Plotly e Pandas Unire le Forze per una Efficace Visualizzazione dei Dati
Plotly e Pandas una Visualizzazione Efficace dei Dati
Una guida rapida ispirata a Storytelling with Data
“Le mie abilità di visualizzazione dei dati sono scarse. Il mio pubblico sembra poco impressionato dal mio lavoro e, peggio ancora, non è convinto.”
C’è stato un tempo in cui molti di noi si sono imbattuti in questo problema. A meno che tu non sia dotato o abbia seguito un corso di design in precedenza, potrebbe essere piuttosto impegnativo e richiedere molto tempo produrre grafici visivamente estetici che siano intuitivi per il pubblico allo stesso tempo.
Ecco cosa mi è venuto in mente allora: voglio essere più intenzionale nel creare i miei grafici in modo che trasmettano informazioni al mio pubblico in modo intuitivo. Con questo intendo non far loro sforzare la mente e consumare eccessivamente il loro tempo per capire cosa sta succedendo.
Prima pensavo che passare da Matplotlib a Seaborn e infine a Plotly risolvesse il problema dell’estetica. In effetti, mi sbagliavo. La visualizzazione non riguarda solo l’estetica. Di seguito sono riportate due visualizzazioni che ho cercato di replicare da Storytelling with Data¹ di Cole Nussbaumer Knaflic che mi hanno davvero ispirato a cambiare il mio approccio alla visualizzazione. Sono pulite, eleganti e mirate. In questo articolo cercheremo di replicare questi grafici!
- L’ottimizzazione dietro SVM Forma Primale e Duale
- Async per LangChain e LLMs
- Crea la tua applicazione ChatGPT utilizzando Spring Boot
Ecco il messaggio principale di questo post. Se stai cercando una spiegazione approfondita dei concetti che stanno dietro a una grande visualizzazione, dai un’occhiata a Storytelling with Data¹, ogni pagina è un gioiello che vale il tuo tempo. Se stai cercando consigli specifici sugli strumenti e pratici, sei nel posto giusto. Cole ha menzionato all’inizio del suo libro che i consigli che ha presentato sono universali e indipendenti dagli strumenti, anche se ha ammesso di aver creato gli esempi nel libro utilizzando Excel. Alcune persone, me compreso, non sono fan di Excel e degli strumenti trascina-e-rilascia per molte ragioni. Alcuni preferiscono creare visualizzazioni utilizzando Python, R e altri linguaggi di programmazione. Se fai parte di questo segmento e utilizzi Python come tuo strumento principale, allora questo articolo fa al caso tuo.
Tabella dei contenuti
- Chaining—Pandas Plot
- Grafico a barre orizzontale
- Grafico a linee
- Bonus: Grafico numerico
Chaining—Pandas Plot
Se sei un esperto o un giocatore esperto nell’utilizzo di Pandas per la manipolazione dei dati, potresti incontrare o addirittura adottare l’idea di “Chaining” tu stesso. In breve, il chaining consente al tuo codice di essere molto più leggibile, più facile da debuggare e pronto per la produzione. Ecco un semplice esempio di ciò a cui mi riferisco. Non devi leggere riga per riga, dai solo un’occhiata veloce per capire l’idea dietro “Chaining”. Ogni passo è chiaro e facile da spiegare, e il codice è ben organizzato senza variabili intermedie superflue.
(epl_10seasons .rename(columns=lambda df_: df_.strip()) .rename(columns=lambda df_: re.sub('\W+|[!,*)@#%(&$_?.^]', '_', df_)) .pipe(lambda df_: df_.astype({column: 'int8' for column in (df_.select_dtypes("integer").columns.tolist())})) .pipe(lambda df_: df_.astype({column: 'category' for column in (df_.select_dtypes("object").columns.tolist()[:-1])})) .assign(match_date=lambda df_: pd.to_datetime(df_.match_date, infer_datetime_format=True)) .assign(home_team=lambda df_: np.where((df_.home_team == "Arsenal"), "The Gunners", df_.home_team), away_team=lambda df_: np.where((df_.away_team == "Arsenal"), "The Gunners", df_.away_team), month=lambda df_: df_.match_date.dt.month_name()) .query('home_team == "The Gunners"'))Questo è fantastico, ma sapevi che puoi continuare il processo di chaining per creare anche grafici di visualizzazione di base? Pandas Plot, per impostazione predefinita, utilizza Matplotlib come backend a questo scopo. Vediamo come funziona e riproduciamo alcuni degli esempi creati da Cole nel suo libro.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import plotly.graph_objects as go
%matplotlib inline
pd.options.plotting.backend = 'plotly'
df = pd.DataFrame({"preoccupazioni": ["La potenza del motore è inferiore alle aspettative",
"Le gomme fanno rumore eccessivo durante la guida",
"Il motore emette rumori anomali / eccessivi",
"Preoccupazioni sul materiale del sedile",
"Rumore eccessivo del vento",
"Esitazione o ritardo durante il cambio",
"Il sistema Bluetooth ha una scarsa qualità audio",
"Il sistema di sterzo / ruota ha troppo gioco",
"Il sistema Bluetooth è difficile da usare",
"Controlli audio / intrattenimento / navigazione del sedile anteriore"
],
"preoccupazioni per 1.000": [12.9, 12.3, 11.6, 11.6, 11.0, 10.3, 10.0, 8.8, 8.6, 8.2]
},
index=list(range(0,10,1)))
Abbiamo un DataFrame che appare così.

