Dagli esperimenti 🧪 al rilascio 🚀 MLflow 101 | Parte 02
Esperimenti e rilascio MLflow 101 | Parte 02
Potenzia il tuo percorso di MLOps creando un filtro antispam usando Streamlit e MLflow

Ciao là 👋, e un caloroso benvenuto al secondo segmento di questo blog! Se sei stato con noi fin dall’inizio, saprai che nella prima parte abbiamo creato un’interfaccia utente per semplificare il tuning degli iperparametri. Ora, riprendiamo da dove eravamo rimasti ⛔ Ma hey, se sei appena arrivato qui, non preoccuparti! Puoi recuperare leggendo la Parte 01 di questo blog qui 👇
Dagli esperimenti 🧪 al deploy 🚀: MLflow 101
Potenzia il tuo percorso di MLOps creando un filtro antispam usando Streamlit e MLflow
pub.towardsai.net
Sezione 2: Sperimenta 🧪 e Osserva 🔍 [Continua…]
Tracciamento degli esperimenti con MLflow 📊
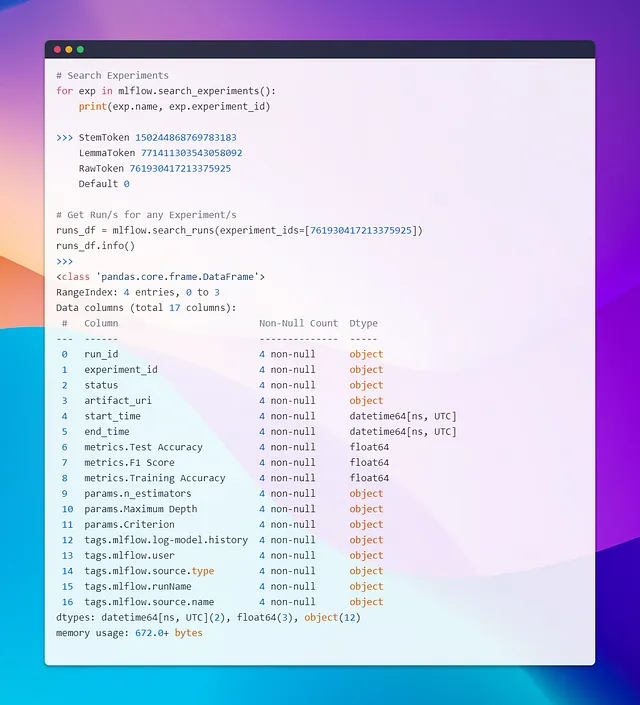
Ora che la nostra app è pronta, procediamo agli esperimenti. Per il primo esperimento, userò le parole nella loro forma grezza senza stemming o lemmatizzazione, concentrandomi solo sulla rimozione delle stop words e della punteggiatura, e applicando Bag of Words (BOW) ai dati di testo per la rappresentazione testuale. Successivamente, in esecuzioni successive, regolerò alcuni iperparametri. Chiameremo questo esperimento RawToken.
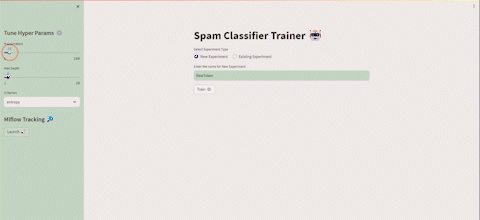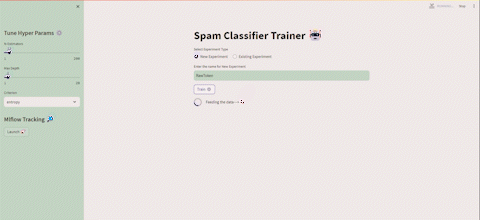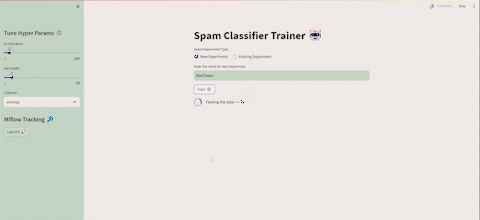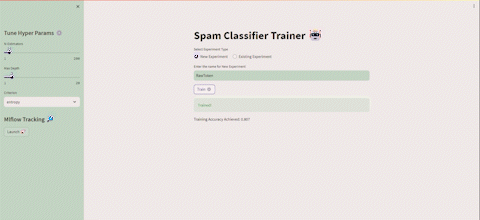
Dopo aver eseguito alcune esecuzioni, possiamo avviare MLflow dall’interfaccia utente di Streamlit e apparirà qualcosa del genere 👇
- I ricercatori creano un sistema di protezione dello schermo per respingere gli spettatori indesiderati
- Nvidia lancia un chip di intelligenza artificiale rivoluzionario per potenziare le applicazioni di intelligenza artificiale generativa
