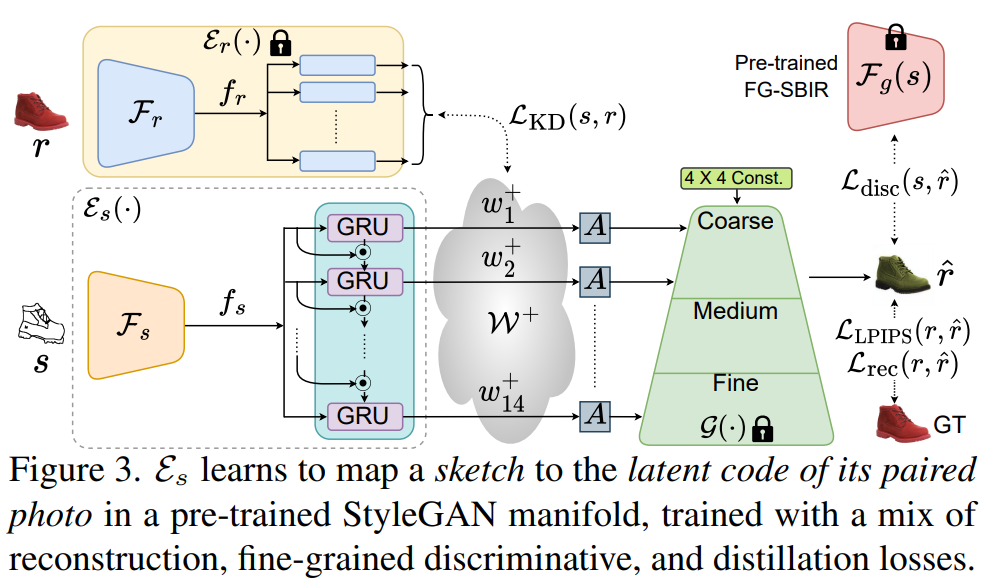
Questa tecnica consente la generazione di un’immagine fotorealistica da un disegno astratto indipendentemente dalla qualità del disegno. Gli autori hanno scoperto che l’artefatto dell’allineamento dei pixel presentato negli approcci precedenti derivava dall’addestramento dell’architettura encoder-decoder da un’estremità all’altra. Ciò ha causato la restrizione dei risultati generati ai confini definiti nel disegno di input (edgemap), limitando la qualità dei risultati. Per affrontare questo problema, hanno introdotto un metodo di addestramento encoder-decoder decoupled. I ricercatori hanno preaddestrato il decoder utilizzando StyleGAN esclusivamente su foto e successivamente lo hanno congelato. Ciò ha garantito che i risultati generati fossero di qualità fotorealistica, campionati dal manifold di StyleGAN.
Un altro aspetto importante è il divario tra disegni astratti e foto realistiche. Per superare questo problema, hanno addestrato un encoder a mappare le rappresentazioni di disegni astratti nello spazio latente di StyleGAN, anziché le foto effettive come di consueto. Hanno utilizzato coppie di esempi di disegni a mano libera e foto di riferimento e hanno imposto una nuova loss discriminativa dettagliata tra il disegno di input e la foto generata, insieme a una loss di ricostruzione convenzionale, per garantire un mappaggio accurato. Inoltre, hanno introdotto una strategia di augmentazione parziale consapevole per gestire la natura astratta dei disegni a mano libera. Ciò ha comportato la creazione di versioni parziali di un disegno completo e l’allocazione appropriata di vettori latenti in base al livello di informazione parziale.
Dopo aver addestrato il loro modello generativo, i ricercatori hanno osservato diverse proprietà interessanti. Hanno scoperto che il livello di astrazione nella foto generata poteva essere facilmente controllato regolando il numero di vettori latenti previsti e aggiungendo rumore gaussiano. Il modello ha anche mostrato una robustezza nei confronti di disegni a mano libera rumorosi e parziali grazie alla strategia di augmentazione parziale consapevole del disegno a mano libera. Inoltre, il modello ha dimostrato una buona generalizzazione a diversi livelli di astrazione dei disegni di input.
Un insieme di risultati per l’approccio proposto e le tecniche all’avanguardia viene riportato di seguito.

Questo è stato il riassunto di un nuovo modello di intelligenza artificiale generativa per generare immagini fotorealistiche da schizzi astratti di persone. Se sei interessato e vuoi saperne di più su questo lavoro, puoi trovare ulteriori informazioni cliccando sui link sottostanti.