(df .plot .barh())Questa è il modo più veloce per generare un grafico di visualizzazione di base. Concatenando l’attributo .plot e il metodo .barh direttamente da un DataFrame, otteniamo il grafico sottostante.

Tieni a freno la tua reazione e il tuo giudizio se pensi che il grafico sopra non superi il controllo estetico. Infatti, sembra brutto, per non dire di peggio. Diamo un po’ di pepe e facciamo meglio. Ecco il trucco, passa il tuo backend di tracciamento di Pandas da Matplotlib a Plotly per la magia che sta per svelarsi.
pd.options.plotting.backend = 'plotly'Potresti chiederti: “Perché lo cambio a Plotly? Matplotlib non è in grado di fare la stessa cosa?” Beh, ecco la differenza.
Se usiamo il backend di Matplotlib in Pandas, restituisce un oggetto Axes, prova a verificarlo usando il metodo type() integrato. Questo è fantastico perché l’oggetto Axes ci consente di accedere a metodi per modificare ulteriormente il nostro grafico. Dai un’occhiata a questa documentazione² per i possibili metodi da eseguire sull’oggetto Axes. Prendiamone uno per illustrare rapidamente.
(df .plot .barh() .set_xlabel("preoccupazioni per 1.000"))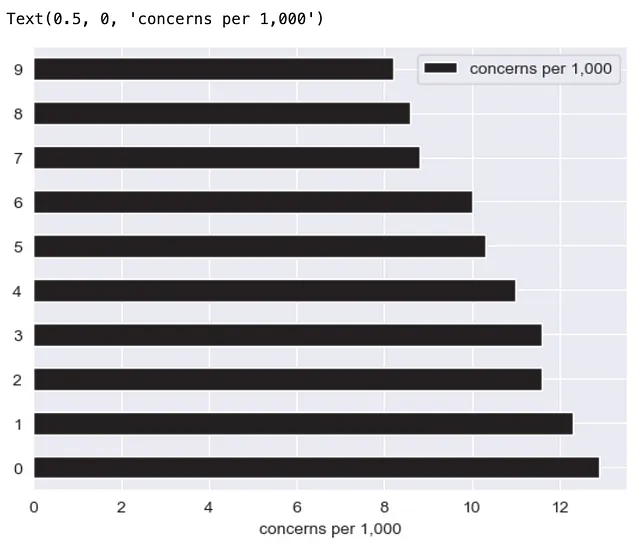
Siamo riusciti a impostare l’etichetta dell’asse x su “preoccupazioni per 1.000”, ma nel farlo, restituiamo un oggetto Text e perdiamo il nostro prezioso oggetto Axis che ci consente di accedere a metodi preziosi per modificare ulteriormente il nostro grafico. Peccato!
Ecco un’alternativa per aggirare la limitazione sopra descritta:
(df .plot .barh(xlabel="Preoccupazioni per 1.000", ylabel="Preoccupazioni", title="Le 10 principali preoccupazioni di design"))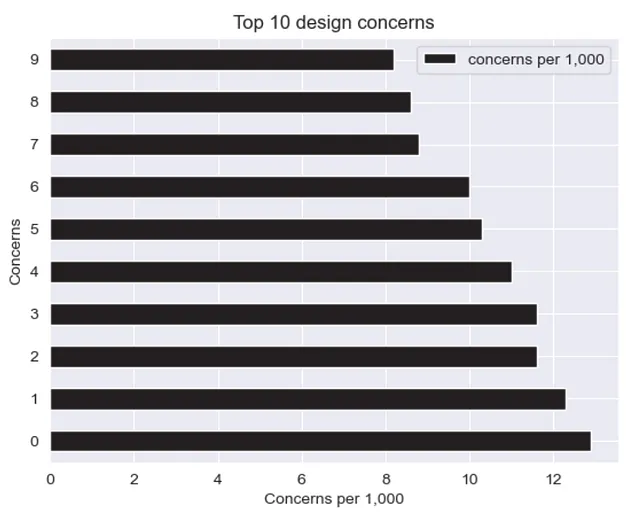
Tuttavia, siamo ancora in grado di apportare modifiche estensive poiché l’integrazione è piuttosto limitata dall’implementazione di Pandas qui.
Plotly, d’altra parte, non restituisce un oggetto Axes. Restituisce un oggetto go.Figure. La differenza qui è che i metodi responsabili dell’aggiornamento dei grafici restituiscono anche un oggetto go.Figure, che ti consente di continuare a concatenare il tuo metodo per aggiornare ulteriormente il tuo grafico. Proviamolo!
A proposito, nel caso ti stessi chiedendo come ottengo le combinazioni di metodi e argomenti qui sotto, sono tutti disponibili nella documentazione ufficiale qui³.