- Foglio di riferimento dei migliori strumenti Python per la creazione di applicazioni AI generative
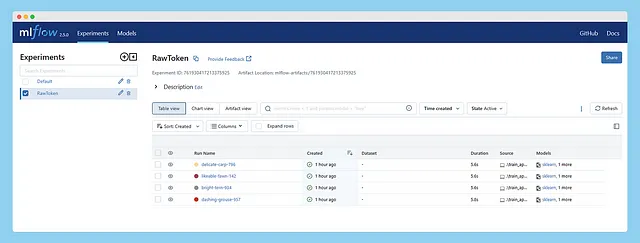
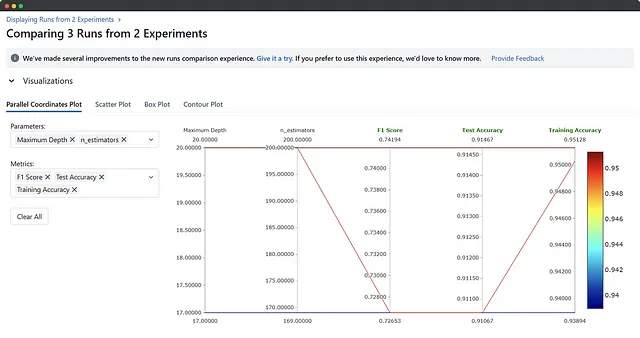
Bene, ora abbiamo l’esperimento RawToken elencato sotto Esperimenti e una serie di esecuzioni sotto la colonna Esecuzione, tutte associate a questo esperimento. Puoi selezionare una, un paio o tutte le esecuzioni e premere il pulsante Confronta per visualizzarne i risultati fianco a fianco. Una volta all’interno della sezione di confronto, puoi selezionare le metriche o i parametri che desideri confrontare o visualizzare.
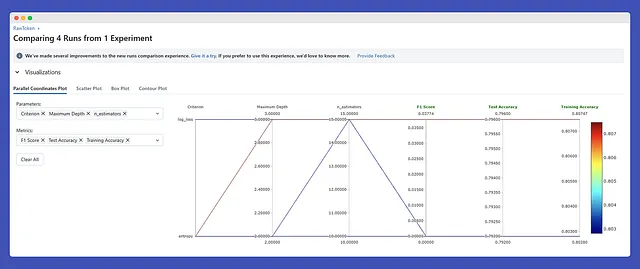
C’è molto da esplorare più di quanto tu possa immaginare, e capirai il miglior approccio una volta sapere cosa stai cercando e perché!

Bene, abbiamo completato un esperimento, ma non è andato come previsto, e va bene! Ora, dobbiamo ottenere alcuni risultati con almeno un punteggio F1 per evitare potenziali imbarazzi. Sapevamo che questo sarebbe successo dato che abbiamo usato token grezzi e mantenuto il numero di alberi e la profondità piuttosto bassi. Quindi, immergiamoci in un paio di nuovi esperimenti, uno con lo stemming e l’altro con la lemmatizzazione. All’interno di questi esperimenti, proveremo diverse combinazioni di iperparametri accoppiati con diverse tecniche di rappresentazione del testo.
Non andrò in modalità professionale completa qui perché il nostro obiettivo è diverso, e solo un gentile promemoria che non ho implementato l’integrazione di Git. Il tracciamento degli esperimenti con Git potrebbe essere ideale, ma richiederà alcune modifiche nel codice, che ho già commentato. MLflow può tenere traccia anche di Git, ma aggiungerlo comporterebbe una serie di screenshot aggiuntivi, e so che sei un mago di Git, quindi te lo lascio a te!
