Replicazione dei dati CDC tecniche, compromessi, intuizioni
Replicazione dati CDC - tecniche, compromessi, intuizioni
Molte organizzazioni in diversi settori operano con database di produzione in cui la maggior parte dei dati non cambia molto frequentemente, ovvero i cambiamenti e gli aggiornamenti giornalieri rappresentano solo una piccola parte dell’ammontare complessivo dei dati archiviati. Sono proprio queste organizzazioni che possono trarre maggiori vantaggi dalla replica dei dati CDC (Change Data Capture).
In questo articolo, definirò la replica dei dati CDC, discuterò brevemente i casi d’uso più comuni e parlerò delle tecniche comuni e dei compromessi di ognuna. Verso la fine, darò alcuni suggerimenti generali sull’implementazione che ho imparato come CEO e fondatore della società di integrazione dati Dataddo.
- Impatto di ChatGPT sui copywriter difficoltà e speranze per un futuro integrato con l’IA
- Il Potere dell’IA nell’Educazione Trasformare l’Apprendimento per il Successo Personalizzato
- Congratulazioni per il tuo modello di previsione del valore a vita del cliente (CLV) – ora cosa ne farai?
Cos’è la Replica dei Dati CDC (Change Data Capture)?
La replica dei dati CDC è un metodo per copiare i dati in tempo reale o quasi in tempo reale tra due database, in cui vengono copiati solo i dati nuovi o modificati.
È un’alternativa alla replica istantanea, che prevede il trasferimento di un’intera istantanea di un database verso un altro, ripetutamente. La replica istantanea può essere adatta per le organizzazioni che hanno bisogno di conservare istantanee individuali dei loro dati nel tempo, ma è molto intensiva dal punto di vista del processo e lascia una grande impronta finanziaria. Per le organizzazioni che non hanno questa necessità, la replica dei dati CDC può risparmiare molto tempo di elaborazione a pagamento.
Le modifiche ai dati possono essere catturate e inviate alla loro nuova destinazione in tempo reale o in piccoli lotti (ad es. ogni ora).
Vale la pena menzionare che il CDC non è un processo nuovo. Tuttavia, fino a poco tempo fa, solo le grandi organizzazioni avevano le risorse di ingegneria per implementarlo. Ciò che è nuovo è la crescente selezione di strumenti gestiti che lo rendono possibile a una frazione del costo, quindi la sua recente popolarità.
Casi d’Uso più Comuni del CDC
In questo articolo non c’è spazio sufficiente per coprire tutti i casi d’uso della replica dei dati CDC, ma ecco tre dei più comuni.
Data Warehousing per Business Intelligence e Analisi
Ogni organizzazione che gestisce un sistema proprietario di raccolta dati probabilmente ha un database di produzione che memorizza informazioni chiave da questo sistema.
Dato che i database di produzione sono progettati per operazioni di scrittura, non fanno molto per mettere i dati in un uso redditizio. Molte organizzazioni vorranno quindi copiare i dati in un data warehouse, dove possono eseguire operazioni di lettura complesse per analisi e business intelligence.
Se il tuo team di analisti ha bisogno dei dati quasi in tempo reale, il CDC è un buon modo per fornirli, in quanto fornirà rapidamente le modifiche al data warehouse di analisi man mano che vengono effettuate.
Migrazione del Database
Il CDC è anche utile quando si passa da una tecnologia di database a un’altra e si ha bisogno di mantenere tutto disponibile in caso di tempo di inattività. Un esempio classico sarebbe la migrazione da un database in loco a un database cloud.
Ripristino in caso di Disastro
Simile al caso di migrazione, il CDC è un modo efficiente e potenzialmente conveniente per garantire che tutti i tuoi dati siano disponibili in più posizioni fisiche tutto il tempo, in caso di tempo di inattività in una di esse.
Tecniche Comuni di CDC e i Compromessi di Ognuna
Esistono tre tecniche principali di CDC, ognuna con i propri vantaggi e svantaggi.