Ecco alcuni metodi importanti per iniziare: .update_traces, .add_traces, .update_layout, .update_xaxes, .update_yaxes, .add_annotation, .update_annotations.
Grafico a Barre Orizzontali
Definiamo un set di tabelle di colori per la nostra visualizzazione qui sotto.
GRAY1, GRAY2, GRAY3 = '#231F20', '#414040', '#555655'GRAY4, GRAY5, GRAY6 = '#646369', '#76787B', '#828282'GRAY7, GRAY8, GRAY9, GRAY10 = '#929497', '#A6A6A5', '#BFBEBE', '#FFFFFF'BLUE1, BLUE2, BLUE3, BLUE4, BLUE5 = '#25436C', '#174A7E', '#4A81BF', '#94B2D7', '#94AFC5'BLUE6, BLUE7 = '#92CDDD', '#2E869D'RED1, RED2, RED3 = '#B14D4A', '#C3514E', '#E6BAB7'GREEN1, GREEN2 = '#0C8040', '#9ABB59'ORANGE1, ORANGE2, ORANGE3 = '#F36721', '#F79747', '#FAC090'gray_palette = [GRAY1, GRAY2, GRAY3, GRAY4, GRAY5, GRAY6, GRAY7, GRAY8, GRAY9, GRAY10]blue_palette = [BLUE1, BLUE2, BLUE3, BLUE4, BLUE5, BLUE6, BLUE7]red_palette = [RED1, RED2, RED3]green_palette = [GREEN1, GREEN2]orange_palette = [ORANGE1, ORANGE2, ORANGE3]sns.set_style("darkgrid")sns.set_palette(gray_palette)sns.palplot(sns.color_palette())
Qui, vogliamo evidenziare le preoccupazioni che sono pari o superiori al 10 percento definendo un colore separato.
color = np.array(['rgb(255,255,255)']*df.shape[0])color[df .set_index("preoccupazioni", drop=True) .iloc[::-1] ["preoccupazioni per 1.000"]>=10] = red_palette[0]color[df .set_index("preoccupazioni", drop=True) .iloc[::-1] ["preoccupazioni per 1.000"]<10] = gray_palette[4]Poi creiamo il grafico direttamente dal DataFrame.
(df .set_index("preoccupazioni", drop=True) .iloc[::-1] .plot .barh() .update_traces(marker=dict(color=color.tolist())))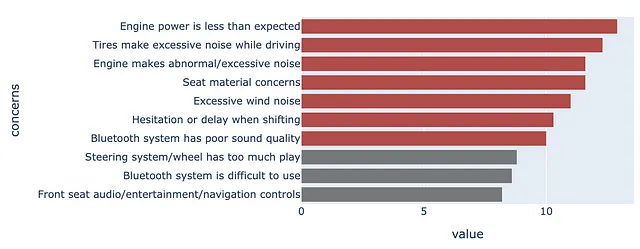
Aggiornando il layout otteniamo quanto segue. Qui, specifichiamo il template, aggiungiamo un titolo e un margine al nostro grafico, e specifichiamo la dimensione del nostro oggetto figura. Commentiamo le annotazioni per il momento.
(df .set_index("preoccupazioni", drop=True) .iloc[::-1] .plot .barh() .update_traces(marker=dict(color=color.tolist())) .update_layout(template="plotly_white", title=dict(text="<b>Top 10 preoccupazioni di design</b> <br><sup><i>preoccupazioni per 1.000</i></sup>", font_size=30, font_color=gray_palette[4]), margin=dict(l=50, r=50, b=50, t=100, pad=20), width=1000, height=800, showlegend=False, #annotations=annotations ))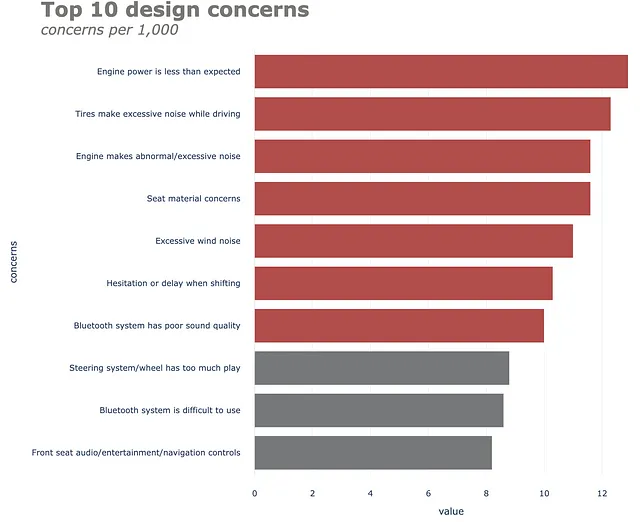
Aggiornando le proprietà degli assi x e y otteniamo quanto segue.