Ora, commentiamo manualmente e decommentiamo un po’ di codice per aggiungere questi due nuovi esperimenti e registrare alcune esecuzioni all’interno di essi. Dopo aver passato in rassegna tutto ciò che ho appena detto, ecco gli esperimenti e i loro risultati. Vediamo come va! 🚀🔥
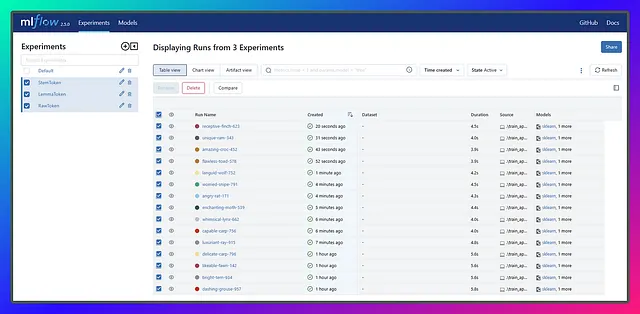
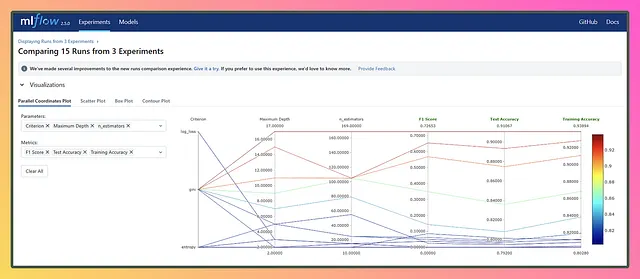
Ora che abbiamo finito con i nostri esperimenti, le nostre esecuzioni potrebbero sembrare un po’ disordinate e caotiche, proprio come i casi d’uso reali. Riesci a immaginare di fare tutto questo manualmente? Sarebbe un incubo, e probabilmente finiremmo le note adesive o avremmo bisogno di una scorta infinita di antidolorifici! Ma grazie a MLflow, siamo coperti e si occupa di tutto il disordine dei nostri esperimenti selvaggi, lasciandoci con una soluzione pulita e organizzata. Apprezziamo la magia di MLflow! 🧙♀️✨
Selezionare modelli tramite query di esperimento → RunID🎯
Ora, diciamo che abbiamo finito con alcuni esperimenti e ora abbiamo bisogno di caricare un modello da un esperimento e da una esecuzione specifici. L’obiettivo è recuperare il run_id e caricare gli artefatti (il modello e il vectorizer) associati a quel run id. Un modo per realizzare questo è cercare gli esperimenti, ottenere i loro id, quindi cercare le esecuzioni all’interno di quegli esperimenti. Puoi filtrare i risultati in base a metriche come l’accuratezza e selezionare il run id di cui hai bisogno. Dopo di che, puoi caricare gli artefatti utilizzando le funzioni di MLflow.
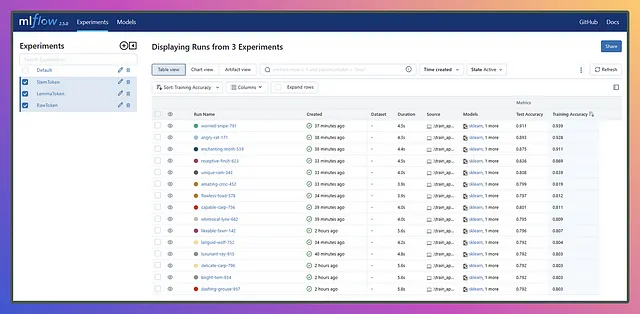
Un’opzione più semplice è utilizzare direttamente l’interfaccia utente di MLflow, dove puoi confrontare i risultati in ordine decrescente, prendere il run id dal risultato in cima e ripetere il processo.
Un altro metodo semplice e standard è distribuire modelli in produzione, che copriremo nell’ultima sezione del blog.
La mia intenzione dietro il primo approccio era di familiarizzare con la query degli esperimenti, poiché a volte potresti avere bisogno di un cruscotto personalizzato o grafici invece delle funzionalità integrate di MLflow. Utilizzando l’interfaccia utente di MLflow, puoi creare facilmente visualizzazioni personalizzate per soddisfare le tue esigenze specifiche. Si tratta di esplorare diverse opzioni per rendere il tuo viaggio con MLflow ancora più efficiente ed efficace!