CDC Basato su Query
Il CDC basato su query è piuttosto semplice. Tutto ciò che fai con questa tecnica è scrivere una semplice query di selezione per selezionare i dati da una tabella specifica, seguita da qualche condizione, come “seleziona solo i dati che sono stati aggiornati o aggiunti ieri”. Presumendo che tu abbia già configurato lo schema per una tabella secondaria, queste query prenderanno quindi questi dati modificati e produrranno una nuova tabella bidimensionale con i dati, che possono essere inseriti in una nuova posizione.
Vantaggi
- Altamente flessibile. Consente di definire quali modifiche catturare e come catturarle. Ciò rende più facile personalizzare il processo di replica in modo molto dettagliato.
- Riduce i costi. Cattura solo le modifiche che soddisfano determinati criteri, quindi è molto più economico rispetto al CDC che cattura tutte le modifiche a un database.
- Più facile da risolvere. Le singole query possono essere facilmente esaminate e corrette in caso di problemi.
Svantaggi
- Mantenimento complesso. Ogni singola query deve essere mantenuta. Ad esempio, se hai un paio di centinaia di tabelle nel tuo database, probabilmente avrai bisogno di altrettante query e mantenerle tutte sarebbe un incubo. Questo è il principale svantaggio.
- Maggiore latenza. Si basa sul controllo delle modifiche, il che può introdurre ritardi nel processo di replica. Ciò significa che non è possibile ottenere replicazioni in tempo reale utilizzando le query di selezione e che è necessario pianificare qualche tipo di elaborazione batch. Questo potrebbe non essere un grosso problema se hai bisogno di analizzare qualcosa utilizzando una serie temporale lunga, come il comportamento dei clienti.
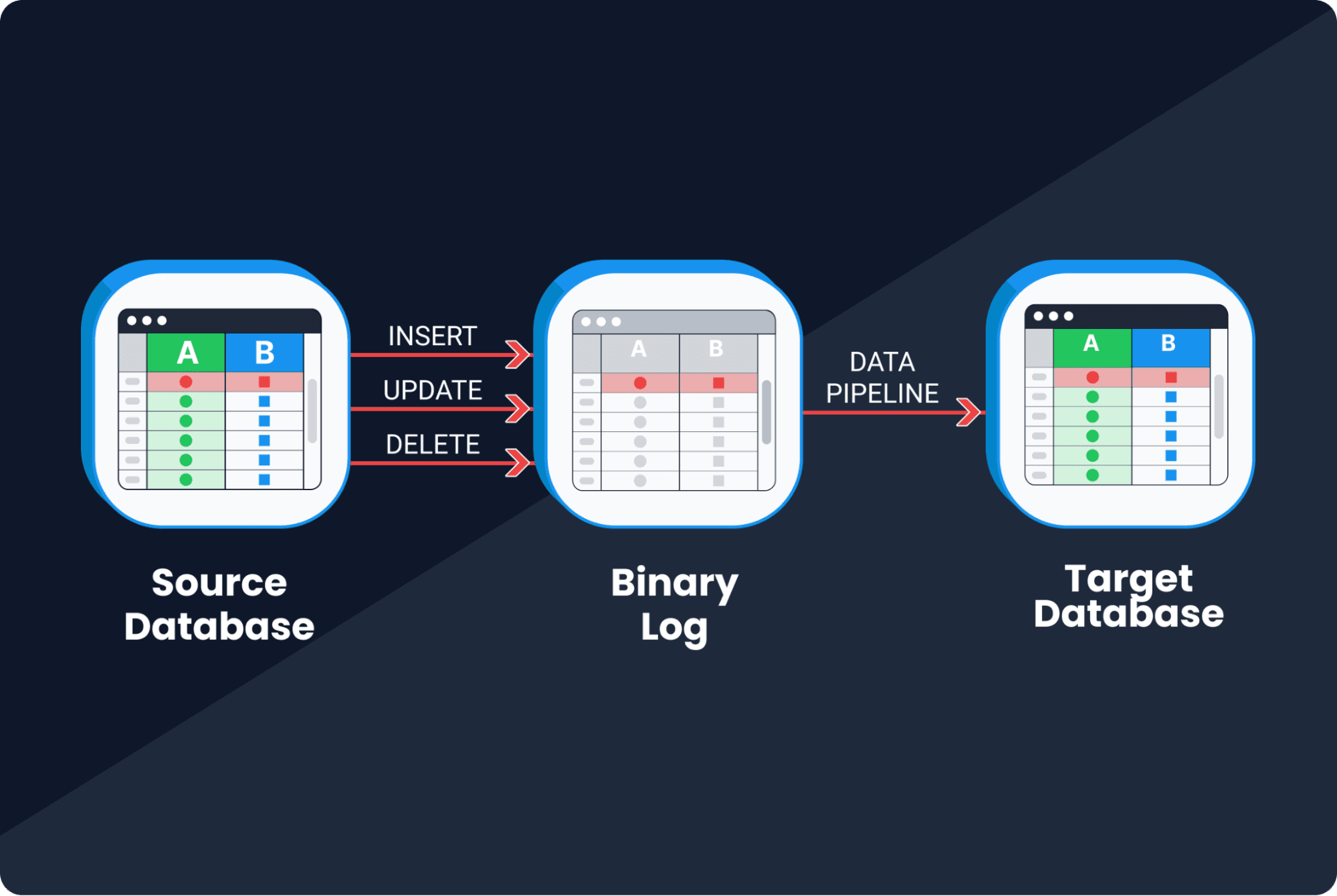
CDC basato su log
La maggior parte delle tecnologie di database che utilizziamo oggi supporta il clustering, il che significa che è possibile eseguirle in più repliche per ottenere un’alta disponibilità. Tali tecnologie devono avere un tipo di log binario, che registra tutte le modifiche al database. Nel CDC basato su log, le modifiche vengono lette dal log anziché dal database stesso, quindi replicate nel sistema di destinazione.