(df .set_index("preoccupazioni", drop=True) .iloc[::-1] .plot .barh() .update_traces(marker=dict(color=color.tolist())) .update_layout(template="plotly_white", title=dict(text="<b>Top 10 preoccupazioni di design</b> <br><sup><i>preoccupazioni per 1.000</i></sup>", font_size=30, font_color=gray_palette[4]), margin=dict(l=50, r=50, b=50, t=100, pad=20), width=1000, height=800, showlegend=False, #annotations=annotations ) .update_xaxes(title_standoff=10, showgrid=False, visible=False, tickfont=dict( family='Arial', size=16, color=gray_palette[4],), title="") .update_yaxes(title_standoff=10, tickfont=dict( family='Arial', size=16, color=gray_palette[4],), title=""))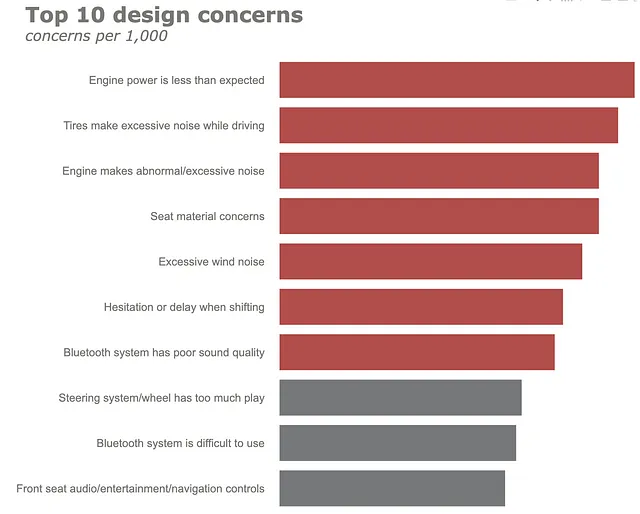
Ultimo ma non meno importante, aggiungeremo alcune annotazioni al nostro grafico. Qui abbiamo alcune annotazioni – aggiungere etichette dati al grafico a barre orizzontali e una nota a piè di pagina. Facciamolo insieme. Per prima cosa, definiamo le annotazioni in una cella separata.
annotations = []y_s = np.round(df["preoccupazioni per 1.000"], decimals=2)# Aggiunta etichette datifor yd, xd in zip(y_s, df.preoccupazioni): # etichettatura del patrimonio netto della barra annotations.append(dict(xref='x1', yref='y1', y=xd, x=yd - 1, text=str(yd) + '%', font=dict(family='Arial', size=16, color=gray_palette[-1]), showarrow=False)) # Aggiunta annotazioni al sorgenteannotations.append(dict(xref='paper', yref='paper', x=-0,72, y=-0,050, text='Fonte: Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco' '<br>laboris nisi ut aliquip ex ea commodo consequat.', font=dict(family='Arial', size=10, color=gray_palette[4]), showarrow=False, align='left'))
(df .set_index("preoccupazioni", drop=True) .iloc[::-1] .plot .barh() .update_traces(marker=dict(color=color.tolist())) .update_layout(template="plotly_white", title=dict(text="<b>Top 10 preoccupazioni di design</b> <br><sup><i>preoccupazioni per 1.000</i></sup>", font_size=30, font_color=gray_palette[4]), margin=dict(l=50, r=50, b=50, t=100, pad=20), width=1000, height=800, showlegend=False, annotations=annotations ) .update_xaxes(title_standoff=10, showgrid=False, visible=False, tickfont=dict( family='Arial', size=16, color=gray_palette[4],), title="") .update_yaxes(title_standoff=10, tickfont=dict( family='Arial', size=16, color=gray_palette[4],), title=""))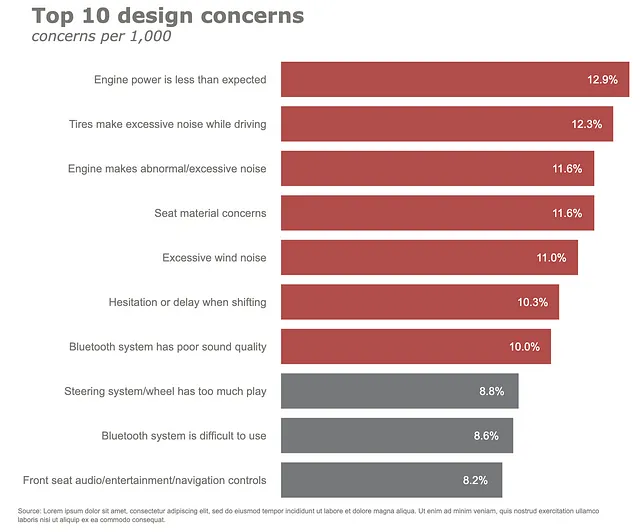
Non è questo un grafico molto migliore rispetto alla versione predefinita iniziale? Continuiamo a esplorare un altro grafico popolare – il grafico a linea.
Un piccolo avviso che l’esempio sottostante è più complicato di quello precedente. Tuttavia, l’idea rimane la stessa.