Ora che abbiamo ottenuto il run_id, possiamo caricare il modello e effettuare previsioni tramite varie API. MLflow utilizza un formato specifico chiamato flavors per diverse librerie. Puoi anche creare il tuo flavor personalizzato, ma è un argomento separato da esplorare. In ogni caso, quando fai clic su un modello in MLflow, verranno visualizzate istruzioni su come caricarlo.
Carichiamo uno dei nostri modelli per effettuare una previsione rapida e vedere come funziona in azione!
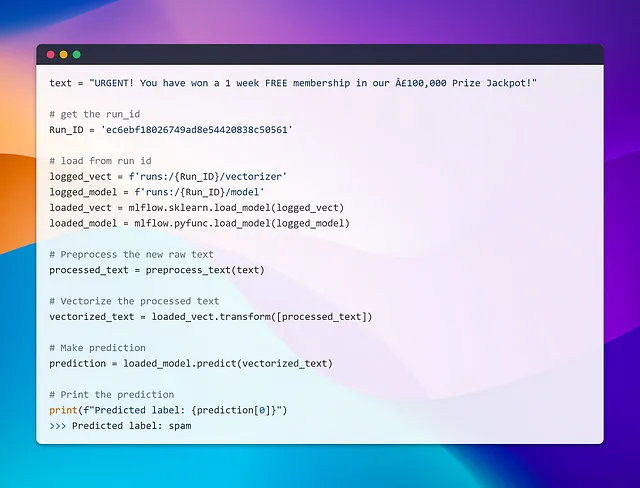
Wow!! Quello è stato facile! Caricare un modello da 15 esecuzioni diverse è stato un gioco da ragazzi. Tutto quello che abbiamo dovuto fare è fornire l’ID dell’esecuzione e non c’era bisogno di ricordare percorsi complessi o cose del genere. Ma aspetta, è tutto qui? Come serviamo i modelli o li distribuiamo? Approfondiamo questo argomento nella prossima sezione ed esploriamo il mondo della distribuzione e del servizio dei modelli.
Sezione 3: Distribuzione del Modello in Produzione 🚀
Benvenuti all’ultima sezione! Saltiamo subito senza perdere tempo. Una volta deciso il modello che vogliamo utilizzare, tutto ciò che resta da fare è selezionarlo e registrarlo con un nome univoco. Nelle versioni precedenti di MLflow, la registrazione di un modello richiedeva un database, ma non più. Ora è molto più semplice, e dovrò scrivere un po’ meno a riguardo.
Registrazione del Miglior Modello 🎖️
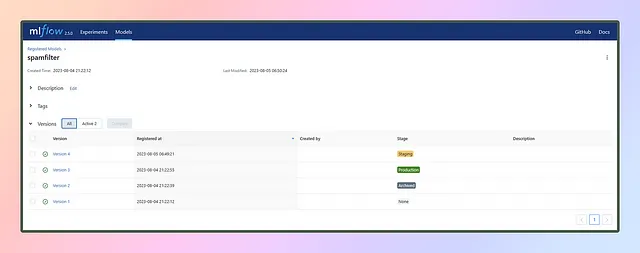
Il punto chiave qui è mantenere il nome del modello semplice e univoco. Questo nome sarà cruciale per future attività come il ritraining o l’aggiornamento dei modelli. Ogni volta che abbiamo un nuovo modello risultante da esperimenti di successo con buone metriche, lo registriamo con lo stesso nome. MLflow registra automaticamente il modello con una nuova versione e continua ad aggiornarlo.
In questa sezione, registriamo tre modelli basati sul grafico di accuratezza dei test: uno in fondo, uno in mezzo e l’ultimo in cima. Chiameremo il modello spamfilter
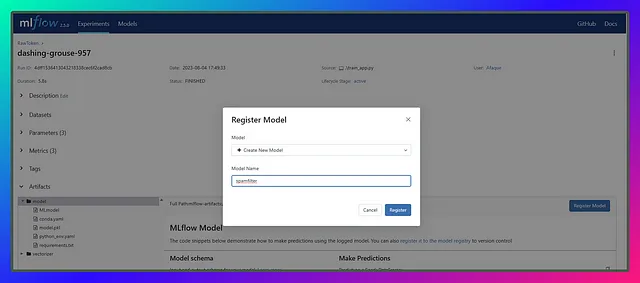
Una volta registrati i modelli di diverse esecuzioni con lo stesso nome del modello, verranno aggiunte versioni come questa 👇
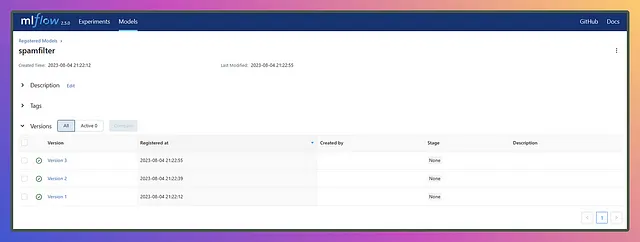
Quindi, è la fine del percorso una volta registrato il modello? La risposta è no! La registrazione del modello è solo un passo nel ciclo di vita dell’apprendimento automatico, ed è da qui che entra in gioco MLOps, o più specificamente, il flusso di lavoro CI/CD.

