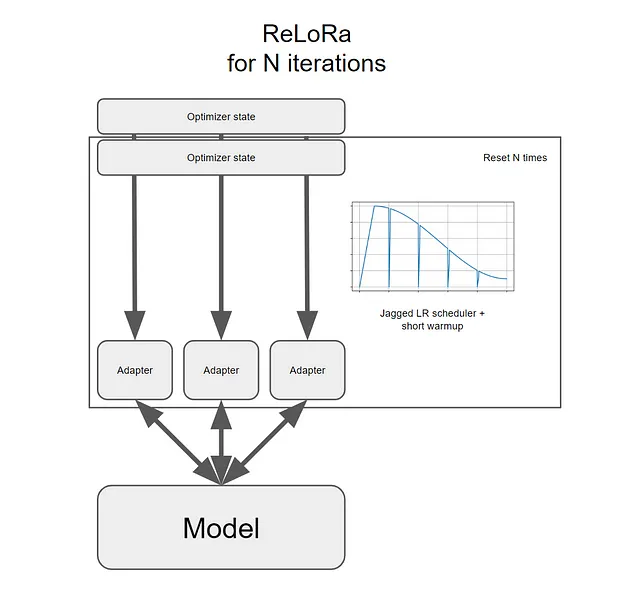
ReLoRa Pre-allena un grande modello di linguaggio sulla tua GPU
ReLoRa Pre-allena un modello di linguaggio sulla tua GPU
LoRa ma con più reset di fila
Nel 2021, Hu et al. hanno proposto gli adattatori a basso rango (LoRa) per i modelli linguistici di grandi dimensioni (LLM). Questo metodo riduce significativamente il costo del fine-tuning dei grandi modelli linguistici (LLM) addestrando solo pochi parametri aggiunti (reti a basso rango) e mantenendo i parametri originali del LLM (reti ad alto rango) congelati.
Con LoRa, è ancora necessario disporre di un modello pre-addestrato per il fine-tuning, ovvero non è possibile addestrare da zero un buon LLM a causa delle restrizioni del basso rango. Ciò rende il pre-addestramento inaccessibile per la maggior parte delle persone e delle organizzazioni.
Per ridurre questo costo, Lialin et al. (2023) propongono ReLoRa. Si tratta di una modifica di LoRa che consente il pre-addestramento dei LLM da zero.
In questo articolo, spiego innanzitutto come funziona ReLoRa. Successivamente, analizzo e commento i risultati presentati nel paper scientifico che descrive ReLoRa. Nell’ultima sezione, mostro come configurare ed eseguire ReLoRa sul tuo computer.
- Comprensione dei Fondamenti delle Reti Neurali e dell’Apprendimento Profondo
- Esplorazione del potere e dei limiti di GPT-4
- Allenare, ottimizzare e distribuire efficientemente insiemi personalizzati utilizzando Amazon SageMaker
Nota sulle licenze: Il paper scientifico pubblicato su arXiv che descrive ReLoRa è distribuito con licenza CC BY 4.0. Il codice sorgente di ReLoRa è pubblicato su GitHub e distribuito con licenza Apache 2.0 che consente l’uso commerciale.
ReLoRa: dal rango basso al rango alto
Per capire come funziona ReLoRa, dobbiamo prima dare un’occhiata più da vicino a LoRa.
LoRa funziona aggiungendo due diversi insiemi di parametri addestrabili, A e B, che vengono successivamente fusi con la rete originale ad alto rango congelata del modello pre-addestrato.
Può sembrare ovvio, ma è importante capire che il rango della somma di A e B è superiore alla somma dei loro ranghi individuali. Questo può essere formalizzato come segue:
LoRa addestra solo questi due insiemi di parametri. Tuttavia, se potessimo eseguire reset, addestrare e fondere nuovamente nella rete ad alto rango originale più volte di fila, saremmo in grado di aumentare nel tempo il rango totale della rete. In altre parole, otterremmo un modello più grande.
Perché LoRa non esegue questi reset?
Perché ci sono diversi ostacoli significativi da superare per rendere utili questi reset…