Programmare e invocare i notebook come servizi web utilizzando l’API di Jupyter
Programmare e invocare i notebook come servizi web con l'API di Jupyter
Grazie ai servizi di cloud serverless come GCP CloudRunner e Cloud Functions, non è necessario gestire costose macchine virtuali o server per distribuire i nostri notebook ed eseguirli periodicamente. Con l’API di Jupyter, è possibile spostare i notebook nel cloud, trasformarli in servizi web e integrarli con la pianificazione.

Tuttavia, l’approccio più comunemente utilizzato (a meno che non si stiano utilizzando servizi nativi del cloud come Vertex AI o SageMaker) è quello di convertire i notebook in codice Python utilizzando nbconvert e aggiungere il codice a un’applicazione web personalizzata Tornado o Flask appena avviata.

Ciò include alcune codifiche e librerie esterne, ma la buona notizia è che possiamo lasciare il nostro codice nel nostro container di sviluppo Jupyter e attivarlo direttamente da lì utilizzando l’API Rest di Jupyter.
Accesso a un Notebook tramite Web API
Prima di entrare nei dettagli su come utilizzare l’API di Jupyter, mostrerò come funzionerà l’architettura. Innanzitutto, prendiamo un semplice notebook che possiamo utilizzare per i test.
- Stability AI annuncia il lancio di StableCode il suo primo prodotto Generative AI LLM per la codifica.
- Matematica nel mondo reale Test, simulazioni e altro
- Come progettare una ricerca aziendale basata sull’IA in AWS
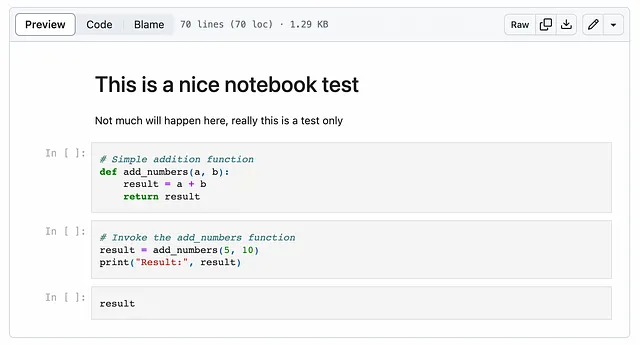
Per eseguirlo in locale utilizzando Jupyter, il modo più semplice è eseguirlo in un container Jupyter Lab:
# scarica il notebook di testwget https://raw.githubusercontent.com/tfoldi/vizallas/main/notebooks/JupyterAPI_Test.ipynb# Avvia una nuova istanza di Jupyter lab con autenticazione del token (e senza XSRF)docker run -it --rm -p 8888:8888 \ -e JUPYTER_TOKEN=ab30dd71a2ac8f9abe7160d4d5520d9a19dbdb48abcdabcd \ --name testnb -v "${PWD}":/home/jovyan/work jupyter/base-notebook \ jupyter lab --ServerApp.disable_check_xsrf=trueUna volta avviato il servizio, sarà possibile accedere al notebook all’indirizzo http://127.0.0.1:8888/lab/tree/work utilizzando il token passato nella variabile d’ambiente JUPYTER_TOKEN.
Chiamare il Notebook dalla riga di comando
Dalla riga di comando, è possibile scaricare questo piccolo script (richiede i pacchetti requests e websocket-client) o eseguirlo tramite un container Docker:
# controlla l'indirizzo IP del nostro container "testnb" precedentemente avviatodocker inspect testnb | grep IPAddress "SecondaryIPAddresses": null, "IPAddress": "172.17.0.2", "IPAddress": "172.17.0.2",# Invoca il nostro notebook. Sostituisci l'IP sottostante con quello ottenuto dal passaggio precedentedocker run -it --rm \ -e JUPYTER_TOKEN=ab30dd71a2ac8f9abe7160d4d5520d9a19dbdb48abcdabcd \ tfoldi/jupyterapi_nbrunner 172.17.0.2:8888 /work/JupyterAPI_Test.ipynbCreazione di un nuovo kernel su http://172.17.0.2:8888/api/kernelsInvio delle richieste di esecuzione per ogni cella{'data': {'text/plain': '15'}, 'execution_count': 3, 'metadata': {}}Elaborazione terminata. Chiusura della connessione del websocketEliminazione del kernelQuesto script si connette al nostro server JupyterLab appena creato, esegue il notebook, restituisce il risultato dell’ultima cella e quindi termina. L’intera procedura avviene tramite protocolli web senza richiedere modifiche al codice del notebook o librerie aggiuntive.