Dopo aver registrato i modelli in MLflow, i passaggi successivi coinvolgono tipicamente: ⚠️ Teoria Avanti ⚠️
- Staging e Validazione 🟨: Viene fatto prima della fase di deployment, e il modello registrato viene sottoposto a test e validazione. Questo passaggio garantisce che il modello si comporti come previsto e soddisfi gli standard di qualità richiesti prima di essere distribuito in produzione.
- Deployment 🟩: Dopo una valida validazione, il modello viene distribuito in un ambiente di produzione o in un’infrastruttura di servizio. Il modello diventa accessibile agli utenti finali o alle applicazioni e inizia a fornire previsioni in tempo reale.
- Monitoraggio e Manutenzione ⛑️: Una volta che il modello è in produzione, è essenziale monitorarne regolarmente le prestazioni. Il monitoraggio aiuta a rilevare eventuali variazioni nelle prestazioni del modello, cambiamenti nella distribuzione dei dati o eventuali problemi che possono sorgere durante l’uso nel mondo reale. Potrebbero essere necessari regolari interventi di manutenzione e aggiornamenti al modello per garantire che continui a fornire risultati accurati.
- Ritraining ⚙️: Con l’arrivo di nuovi dati, il ritraining regolare del modello diventa essenziale per tenerlo aggiornato e migliorarne le prestazioni. Un esempio recente è come GPT-4 abbia cominciato a mostrare un calo delle prestazioni nel tempo. In tali scenari, la funzionalità di tracciamento di MLflow si rivela preziosa aiutandoti a tenere traccia delle varie versioni del modello. Semplifica gli aggiornamenti e il ritraining del modello, garantendo che i tuoi modelli rimangano efficienti e accurati man mano che i dati evolvono.
- Versionamento del Modello 🔢: Come abbiamo visto in precedenza, quando registriamo un nuovo modello, MLflow lo versiona automaticamente. Nel caso di un modello ritrained o appena addestrato, viene anche sottoposto a versionamento e passa attraverso la fase di staging. Se il modello supera tutti i controlli necessari, viene preparato per la produzione. Tuttavia, se il modello inizia a funzionare male, il versionamento del modello e la cronologia del tracciamento di MLflow vengono in soccorso. Consentono facili rollback alle versioni precedenti del modello, consentendoci di tornare a un modello più affidabile e accurato se necessario. Questa capacità garantisce che possiamo mantenere le prestazioni del modello e apportare modifiche se necessario per fornire i migliori risultati ai nostri utenti o alle nostre applicazioni.
- Retroazione e Miglioramento: Utilizzare i feedback degli utenti e i dati di monitoraggio delle prestazioni può portare a miglioramenti continui del modello. Le informazioni acquisite dall’uso nel mondo reale consentono affinamenti e ottimizzazioni iterative, garantendo che il modello si evolva per offrire risultati migliori nel tempo.
Va bene allora! Basta chiacchiere e gergo teorico!! Abbiamo finito con quello, e la noia non è invitata a questa festa. È ora di liberare il codice ⚡ Mettiamoci le mani in pasta e divertiamoci davvero! 🚀💻. Qui sto lavorando da solo, non sono vincolato dai limiti di qualità o dalle restrizioni del team di testing 😉. Anche se non comprendo appieno il significato della fase gialla (Staging per la convalida), darò un salto e passerò direttamente alla fase verde. Anche se questo approccio potrebbe essere rischioso in uno scenario reale, nel mio mondo sperimentale sono disposto a correre il rischio.