Grafico a Linee
Diamo un’occhiata veloce alla libreria di plot predefinita di Matplotlib per il grafico a linea.
pd.options.plotting.backend = 'matplotlib'df = pd.DataFrame({"Ricevuti": [160,184,241,149,180,161,132,202,160,139,149,177], "Elaborati":[160,184,237,148,181,150,123,156,126,104,124,140]}, index=['Gen', 'Feb', 'Mar', 'Apr', 'Mag', 'Giu', 'Lug', 'Ago', 'Set', 'Ott', 'Nov', 'Dic'])(df .plot .line());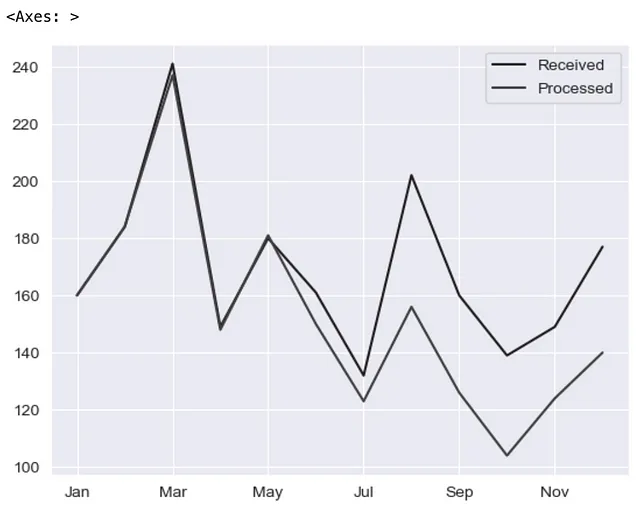
Cambiamo il nostro plot backend in Plotly!
pd.options.plotting.backend = 'plotly'(df .plot(x=df.index, y=df.Ricevuti, labels=dict(index="", value="Numero di ticket"),))Dopo aver cambiato il plot backend di Pandas in Plotly, il codice sopra ci restituisce quanto segue. Qui, iniziamo tracciando solo la Serie Ricevuti.
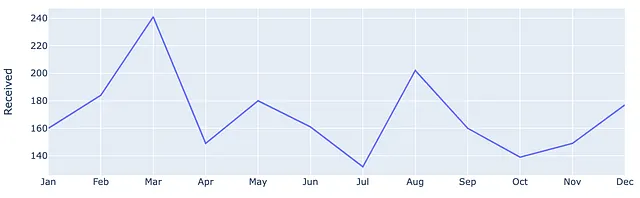
Aggiorniamo la proprietà line concatenando ulteriormente il metodo precedente. Qui, modifichiamo il colore, la larghezza e posizioniamo i marcatori sui punti dei dati.
(df .plot(x=df.index, y=df.Ricevuti, labels=dict(index="", value="Numero di ticket"),) .update_traces(go.Scatter(mode='lines+markers+text', line={"color": gray_palette[4], "width":4}, marker=dict(size=12)),))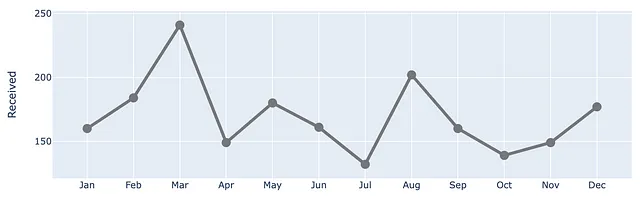
Aggiungiamo la Serie Elaborati al grafico!
(df .plot(x=df.index, y=df.Ricevuti, labels=dict(index="", value="Numero di ticket"),) .update_traces(go.Scatter(mode='lines+markers+text', line={"color": gray_palette[4], "width":4}, marker=dict(size=12)),) .add_traces(go.Scatter(x=df.index, #Aggiungi colonna Elaborati y=df.Elaborati, mode="lines+markers+text", line={"color": blue_palette[0], "width":4}, marker=dict(size=12))))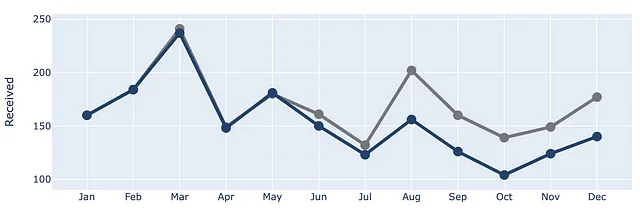
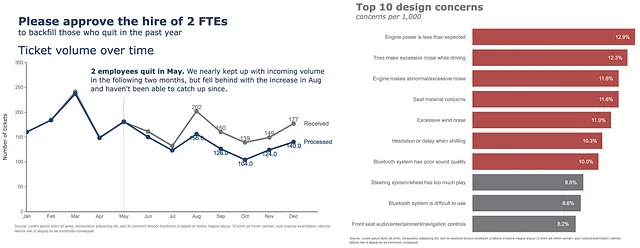
Aggiungiamo una linea verticale all’indice Maggio per mostrare il punto in cui le due linee iniziano a divergere.
