10 Modi per Aggiungere una Colonna ai DataFrames di Pandas
10 Modi per Aggiungere una Colonna a Pandas DataFrames
Abbiamo spesso bisogno di derivare o creare nuove colonne

DataFrame è una struttura dati bidimensionale con righe e colonne etichettate. Spesso abbiamo bisogno di aggiungere nuove colonne come parte dell’analisi dei dati o dei processi di ingegneria delle feature.
Ci sono molti modi diversi per aggiungere nuove colonne. Quale metodo si adatta meglio alle tue esigenze dipende dal compito in questione.
In questo articolo, impareremo 10 modi per aggiungere una colonna ai DataFrame di Pandas.
Iniziamo creando un semplice DataFrame usando il costruttore DataFrame di Pandas. Passeremo i dati come un dictionary Python con i nomi delle colonne come chiavi e le righe come valori del dizionario.
- David Smith, Chief Data Officer presso TheVentureCity – Serie di interviste
- LMSYS ORG presenta Chatbot Arena una piattaforma di benchmarking LLM crowdsourcing con battaglie anonime e casuali
- Incontra Mojo Un nuovo linguaggio di programmazione per sviluppatori di intelligenza artificiale che combina l’usabilità di Python e le prestazioni di C per una programmabilità senza pari dell’hardware di intelligenza artificiale e l’estensibilità dei modelli di intelligenza artificiale.
import pandas as pd# creazione DataFrame df = pd.DataFrame( { "nome": ["Jane", "John", "Max", "Emily", "Ashley"], "cognome": ["Doe", "Doe", "Dune", "Smith", "Fox"], "id": [101, 103, 143, 118, 128] } )# visualizzazione DataFrame df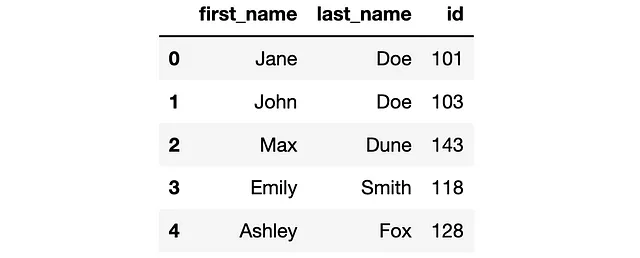
1. Utilizzare un valore costante
Possiamo aggiungere una nuova colonna con un valore costante come segue:
df.loc[:, "reparto"] = "ingegneria"# visualizzazione DataFrame df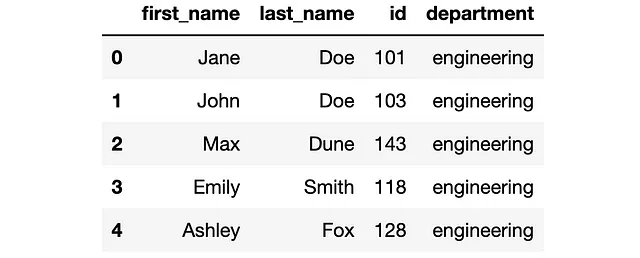
2. Utilizzare strutture simili a array
Possiamo utilizzare una struttura simile a un array per aggiungere una nuova colonna. In questo caso, assicurati che il numero di valori nell’array sia lo stesso del numero di righe nel DataFrame.
df.loc[:, "stipendio"] = [45000, 43000, 42000, 45900, 54000]Nell’esempio sopra, abbiamo utilizzato una lista Python. Determiniamo i valori in modo casuale con il modulo random di NumPy.
import numpy as npdf.loc[:, "stipendio"] = np.random.randint(40000, 55000, size=5)# visualizzazione DataFrame df