Quindi con pochi clic, imposto la fase del mio modello versione 3 su produzione, e vediamo come possiamo interrogare il modello di produzione.
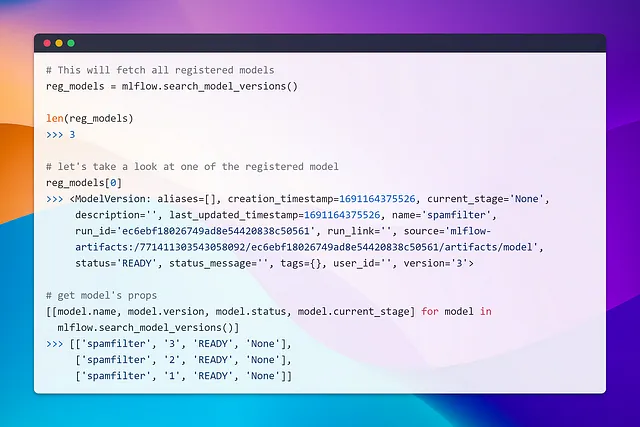
Allo stesso modo, possiamo eseguire una query e, filtrando la condizione current_stage == 'Produzione', possiamo recuperare il modello. Proprio come abbiamo fatto nella sezione precedente, possiamo usare model.run_id per procedere. Si tratta di sfruttare ciò che abbiamo imparato! 💡
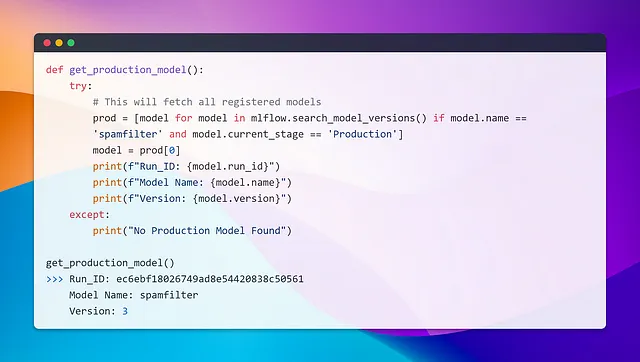
In alternativa, è anche possibile caricare un modello di produzione utilizzando il seguente snippet.
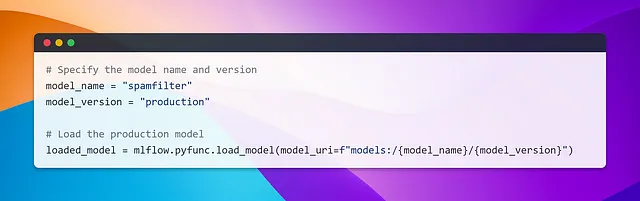
Costruire un’interfaccia utente Streamlit per le previsioni degli utenti
Ora che il nostro modello di produzione è distribuito, il passo successivo è renderlo disponibile attraverso un’API. MLflow fornisce un’API REST predefinita per effettuare previsioni utilizzando il modello registrato, ma ha opzioni di personalizzazione limitate. Per avere maggiore controllo e flessibilità, possiamo utilizzare framework web come FastAPI o Flask per creare endpoint personalizzati.
A scopo dimostrativo, utilizzerò nuovamente Streamlit per mostrare alcune informazioni sui modelli di produzione. Inoltre, esploreremo come un nuovo modello proveniente da un esperimento potrebbe potenzialmente sostituire quello precedente se si comporta meglio. Ecco il codice per l’applicazione utente chiamata user_app.py

L’interfaccia utente dell’app avrà un aspetto simile a questo 😎
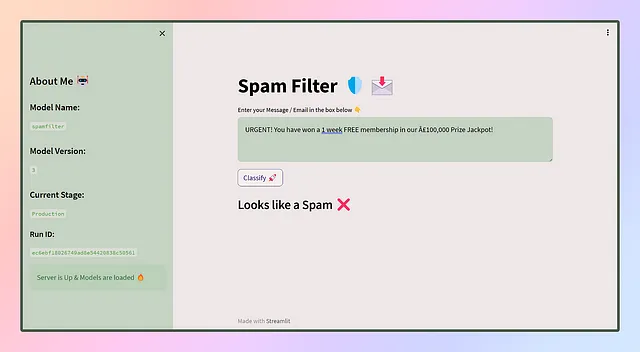
Wow, abbiamo distribuito con successo la nostra prima app! Ma aspetta, il viaggio non finisce qui. Ora che l’app viene servita agli utenti, interagiranno con essa utilizzando dati diversi, che daranno luogo a previsioni diverse. Queste previsioni vengono registrate attraverso vari mezzi, come feedback, valutazioni e altro ancora. Tuttavia, col passare del tempo, il modello potrebbe perdere efficacia, ed è qui che arriva il momento della riaddestramento.