(df .plot(x=df.index, y=df.Ricevuti, labels=dict(index="", value="Numero di ticket"),) .update_traces(go.Scatter(mode='lines+markers+text', line={"color": gray_palette[4], "width":4}, marker=dict(size=12)),) .add_traces(go.Scatter(x=df.index, #Aggiungi colonna Elaborati y=df.Elaborati, mode="lines+markers+text", line={"color": blue_palette[0], "width":4}, marker=dict(size=12))) .add_traces(go.Scatter(x=["Maggio", "Maggio"], #Aggiungi vline y=[0,230], fill="toself", mode="lines", line_width=0.5, line_color= gray_palette[4])))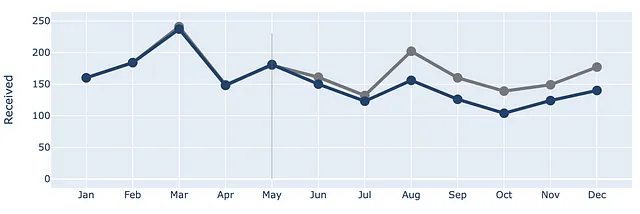
Successivamente, aggiorniamo il layout generale cambiando lo sfondo in bianco e aggiungendo il titolo, il margine e alcuni altri elementi. Per le annotazioni, le commenteremo per il momento.
(df .plot(x=df.index, y=df.Received, labels=dict(index="", value="Numero di ticket"),) .update_traces(go.Scatter(mode='lines+markers+text', line={"color": gray_palette[4], "width":4}, marker=dict(size=12)),) .add_traces(go.Scatter(x=df.index, #Aggiungi colonna Processed y=df.Processed, mode="lines+markers+text", line={"color": blue_palette[0], "width":4}, marker=dict(size=12))) .add_traces(go.Scatter(x=["Maggio", "Maggio"], #Aggiungi vline y=[0,230], fill="toself", mode="lines", line_width=0.5, line_color= gray_palette[4])) .update_layout(template="plotly_white", title=dict(text="<b>Si prega di approvare l'assunzione di 2 FTE</b> <br><sup>per sostituire quelli che hanno lasciato l'anno scorso</sup> <br>Volume di ticket nel tempo <br><br><br>", font_size=30,), margin=dict(l=50, r=50, b=100, t=200,), width=900, height=700, yaxis_range=[0, 300], showlegend=False, #annotations=right_annotations, ))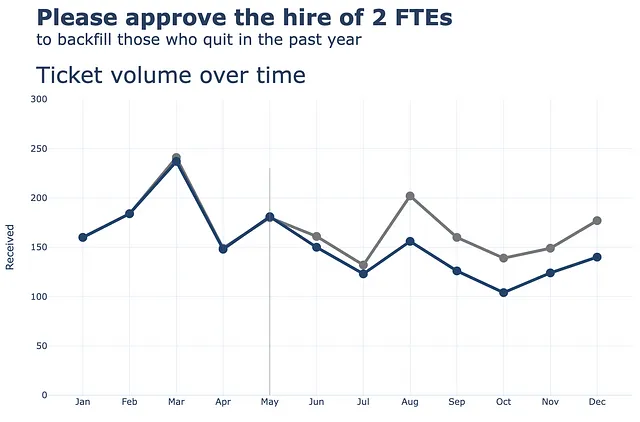
Successivamente, effettueremo un aggiornamento sia degli assi x che degli assi y.
(df .plot(x=df.index, y=df.Received, labels=dict(index="", value="Numero di ticket"),) .update_traces(go.Scatter(mode='lines+markers+text', line={"color": gray_palette[4], "width":4}, marker=dict(size=12)),) .add_traces(go.Scatter(x=df.index, #Aggiungi colonna Processed y=df.Processed, mode="lines+markers+text", line={"color": blue_palette[0], "width":4}, marker=dict(size=12))) .add_traces(go.Scatter(x=["Maggio", "Maggio"], #Aggiungi vline y=[0,230], fill="toself", mode="lines", line_width=0.5, line_color= gray_palette[4])) .update_layout(template="plotly_white", title=dict(text="<b>Si prega di approvare l'assunzione di 2 FTE</b> <br><sup>per sostituire quelli che hanno lasciato l'anno scorso</sup> <br>Volume di ticket nel tempo <br><br><br>", font_size=30,), margin=dict(l=50, r=50, b=100, t=200,), width=900, height=700, yaxis_range=[0, 300], showlegend=False, #annotations=right_annotations, ) .update_xaxes(dict(range=[0, 12], showline=True, showgrid=False, linecolor=gray_palette[4], linewidth=2, ticks='', tickfont=dict( family='Arial', size=13, color=gray_palette[4], ), )) .update_yaxes(dict(showline=True, showticklabels=True, showgrid=False, ticks='outside', linecolor=gray_palette[4], linewidth=2, tickfont=dict( family='Arial', size=13, color=gray_palette[4], ), title_text="Numero di ticket" )))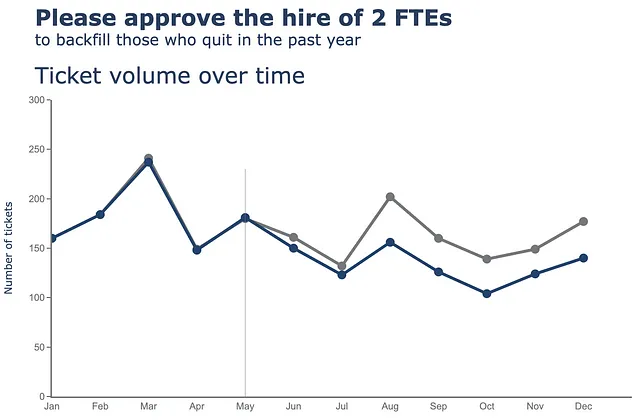
Ultimo ma non meno importante, aggiungeremo alcune annotazioni al nostro grafico. Qui abbiamo alcune annotazioni: aggiungere etichette al grafico a linee (Received, Processed), oltre che aggiungere etichette ai punti dello scatter plot, che potrebbe essere un po’ complicato. Facciamolo insieme. Prima di tutto, definiamo le annotazioni in una cella separata.
