Rete neurale ricorrente a cancelli da zero in Julia
Rete neurale ricorrente a cancelli da zero in Julia' can be condensed to 'Rete neurale ricorrente in Julia'.
Esploriamo Julia per costruire una RNN con celle GRU da zero
1. Introduzione
Tempo fa ho iniziato a imparare Julia per la programmazione scientifica e la scienza dei dati. L’adozione continua di Julia deriva dalla combinazione della potenza statistica di R, la sintassi espressiva e chiara di Python e l’alto rendimento dei linguaggi compilati come C++.
Il modo migliore per imparare qualcosa è praticarlo costantemente. Questa “semplice” ricetta è evidentemente efficace nel campo tecnologico. Solo attraverso la scrittura del codice e la pratica un programmatore può comprendere e esplorare la sintassi, i tipi di dati, le funzioni, i metodi, le variabili, la gestione della memoria, il flusso di controllo, la gestione degli errori e le librerie, comprese le migliori pratiche e le convenzioni.
Strettamente legato a questa convinzione, ho avviato un progetto personale per costruire una Rete Neurale Ricorrente (RNN) che utilizza l’architettura Gated Recurrent Units (GRU) allo stato dell’arte. Per aggiungere un po’ di sapore in più e aumentare la mia comprensione di Julia, ho costruito questa RNN da zero. L’idea era quella di utilizzare la RNN con GRU per la previsione delle serie temporali legate al mercato azionario.
Algoritmo di Clustering basato sulla Densità da Zero in Julia
Programmiamo in Julia come alternativa a Python nella scienza dei dati
pub.towardsai.net
- I ricercatori dell’Università della Pennsylvania hanno introdotto un approccio alternativo di intelligenza artificiale per progettare e programmare i computer serbatoio basati su RNN.
- 8 Ragioni per cui non ho rinunciato al mio sogno di diventare un Data Scientist e perché nemmeno tu dovresti farlo
- 10 migliori strumenti di cambiamento vocale AI (luglio 2023)
Il programma di questo post sarà il seguente:
- Comprensione dell’architettura GRU
- Preparazione del progetto
- Implementazione della rete GRU
- Risultati e approfondimenti
- Conclusione
Inizia, fork, condividi e soprattutto sperimenta il repository GitHub creato per questo progetto 👇.
GitHub – jodhernandezbe/post-gru-julia: Questo è un repository contenente codici Julia per creare da…
Questo è un repository contenente codici Julia per creare da zero una Rete Neurale Ricorrente Gated per le azioni…
github.com
2. Comprensione dell’architettura GRU
L’idea di questa sezione non è quella di dare una descrizione estesa dell’architettura GRU, ma di presentare gli elementi necessari per programmare una RNN con celle GRU da zero. Ai neofiti posso dire che le RNN appartengono a una famiglia di modelli che consentono di gestire dati sequenziali come testo, prezzi delle azioni e dati dei sensori.