Il riaddestramento comporta il ritorno alla fase iniziale, eventualmente con nuovi dati o algoritmi, per migliorare le prestazioni del modello.
Dopo il ritraining, mettiamo i nuovi modelli alla prova rispetto al modello in produzione e, se mostrano un miglioramento significativo, vengono messi in coda nell’area di Staging 🟨 per la validazione e i controlli di qualità.
Una volta ottenuta l’approvazione, vengono spostati nella fase di Produzione 🟩, sostituendo il modello attualmente in uso. Il modello di produzione precedente viene quindi archiviato ⬛.
Nota: Abbiamo la flessibilità di distribuire contemporaneamente più modelli in produzione. Ciò significa che possiamo offrire modelli diversi con qualità e funzionalità variabili, personalizzati per soddisfare abbonamenti o requisiti specifici. Si tratta di personalizzare l’esperienza dell’utente alla perfezione!
Ora, sposta questa ultima esecuzione nella fase di produzione e aggiorna la nostra app 🔄️
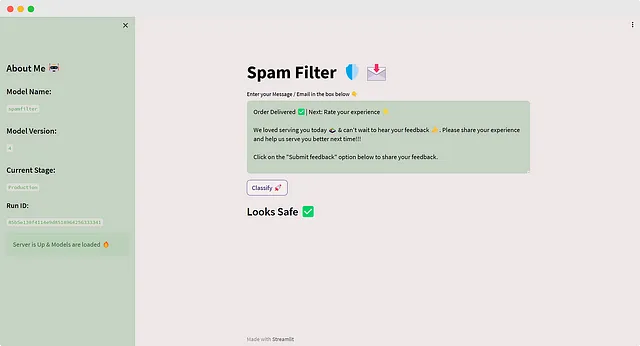
Riflette le ultime modifiche, ed è esattamente così che i modelli vengono serviti nel mondo reale. Questi sono i fondamenti di CI/CD – Continuous Integration e Continuous Deployment. Questa è MLOps. Abbiamo fatto tutto perfettamente! 🎉
E questo conclude questo lungo blog! Ma ricorda, questo è solo un piccolo passo nel vasto mondo di MLOps. Il percorso che ci attende coinvolge l’hosting della nostra app nel cloud, la collaborazione con gli altri e la distribuzione dei modelli tramite API. Mentre ho utilizzato Streamlit esclusivamente in questo blog, hai la libertà di esplorare altre opzioni come FastAPI o Flask per la creazione di endpoint. Puoi persino combinare Streamlit con FastAPI per scollegare e collegare con il tuo pipeline preferito. Se hai bisogno di un ripasso, ho tutto sotto controllo con uno dei miei blog precedenti che illustra come fare proprio questo!
Streamlit🔥+ FastAPI⚡️- Gli ingredienti di cui hai bisogno per la tua prossima ricetta di Data Science
Streamlit è un framework open-source, gratuito, completamente in Python per la creazione rapida e la condivisione di dashboard interattive e app web…
VoAGI.com
Ehi, ehi, ehi! Abbiamo raggiunto il traguardo, ragazzi! Ecco il Repository GitHub per tutto questo progetto 👇
GitHub – afaqueumer/mlflow101
Contribuisci a afaqueumer/mlflow101 sviluppando un account su GitHub.
github.com
Spero che questo blog abbia portato sorrisi e conoscenza. Se ti sei divertito a leggerlo e lo hai trovato utile, non dimenticare di seguire il sottoscritto, Afaque Umer, per altri articoli emozionanti.
Rimani sintonizzato per altre avventure entusiasmanti nel mondo dell’Apprendimento Automatico e della Scienza dei Dati. Mi assicurerò di spiegarti in modo semplice quei termini che sembrano così complicati.
Ok, ok, ok! È ora di dire addio 👋