Sotto il cofano
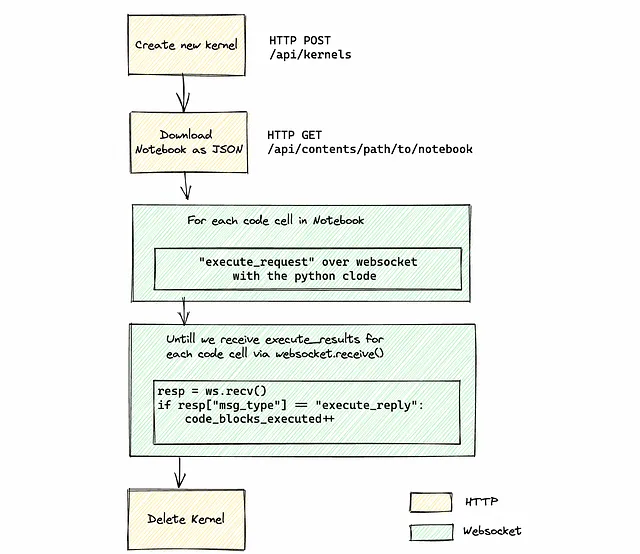
Purtroppo, non c’è un singolo endpoint nell’API di Jupyter per eseguire un notebook dall’inizio alla fine. Prima di tutto, dobbiamo inizializzare un nuovo kernel (o utilizzarne uno esistente), recuperare i metadati del notebook, ottenere tutte le celle di codice e inviare una richiesta di esecuzione per ognuna di esse.
Per recuperare i risultati, dobbiamo ascoltare i messaggi in arrivo nel canale WebSocket. Poiché non c’è un messaggio di “fine di tutte le esecuzioni del codice”, dobbiamo tenere traccia manualmente di quante blocchi di codice abbiamo inviato per l’esecuzione e quanti di essi sono effettivamente stati completati contando tutti i messaggi di tipo execute_reply. Una volta che tutto ha finito di eseguire, possiamo fermare il kernel o lasciarlo in uno stato di inattività per future esecuzioni.
Il diagramma seguente illustra il flusso completo:
Per rimanere autenticati, dobbiamo passare l’intestazione Authorization per tutte le chiamate HTTP e WebSocket.
Se tutto questo sembra un numero eccessivo di passaggi solo per eseguire un notebook, capisco. Sono sicuro che sarebbe utile implementare una funzione di livello superiore all’interno di Jupyter Server per ridurre la complessità.
Lo script completo è qui, pronto per essere utilizzato nelle tue applicazioni.
Pianifica il nostro quaderno su GCP gratuitamente (quasi)
Anche se ci sono molte opzioni per ospitare un notebook, il modo più conveniente dal punto di vista dei costi è sfruttare il servizio Cloud Run di Google Cloud. Con Cloud Run, paghi solo per il tempo effettivo di esecuzione del tuo lavoro, rendendolo una scelta efficiente in termini di costi per attività eseguite raramente senza pacchetti extra o fornitori SaaS aggiuntivi (oltre a Google) — e, ancora una volta, senza scrivere una singola riga di codice.
L’architettura e il flusso di invocazione saranno simili a questo:
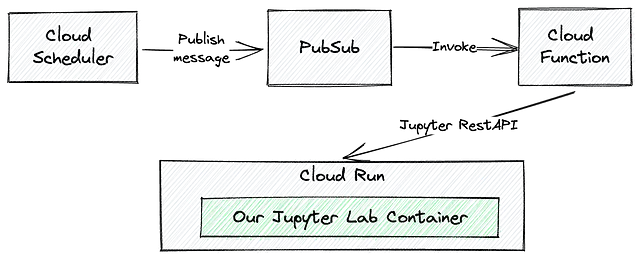
Prima di tutto, dobbiamo distribuire il nostro notebook in GCP Cloud Run. Ci sono molte modalità per aggiungere un file a un servizio Cloud Run, ma forse la più semplice è copiare i nostri notebook in un contenitore Docker.
# Dockerfile semplice per ospitare i notebook su un server JupyterFROM jupyter/base-notebookCOPY JupyterAPI_Test.ipynb /home/jovyan/workspaces/Per creare e rendere disponibile il contenitore in Cloud Run, possiamo semplicemente specificare l’opzione --source con gcloud run deploy, indicando una directory in cui si trovano i nostri notebook e il file Dockerfile.
# ottieni il codice sorgente del notebook Jupyter e del Dockerfilegit clone https://github.com/tfoldi/jupyterapi_nbrunner.git# Distribuisci il notebook di test in un contenitore jupyter/base-notebook # I file Dockerfile e JupyterAPI_Test.ipynb nella cartella tests/test_notebookgcloud run deploy test-notebook --region europe-west3 --platform managed \ --allow-unauthenticated --port=8888 \ --source tests/test_notebook \ --set-env-vars=JUPYTER_TOKEN=ab30dd71a2ac8f9abe7160d4d5520d9a19dbdb48abcdabcd [...]Il servizio [test-notebook] revisione [test-notebook-00001-mef] è stato distribuito e sta servendo il 100 percento del traffico.URL del servizio: https://test-notebook-fcaopesrva-ey.a.run.appJupyterLab sarà disponibile all’URL del servizio. Google Cloud Run fornirà i certificati SSL e i meccanismi per avviare o sospendere il contenitore a seconda delle richieste che colpiscono la distribuzione.