Svelare il Modello Markov Nascosto: Concetti, Matematica e Applicazioni nella Vita Reale
Esploriamo la Catena di Markov Nascosta
VoAGI.com
L’idea delle GRU è superare il problema del gradiente che scompare delle RNN vanilla. L’articolo scritto da Chi-Feng Wang può fornirti una spiegazione semplice di questo problema 👇. Nel caso in cui tu voglia approfondire la GRU, ti incoraggio a leggere i seguenti paper open-source e di facile lettura:
- Sulle proprietà della traduzione automatica neurale: approcci Codificatore-Decodificatore
- Valutazione empirica delle Reti Neurali Ricorrenti Gated nella modellazione di sequenze
Il Problema del Gradiente che Scompare
Il Problema, le Sue Cause, la Sua Importanza e le Sue Soluzioni
towardsdatascience.com
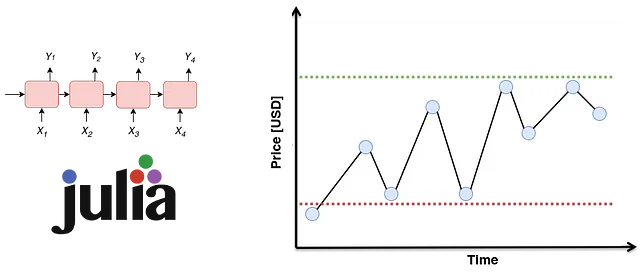
Questo articolo implementa una RNN che non è né profonda né bidirezionale. Le funzioni integrate in Julia devono essere in grado di catturare questo comportamento. Come illustrato nella Figura 1, una RNN con celle GRU consiste in una serie di fasi sequenziali. Ad ogni fase t, fornisce un elemento corrispondente allo stato nascosto della fase immediatamente precedente (hₜ₋₁). Allo stesso modo, un elemento rappresenta l’elemento tᵗʰ di una sequenza di campioni (ad esempio, xₜ). L’output di ogni cella GRU corrisponde allo stato nascosto di quel passo temporale che verrà alimentato alla fase successiva (ad esempio, hₜ). Inoltre, hₜ può essere passato attraverso una funzione come Softmax per ottenere l’output desiderato (ad esempio, se una parola in un testo è un aggettivo).
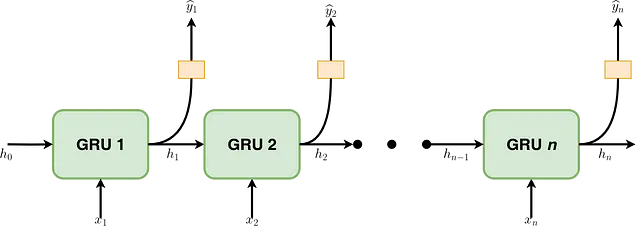
La Figura 2 mostra come una cella GRU è formata e come avvengono il flusso di informazioni e le operazioni matematiche al suo interno. La cella al passo temporale t contiene un gate di aggiornamento (zₜ) per determinare quale porzione delle informazioni precedenti verrà trasmessa al passo successivo e un gate di reset (rₜ) per determinare quale porzione delle informazioni precedenti deve essere dimenticata. Con rₜ, hₜ₋₁ e xₜ, viene calcolato uno stato nascosto candidato (ĥₜ) per il passo corrente. Successivamente, utilizzando zₜ, hₜ₋₁ e ĥₜ, viene calcolato lo stato nascosto effettivo (hₜ₋₁). Tutte queste operazioni costituiscono il passaggio in avanti in una cella GRU e sono riassunte nelle equazioni presentate nella Figura 3, dove Wᵣₕ, Wᵣₓ, Wₕₕ, Wₕₓ, W₂ₓ, W₂ₕ, bᵣ, bₕ e b₂ sono i parametri apprendibili. Il simbolo ” * ” indica la moltiplicazione tra matrici, mentre “・” indica la moltiplicazione elemento per elemento.
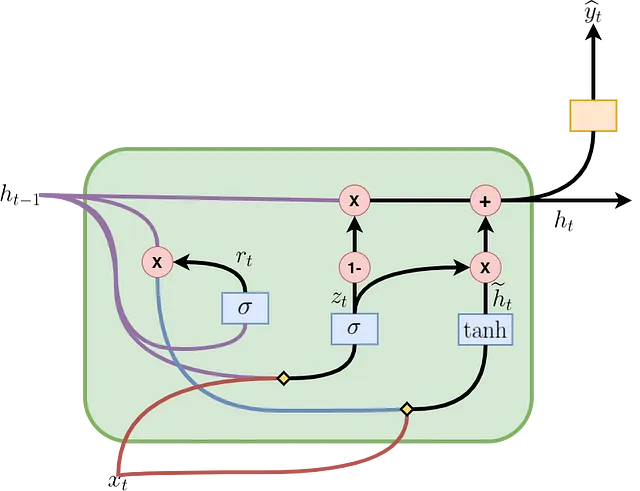
Nella letteratura, è comune trovare le equazioni del passaggio in avanti come mostrato nella Figura 4. In questa figura, la concatenazione di matrici viene utilizzata per abbreviare le espressioni presentate nella Figura 3. Wᵣ, Wₕ e W₂ sono le concatenazioni verticali tra Wᵣₕ e Wᵣₓ, Wₕₕ e Wₕₓ e W₂ₓ e W₂ₕ, rispettivamente. Le parentesi quadre indicano che gli elementi contenuti al loro interno sono concatenati orizzontalmente. Entrambe le rappresentazioni sono utili, quella nella Figura 4 è utile per abbreviare le formule e quella nella Figura 3 è utile per comprendere le equazioni di backpropagation.