Vantaggi
- Bassa latenza. Le modifiche dei dati possono essere replicate molto rapidamente nei sistemi a valle.
- Alta fedeltà. I log registrano tutte le modifiche al database, inclusi i cambiamenti del linguaggio di definizione dei dati (DDL) e i cambiamenti del linguaggio di manipolazione dei dati (DML). Ciò rende possibile tracciare le righe eliminate (cosa impossibile con il CDC basato su query).
Svantaggi
- Maggiore rischio di sicurezza. Richiede l’accesso diretto al log delle transazioni del database. Ciò può sollevare preoccupazioni sulla sicurezza, in quanto richiederà ampi livelli di accesso.
- Flessibilità limitata. Registra tutte le modifiche al database, il che limita la flessibilità per definire modifiche e personalizzare il processo di replica. In caso di elevati requisiti di personalizzazione, i log dovranno essere pesantemente post-elaborati.
In generale, il CDC basato su log è difficile da implementare. Consultare la sezione “insights” di seguito per ulteriori informazioni.
CDC basato su trigger
Il CDC basato su trigger è una sorta di miscela tra le prime due tecniche. Prevede la definizione di trigger per catturare determinate modifiche in una tabella, che vengono quindi inserite e monitorate in una nuova tabella. È da questa nuova tabella che le modifiche vengono replicate nel sistema di destinazione.
Vantaggi
- Flessibilità. Consente di definire quali modifiche catturare e come catturarle (come nel CDC basato su query), inclusi le righe eliminate (come nel CDC basato su log).
- Bassa latenza. Ogni volta che un trigger viene attivato, viene considerato un evento e gli eventi possono essere elaborati in tempo reale o quasi in tempo reale.
Svantaggi
- Mantenimento estremamente complesso. Proprio come le query nel CDC basato su query, tutti i trigger devono essere mantenuti singolarmente. Quindi, se hai un database con 200 tabelle e devi catturare le modifiche per tutte loro, il costo complessivo di manutenzione sarà molto elevato.
Considerazioni sull’implementazione
Come CEO di un’azienda di integrazione dei dati, ho avuto molta esperienza nell’implementazione del CDC su scala grande e piccola. Ecco alcune cose che ho imparato lungo il percorso.