Per attivare il nostro notebook appena distribuito dal Cloud Scheduler, dobbiamo creare una Cloud Function legata a un argomento PubSub. Il comando seguente distribuirà main.py e requirements.txt da questo repository. Il main.py è lo stesso script che abbiamo utilizzato in precedenza per attivare il nostro codice dalla riga di comando.
# assicurati di trovarti nella stessa directory in cui hai clonato # i contenuti di https://github.com/tfoldi/jupyterapi_nbrunner.git gcloud functions deploy nbtrigger --entry-point main --runtime python311 \ --trigger-resource t_nbtrigger --trigger-event google.pubsub.topic.publish \ --timeout 540s --region europe-west3 \ --set-env-vars=JUPYTER_TOKEN=ab30dd71a2ac8f9abe7160d4d5520d9a19dbdb48abcdabcdTestiamo la nostra nuova Cloud Function inviando un messaggio all’argomento t_nbtrigger con i parametri appropriati, proprio come abbiamo fatto nella riga di comando:
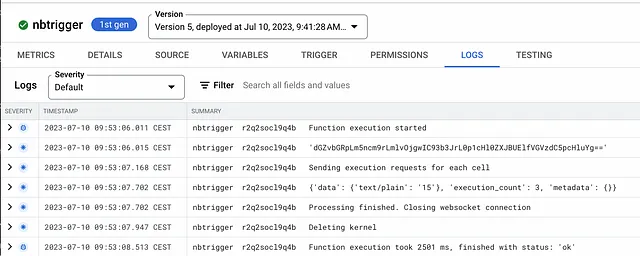
gcloud pubsub topics publish t_nbtrigger \ --message="test-notebook-fcaopesrva-ey.a.run.app:443 /workspaces/JupyterAPI_Test.ipynb --use-https"Se controlli i log della Cloud Function nbtrigger, potresti notare che l’emissione di un record all’argomento ha attivato con successo l’esecuzione del notebook specificato:
Il passaggio finale è creare un programma che viene eseguito in determinati orari. In questo caso, stiamo per eseguire il nostro notebook ogni ora:
gcloud scheduler jobs create pubsub j_hourly_nbtrigger \ --schedule "0 * * * *" --topic t_nbtrigger --location europe-west3 \ --message-body "test-notebook-fcaopesrva-ey.a.run.app:443 /workspaces/JupyterAPI_Test.ipynb --use-https --verbose" Sei pronto – hai appena pianificato il tuo primo Jupyter Notebook in modo serverless.
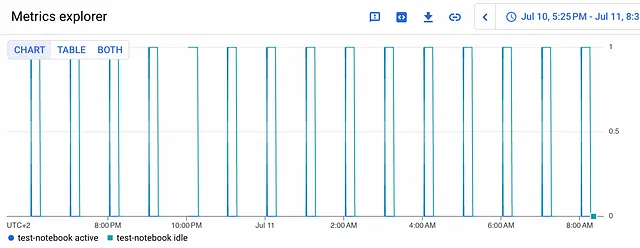
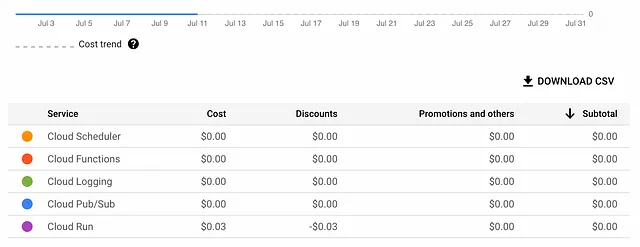
Il nostro Notebook consumerà solo pochi centesimi al giorno, rendendo questo metodo di distribuzione uno dei più convenienti in Google Cloud.
Conclusione
Un tempo ci affidavamo alla conversione dei nostri Jupyter Notebook in codice Python per renderli disponibili agli strumenti nativi del cloud o a servizi più complessi ed costosi come Vertex AI o SageMaker. Tuttavia, utilizzando l’API Jupyter Rest e distribuendo i tuoi Notebook insieme al suo “ambiente di sviluppo”, puoi evitare passaggi aggiuntivi e abilitare chiamate di servizio web o pianificazione per i tuoi Notebook.
Sebbene questo approccio non sia necessariamente adatto per progetti di grandi dimensioni con notebook a lunga durata computazionale intensiva, è perfettamente adatto per la domotica o i tuoi progetti personali – senza (sprecare) spendere su infrastrutture.