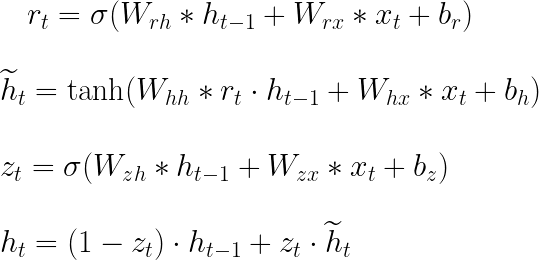
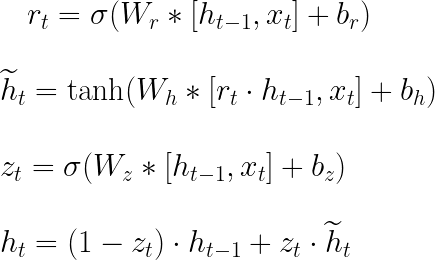
La Figura 4 mostra le equazioni di backpropagation che devono essere incluse nel programma Julia per l’addestramento del modello. Nelle equazioni, ” T ” indica la trasposizione delle matrici. Possiamo ottenere queste equazioni utilizzando la definizione della derivata totale per una funzione multivariabile e la regola della catena. Inoltre, puoi guidarti utilizzando un approccio grafico 👇:
Forward e Backpropagation in GRU – Derivati | Deep Learning
Una spiegazione delle unità ricorrenti con porta (GRU) con la matematica di come la perdita si propaga all’indietro nel tempo.
VoAGI.com
Unità GRU
Per eseguire la BPTT con un’unità GRU, abbiamo l’errore proveniente dallo strato superiore (\(\delta 1\)), lo stato nascosto futuro…
cran.r-project.org

3. Preparazione del progetto
Per eseguire il progetto, installa Julia sul tuo computer seguendo le istruzioni nella documentazione:
Istruzioni specifiche per la piattaforma per binari ufficiali
Il sito web ufficiale per il linguaggio Julia. Julia è un linguaggio veloce, dinamico, facile da usare e open source…
julialang.org
Come Python, puoi utilizzare Jupyter Notebooks con kernel Julia. Se desideri farlo, dai un’occhiata al seguente post scritto dal Dr. Martin McGovern, PhD FIA:
Come utilizzare al meglio Julia con Jupyter
Come aggiungere il codice Julia ai tuoi notebook Jupyter e abilitare l’uso simultaneo di Python e Julia nello stesso…
towardsdatascience.com
3.1. Struttura del progetto
Il progetto all’interno del repository GitHub ha la seguente struttura ad albero:
.├── data│ ├── AAPL.csv│ ├── GOOG.csv│ └── IBM.csv├── plots│ ├── residual_plot.png│ └── sequence_plot.png├── Project.toml├── .pre-commit-config.yaml├── src│ ├── data_preprocessing.jl│ ├── main.jl│ ├── prediction_plots.jl│ └── scratch_gru.jl└── tests (unit testing) ├── test_data_preprocessing.jl ├── test_main.jl └── test_scratch_gru.jlCartelle:
data: In questa cartella troverai file.csvcontenenti i dati per addestrare il modello. Qui vengono memorizzati i file con i prezzi delle azioni.plots: Cartella utilizzata per memorizzare i grafici ottenuti dopo l’addestramento del modello.src: Questa cartella è il nucleo del progetto e contiene i file.jlnecessari per preprocessare i dati, addestrare il modello, costruire l’architettura RNN, creare le celle GRU e realizzare i grafici.tests: Questa cartella contiene i test di unità realizzati con Julia per garantire la correttezza del codice e rilevare bug. La spiegazione dei contenuti di questa cartella va oltre lo scopo di questo articolo. Puoi usarla come riferimento e fammi sapere se desideri un articolo che esplori il pacchettoTest.