y_data = df.to_numpy()colors = [gray_palette[3], blue_palette[0]]labels = df.columns.to_list()right_annotations = []# Aggiungere etichette alla lineaper y_trace, label, color in zip(y_data[-1], labels, colors): right_annotations.append(dict(xref='paper', x=0.95, y=y_trace, xanchor='left', yanchor='middle', text=label, font=dict(family='Arial',size=16,color=color), showarrow=False))# Aggiungere etichette ai punti scatterscatter_annotations = []y_received = [each for each in df.Received]y_processed = [float(each) for each in df.Processed]x_index = [each for each in df.index]y_r = np.round(y_received)y_p = np.rint(y_processed)for ydn, yd, xd in zip(y_r[-5:], y_p[-5:], x_index[-5:]): scatter_annotations.append(dict(xref='x2 domain', yref='y2 domain', y=ydn, x=xd, text='{:,}'.format(ydn), font=dict(family='Arial',size=16,color=gray_palette[4]), showarrow=False, xanchor='center', yanchor='bottom', )) scatter_annotations.append(dict(xref='x2 domain', yref='y2 domain', y=yd, x=xd, text='{:,}'.format(yd), font=dict(family='Arial',size=16,color=blue_palette[0]), showarrow=False, xanchor='center', yanchor='top', ))Dopo aver definito le annotazioni, è sufficiente inserire la variabile di annotazione nel metodo di concatenazione come segue.
(df .plot(x=df.index, y=df.Received, labels=dict(index="", value="Numero di ticket"),) .update_traces(go.Scatter(mode='lines+markers+text', line={"color": gray_palette[4], "width":4}, marker=dict(size=12)),) .add_traces(go.Scatter(x=df.index, #Aggiungi colonna Processed y=df.Processed, mode="lines+markers+text", line={"color": blue_palette[0], "width":4}, marker=dict(size=12))) .add_traces(go.Scatter(x=["Maggio", "Maggio"], #Aggiungi vline y=[0,230], fill="toself", mode="lines", line_width=0.5, line_color= gray_palette[4])) .update_layout(template="plotly_white", title=dict(text="<b>Si prega di approvare l'assunzione di 2 FTE</b> <br><sup>per sostituire coloro che hanno lasciato l'anno scorso</sup> <br>Volume dei ticket nel tempo <br><br><br>", font_size=30,), margin=dict(l=50, r=50, b=100, t=200,), width=900, height=700, yaxis_range=[0, 300], showlegend=False, annotations=right_annotations, ) .update_layout(annotations=scatter_annotations * 2) .update_xaxes(dict(range=[0, 12], showline=True, showgrid=False, linecolor=gray_palette[4], linewidth=2, ticks='', tickfont=dict( family='Arial', size=13, color=gray_palette[4], ), )) .update_yaxes(dict(showline=True, showticklabels=True, showgrid=False, ticks='outside', linecolor=gray_palette[4], linewidth=2, tickfont=dict( family='Arial', size=13, color=gray_palette[4], ), title_text="Numero di ticket" )) .add_annotation(dict(text="<b>2 dipendenti hanno lasciato a maggio.</b> Ci siamo quasi tenuti al passo con il volume in entrata <br>nei due mesi successivi, ma siamo rimasti indietro con l'aumento ad agosto <br>e non siamo stati in grado di recuperare da allora.", font_size=18, align="left", x=7.5, y=265, showarrow=False)) .add_annotation(dict(xref='paper', yref='paper', x=0.5, y=-0.15, text='Fonte: Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco' '<br>laboris nisi ut aliquip ex ea commodo consequat.', font=dict(family='Arial', size=10, color='rgb(150,150,150)'), showarrow=False, align='left')) .update_annotations(yshift=0) .show())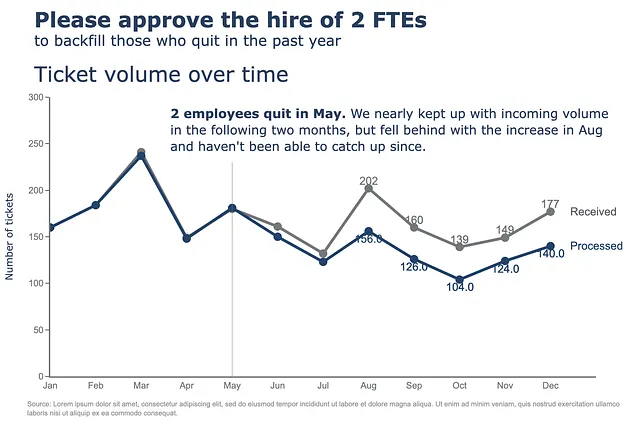
Bonus: Tabella dei Numeri
Congratulazioni per essere arrivato a questa parte dell’articolo! Ecco un ulteriore grafico che puoi portare via! Qui stiamo creando una tabella per rappresentare esteticamente un numero da solo. In breve, è a questo che mi riferisco.