Diverse implementazioni per diversi log
La CDC basata su log è particolarmente complessa. Ciò è dovuto al fatto che tutti i log, ad esempio BinLog per MySQL, WAL per Postgres, Redo Log per Oracle, Oplog per Mongo DB, sebbene concettualmente identici, sono implementati in modo diverso. Pertanto, sarà necessario approfondire i parametri a basso livello del database scelto per far funzionare le cose.
Scrittura delle modifiche dei dati nella destinazione di destinazione
Dovrai determinare come inserire, aggiornare ed eliminare esattamente i dati nella destinazione di destinazione.
In generale, l’inserimento è facile, ma il volume gioca un ruolo importante nel dettare l’approccio. Che tu utilizzi l’inserimento batch, lo streaming dei dati o decida di caricare le modifiche utilizzando un file, ti troverai sempre di fronte a compromessi tecnologici.
Per garantire un aggiornamento corretto e evitare duplicati non necessari, sarà necessario definire una chiave virtuale in cima alle tue tabelle che indichi al sistema cosa inserire e cosa aggiornare.
Per garantire l’eliminazione corretta, sarà necessario avere un meccanismo di sicurezza per assicurarsi che una cattiva implementazione non causi l’eliminazione di tutti i dati nella tabella di destinazione.
Mantenere lavori di lunga durata
Se stai trasferendo solo poche righe, le cose saranno piuttosto facili, ma se questo è il caso, probabilmente non hai bisogno di CDC. Pertanto, in generale, possiamo aspettarci che i lavori di CDC richiedano diversi minuti o addirittura ore, e ciò richiederà meccanismi affidabili per il monitoraggio e la manutenzione.
Gestione degli errori
Questo potrebbe essere argomento di un articolo separato. In breve, posso dire che ogni tecnologia ha un modo diverso per gestire le eccezioni e presentare gli errori. Quindi, dovresti definire una strategia su cosa fare se una connessione fallisce. Dovresti riprovare? Dovresti incapsulare tutto nelle transazioni?
Implementare la replica dei dati CDC internamente è piuttosto complicato e molto specifico per ogni caso. Questo è il motivo per cui tradizionalmente non è stata una soluzione di replica popolare e anche il motivo per cui è difficile dare consigli generali su come implementarla. Negli ultimi anni, strumenti gestiti come Dataddo, Informatica, SAP Replication Server e altri hanno notevolmente abbassato la barriera di accessibilità.
Non per tutti, ma ottimo per alcuni
Come ho menzionato all’inizio di questo articolo, la CDC ha il potenziale per risparmiare molte risorse finanziarie alle aziende:
- Che hanno un database principale composto principalmente da dati che non cambiano frequentemente (cioè le modifiche quotidiane rappresentano solo una piccola parte dei dati in essi)
- Che hanno bisogno dei dati in tempo quasi reale per i team di analisi
- Che non hanno bisogno di conservare snapshot completi del loro database principale nel tempo
Tuttavia, non esistono soluzioni tecnologiche perfette, solo compromessi. E lo stesso vale per la replica dei dati CDC. Coloro che scelgono di implementare la CDC dovranno dare priorità in modo disuguale a flessibilità, fedeltà, latenza, manutenzione e sicurezza. Petr Nemeth è il fondatore e CEO di Dataddo, una piattaforma di integrazione dati completamente gestita e senza codice che connette servizi basati su cloud, applicazioni di dashboarding, data warehouse e data lake. La piattaforma offre funzionalità di ETL, ELT, reverse ETL e replica del database (compresa la CDC), nonché un’ampia gamma di oltre 200 connettori, consentendo ai professionisti aziendali di qualsiasi livello di competenza tecnica di inviare dati da praticamente qualsiasi origine a qualsiasi destinazione. Prima di fondare Dataddo, Petr ha lavorato come sviluppatore, analista e architetto di sistema per aziende di telecomunicazioni, IT e media su progetti su larga scala che coinvolgono l’internet delle cose, big data e business intelligence.