Test di unità
Base.runtests(tests=[“all”]; ncores=ceil(Int, Sys.CPU_THREADS / 2), exit_on_error=false, revise=false, [seed]) Esegui il…
docs.julialang.org
3.2. Pacchetti richiesti
Anche se inizieremo da zero, i seguenti pacchetti sono richiesti:
CSV(0.10.11):CSVè un pacchetto in Julia per lavorare con file Comma-Separated Values (CSV).DataFrames(1.5.0):DataFramesè un pacchetto in Julia per lavorare con dati tabulari.LinearAlgebra(standard):LinearAlgebraè un pacchetto standard in Julia che fornisce una collezione di routine di algebra lineare.Base(standard):Baseè il modulo standard in Julia che fornisce funzionalità fondamentali e tipi di dati di base.Statistics(standard):Statisticsè un modulo standard in Julia che fornisce funzioni statistiche e algoritmi per l’analisi dei dati.ArgParse(1.1.4):ArgParseè un pacchetto in Julia per il parsing degli argomenti della riga di comando. Fornisce un modo facile e flessibile per definire interfacce a riga di comando per script e applicazioni Julia.Plots(1.38.16):Plotsè un pacchetto di tracciamento popolare in Julia che fornisce un’interfaccia di alto livello per la creazione di visualizzazioni dei dati.Random(standard):Randomè un modulo standard in Julia che fornisce funzioni per generare numeri casuali e lavorare con processi casuali.Test(standard, solo test di unità):Testè un modulo standard in Julia che fornisce utilità per la scrittura di test di unità (oltre lo scopo di questo articolo).
Utilizzando Project.toml, è possibile creare un ambiente contenente i pacchetti sopra citati. Questo file è simile a requirements.txt in Python o a environment.yml in Conda. Esegui il seguente comando per installare le dipendenze:
julia --project=. -e 'using Pkg; Pkg.instantiate()'3.3. Prezzi delle azioni
Come data science practitioner, comprendi che i dati sono il carburante che alimenta ogni modello di machine learning o statistico. Nel nostro esempio, i dati specifici del dominio provengono dal mercato azionario. Yahoo Finance fornisce statistiche di mercato azionario pubblicamente disponibili. Esamineremo specificamente le statistiche storiche per Google Inc. (GOOG). Tuttavia, è possibile cercare e scaricare dati per altre aziende, come IBM e Apple.
Alphabet Inc. (GOOG) Prezzi storici delle azioni e dati – Yahoo Finance
Scopri i prezzi storici delle azioni di GOOG su Yahoo Finance. Visualizza il formato giornaliero, settimanale o mensile fino a quando Alphabet…
finance.yahoo.com
4. Implementazione della rete GRU
All’interno della cartella src, puoi esaminare i file utilizzati per generare i grafici che verranno presentati nella Sezione 5 (prediction_plots.jl), elaborare i prezzi delle azioni prima dell’addestramento del modello (data_preprocessing.jl), addestrare e costruire la rete GRU (scratch_gru.jl) e integrare tutti i file sopra citati in una volta sola (main.jl). In questa sezione, approfondiremo le quattro funzioni che compongono il cuore dell’architettura della rete GRU e che vengono utilizzate per implementare l’inoltro e la retropropagazione durante l’addestramento.