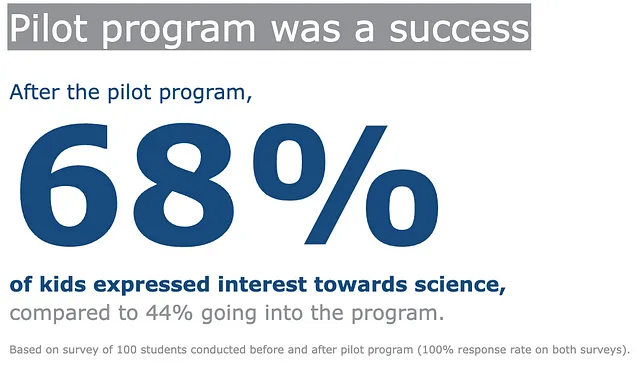
Dato che questo non è il risultato di un DataFrame, possiamo iniziare creando un oggetto vuoto go.Figure da zero, quindi gradualmente aggiungere le annotazioni. Infine, aggiorniamo il layout di conseguenza.
(go .Figure() # Creare un'immagine vuota .add_annotation( x=0.0, y=1, text='Il programma pilota è stato un successo', showarrow=False, font={'size': 36, 'color': 'white'}, bgcolor=gray_palette[-3], bordercolor='gray', borderwidth=0, xref='paper', yref='paper', xanchor='left', yanchor='top', align='left', ax=0, ay=-10 ) .add_annotation( x=-1.0, # Coordinata X della posizione del testo y=3.0, # Coordinata Y della posizione del testo text="Dopo il programma pilota,", # Contenuto del testo showarrow=False, # Nascondi la freccia font=dict(size=20, color=blue_palette[1]), # Personalizza la dimensione del font xanchor='left', yanchor='top', align='left', ) .add_annotation( x=-1.0, # Coordinata X della posizione del testo y=1.6, # Coordinata Y della posizione del testo text="<b>68%</b>", # Contenuto del testo showarrow=False, # Nascondi la freccia font=dict(size=160, color=blue_palette[1]), # Personalizza la dimensione del font xanchor='left', align='left', ) .add_annotation( x=-1.0, # Coordinata X della posizione del testo y=0.2, # Coordinata Y della posizione del testo text="<b>dei bambini ha mostrato interesse per la scienza,</b>", # Contenuto del testo showarrow=False, # Nascondi la freccia font=dict(size=20, color=blue_palette[1]), # Personalizza la dimensione del font xanchor='left', align='left', ) .add_annotation( x=-1.0, # Coordinata X della posizione del testo y=-0.2, # Coordinata Y della posizione del testo text="rispetto al 44% all'inizio del programma.", # Contenuto del testo showarrow=False, # Nascondi la freccia font=dict(size=20, color=gray_palette[-3]), # Personalizza la dimensione del font xanchor='left', align='left', ) .add_annotation( x=-1.0, # Coordinata X della posizione del testo y=-0.7, # Coordinata Y della posizione del testo text='Sulla base di un sondaggio di 100 studenti condotto ' 'prima e dopo il programma pilota ' '(tasso di risposta del 100% su entrambi i sondaggi).', # Contenuto del testo showarrow=False, # Nascondi la freccia font=dict(size=10.5, color=gray_palette[-3]), # Personalizza la dimensione del font xanchor='left', align='left', ) .update_layout( xaxis=dict(visible=False), # Nascondi l'asse x yaxis=dict(visible=False), # Nascondi l'asse y margin=dict(l=0, r=0, b=0, t=0, pad=0), font=dict(size=26, color=gray_palette[-3]), # Personalizza la dimensione del font paper_bgcolor='rgba(0,0,0,0)', plot_bgcolor='rgba(0,0,0,0)' ) .show())Postfazione
Ecco a te! La chiave è aggiornare e perfezionare il tuo grafico passo dopo passo fino a ottenere un risultato desiderabile. Ovviamente, ogni tecnica ha i suoi limiti. Se il tuo grafico sta diventando troppo complicato da produrre, potrebbe essere utile fare riferimento a Plotly Express o addirittura costruire tutto da zero utilizzando Plotly Graph Objects. Può sembrare difficile e poco familiare adottare questa tecnica all’inizio, ma continua a praticare e presto creerai bellissime visualizzazioni che hanno senso!
Se trovi qualcosa di utile in questo articolo, considera di seguirmi su VoAGI. Facile, un articolo a settimana per tenerti aggiornato e restare avanti!
Contattami!
- LinkedIn 👔
- Twitter 🖊
Riferimenti
- Storytelling with Data di Cole Nussbaumer Knaflic. https://www.storytellingwithdata.com/books
- API degli assi di Matplotlib. https://matplotlib.org/stable/api/axes_api.html
- Librerie di grafici Plotly. https://plotly.com/python/reference/