4.1. Funzione gru_cell_forward
Il frammento di codice presentato di seguito corrisponde alla funzione gru_cell_forward. Questa funzione riceve l’input corrente (x), lo stato nascosto precedente (prev_h) e un dizionario di parametri come input (parameters). Con i parametri sopra citati, questa funzione consente un passaggio in avanti della cella GRU e calcola il gate di aggiornamento (z), il gate di reset (r), il nuovo stato nascosto o la cella di memoria candidata (h_tilde) e lo stato nascosto successivo (next_h), utilizzando le funzioni sigmoid e tanh. Calcola anche la previsione della cella GRU (y_pred). All’interno di questa funzione, vengono implementate le equazioni presentate nelle Figure 3 e 4.
4.2. Funzione gru_forward
A differenza di gru_cell_forward, gru_forward effettua l’inoltro della rete GRU, ossia la propagazione in avanti per una sequenza di passaggi temporali. Questa funzione riceve il tensore di input (x), lo stato nascosto iniziale (ho) e un dizionario come input (parameters).
Se sei nuovo ai modelli sequenziali, non confondere un passaggio temporale con le iterazioni in modo che l’errore del modello possa essere minimizzato.
Non confondere il x che gru_cell_forward riceve con quello che gru_forward riceve. In gru_forward, x ha tre dimensioni anziché due. La terza dimensione corrisponde al totale delle celle GRU che ha il layer RNN. In breve, gru_cell_forward è correlato alla Figura 2, mentre gru_forward è correlato alla Figura 1.
gru_forward itera su ogni passaggio temporale della sequenza, chiamando la funzione gru_cell_forward per calcolare next_h e y_pred. I risultati vengono memorizzati rispettivamente in h e y.
4.3. Funzione gru_cell_backward
gru_cell_backward esegue il passaggio all’indietro per una singola cella GRU. gru_cell_forward riceve il gradiente dello stato nascosto (dh) come input, accompagnato dalla cache che contiene gli elementi necessari per calcolare le derivate nella Figura 4 (cioè next_h, prev_h, z, r, h_tilde, x, e parameters). In questo modo, gru_cell_backward calcola i gradienti per le matrici dei pesi (cioè Wz, Wr, e Wh) e i bias (cioè bz, br, e bh). Tutti i gradienti sono memorizzati in un dizionario Julia (gradients).
4.4. Funzione gru_backward
gru_backward esegue la retropropagazione per l’intera rete GRU, ovvero per l’intera sequenza di passi temporali. Questa funzione riceve il gradiente del tensore dello stato nascosto (dh) e le caches. A differenza del caso di gru_cell_backward, dh per gru_backward ha una terza dimensione corrispondente al numero totale di passi temporali nella sequenza o celle GRU nel livello di rete GRU. Questa funzione itera sui passi temporali in ordine inverso, chiamando gru_cell_backward per calcolare i gradienti per ogni passo temporale, accumulandoli durante il ciclo.
È fondamentale notare in questa fase che questo progetto utilizza solo la discesa del gradiente per aggiornare i parametri della rete GRU e non include alcuna funzionalità che influisce sul tasso di apprendimento o introduce momento. Inoltre, l’implementazione è stata creata con una preoccupazione di regressione in mente. Tuttavia, grazie alla modularizzazione implementata, sono necessari solo piccoli cambiamenti per ottenere un comportamento diverso.
5. Risultati e intuizioni
Ora eseguiamo il codice per addestrare la rete GRU. Grazie all’integrazione del pacchetto ArgParse, possiamo utilizzare gli argomenti della riga di comando per eseguire il codice. La procedura è la stessa se sei familiare con Python. Effettueremo l’esperimento utilizzando una suddivisione di addestramento del 0,7 (split_ratio), una lunghezza della sequenza di 10 (seq_length), una dimensione nascosta di 70 (hidden_size), 1000 epoche (num_epochs), e un tasso di apprendimento di 0,00001 (learning_rate) perché lo scopo di questo progetto non è ottimizzare gli iperparametri (che richiederebbe l’uso di moduli aggiuntivi). Esegui il seguente comando per avviare l’addestramento:
julia --project src/main.jl --data_file GOOG.csv --split_ratio 0.7 --seq_length 10 --hidden_size 70 --num_epochs 1000 --learning_rate 0.00001Anche se il modello viene addestrato per 1000 epoche, c’è un controllo di flusso nella funzione
train_gruche memorizza il miglior valore per i parametri.
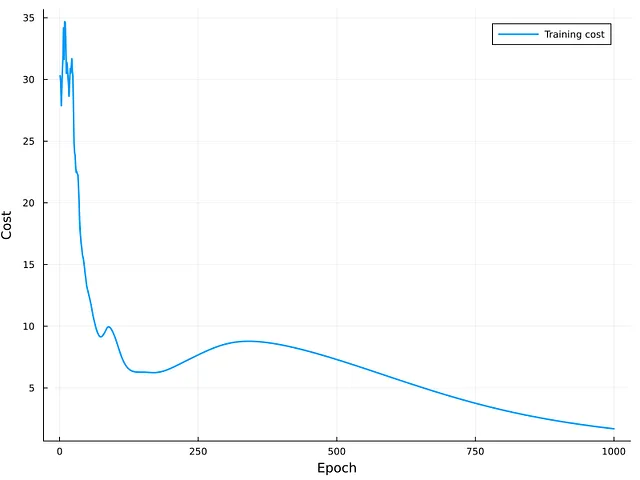
La Figura 5 rappresenta il costo delle iterazioni di addestramento. Come si può osservare, la curva ha una tendenza decrescente e il modello sembra convergere nelle ultime iterazioni. A causa della curvatura della curva, è possibile che ulteriori miglioramenti possano essere ottenuti aumentando il numero di epoche per addestrare la rete GRU. La valutazione esterna dell’insieme di test restituisce un errore quadratico medio (MSE) di circa 6.57. Sebbene questo valore potrebbe non essere vicino allo zero, non è possibile trarre una conclusione finale a causa della mancanza di un valore di riferimento per il confronto.
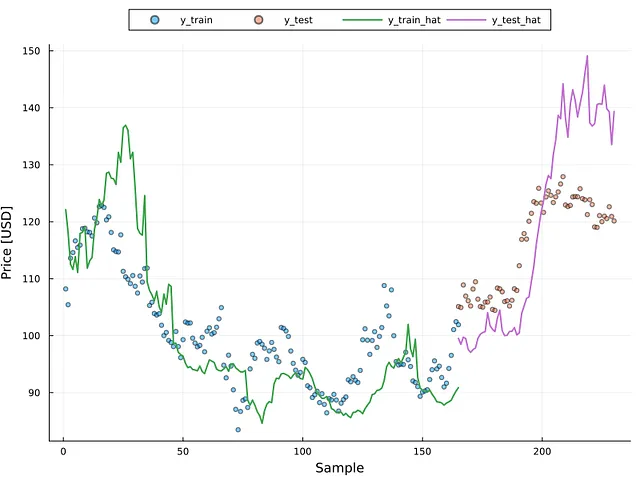
La figura 6 rappresenta i valori effettivi per i set di dati di addestramento e di test come punti sparsi e i valori previsti come linee continue (vedi la legenda della figura per ulteriori dettagli). È chiaro che il modello corrisponde alla tendenza effettiva dei punti; tuttavia, è necessario ulteriore addestramento per migliorare le prestazioni della rete GRU. Tuttavia, è possibile vedere che in alcune parti dell’immagine, in particolare sul lato di addestramento, il modello ha sovradattato alcuni campioni; dato che l’errore quadratico medio (MSE) per il set di addestramento era intorno a 1,70, è possibile che il modello mostri un certo sovradattamento.
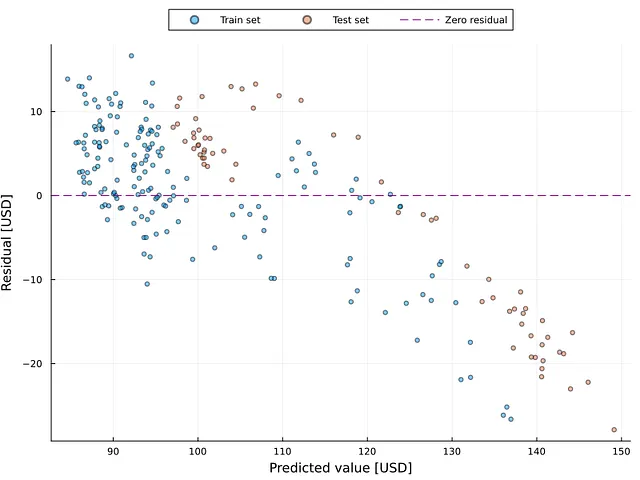
La fluttuazione o l’instabilità dell’errore potrebbe essere una difficoltà nell’analisi di regressione, compresa la previsione delle serie temporali. Nella scienza dei dati e nelle statistiche, questo è noto come eteroschedasticità (per ulteriori informazioni, consulta il post qui sotto 👇). Il grafico dei residui è un metodo per rilevare l’eteroschedasticità. La figura 7 illustra il grafico dei residui, dove l’asse x rappresenta il valore previsto e l’asse y rappresenta il residuo.
Eteroschedasticità e omoschedasticità nell’apprendimento di regressione
Variabilità del residuo nell’analisi di regressione
pub.towardsai.net
I punti uniformemente spaziati intorno al valore zero indicano la presenza di omoschedasticità (cioè residui stabili). Questa figura mostra la presenza di eteroschedasticità in questa situazione, che richiederebbe l’uso di metodi per correggere il problema (ad esempio, la trasformazione logaritmica) al fine di creare un modello ad alte prestazioni. La figura 7 mostra che la presenza di eteroschedasticità è evidente oltre i 120 USD, indipendentemente che il campione provenga dal set di addestramento o di test. La figura 6 contribuisce a rafforzare questo punto. La figura 6 indica che i valori superiori a 120 si discostano significativamente dal numero reale.
Conclusioni
In questo post, abbiamo costruito una rete GRU da zero utilizzando il linguaggio di programmazione Julia. Abbiamo iniziato esaminando le equazioni matematiche che il programma doveva considerare, nonché le questioni teoriche più critiche affinché l’implementazione GRU avesse successo. Abbiamo illustrato come creare le impostazioni iniziali per i programmi Julia per gestire i dati, stabilire l’architettura GRU, addestrare il modello e valutare il modello. Abbiamo esaminato i frammenti di codice più importanti utilizzati nella progettazione dell’architettura del modello. Abbiamo eseguito i programmi per analizzare i risultati. Abbiamo rilevato la presenza di eteroschedasticità in questo progetto specifico, raccomandando l’indagine di strategie per superare questo problema e creare una rete GRU ad alte prestazioni.
Invito a esaminare il codice su GitHub e farmi sapere se desideri che esaminiamo qualcos’altro in Julia o in un altro argomento di scienza dei dati o programmazione. I tuoi pensieri e il tuo feedback sono estremamente utili per me 🚀…
Materiale aggiuntivo
- Unità ricorrenti con gate (GRU)
- Corso completo sulle modelli di sequenza
Se ti piacciono i miei post, seguimi su VoAGI per rimanere aggiornato su altri contenuti stimolanti e condividi questo materiale con i tuoi colleghi.







