Async per LangChain e LLMs
Async for LangChain and LLMs
Come fare funzionare le catene LangChain con chiamate asincrone a LLMs, velocizzando il tempo necessario per eseguire una lunga catena sequenziale

In questo articolo, vedremo come utilizzare chiamate asincrone a LLMs per flussi di lavoro lunghi utilizzando LangChain. Faremo un esempio con il codice completo e confrontiamo l’esecuzione sequenziale con le chiamate asincrone.
Ecco una panoramica dei contenuti. Se lo desideri, puoi passare alla sezione di tuo interesse:
- Concetti di base: cos’è LangChain
- Come eseguire una catena sincrona con LangChain
- Come eseguire una singola catena asincrona con LangChain
- Suggerimenti reali per flussi di lavoro lunghi con catene asincrone.
Quindi iniziamo!
Concetti di base: cos’è LangChain
LangChain è un framework per lo sviluppo di applicazioni basate su modelli di linguaggio. Questa è la definizione ufficiale di LangChain. Questo framework è stato creato di recente ed è già utilizzato come standard del settore per la creazione di strumenti basati su LLMs.
- Crea la tua applicazione ChatGPT utilizzando Spring Boot
- EDA con Polars Guida passo-passo alle funzioni di aggregazione e analitiche (Parte 2)
- Affrontare il bias nei sistemi di riconoscimento facciale Un approccio innovativo
È open-source e ben mantenuto, con nuove funzionalità che vengono rilasciate in tempi molto rapidi.
La documentazione ufficiale è disponibile qui e il repository GitHub qui.
Uno svantaggio di questa libreria è che, poiché le funzionalità sono nuove, non possiamo utilizzare Chat GPT per aiutarci efficacemente a creare nuovo codice. Ciò significa che dobbiamo lavorare nel modo “antico” leggendo documentazione, forum e tutorial.
La documentazione di LangChain è davvero buona, tuttavia non ci sono molti esempi di alcune cose specifiche.
Ho riscontrato questo problema con l’asincronizzazione per catene lunghe.
Ecco le principali risorse che ho utilizzato per saperne di più sul framework:
- Corso di IA Deep Learning: Chat con i tuoi dati di LangChain;
- Documentazione ufficiale;
- Canale YouTube.
(ps. Sono tutti gratuiti)
Come eseguire una catena sincrona con LangChain
Permettimi di presentare il problema che ho avuto: ho un dataframe con molte righe e per ciascuna di queste righe devo eseguire più prompt (catene) su un LLM e restituire il risultato al mio dataframe.
Quando hai molte righe, diciamo 10.000, eseguendo 3 prompt per ciascuna e ciascuna risposta (se il server non è sovraccarico) richiedendo circa 3-5 secondi, finisci per dover aspettare giorni per completare il flusso di lavoro.
Di seguito mostrerò i principali passaggi e il codice per creare una catena sincrona e misurarne il tempo su un sottoinsieme di dati.
Per questo esempio, userò il dataset Wine Reviews, licenza. L’obiettivo qui è estrarre alcune informazioni dalle recensioni scritte.
Voglio estrarre un riassunto della recensione, il sentimento principale e le prime 5 caratteristiche di ogni vino.
Per questo, ho creato due catene, una per il riassunto e il sentimento e un’altra che prende il riassunto come input per estrarre le caratteristiche.
Ecco il codice per eseguirlo:
Tempo di esecuzione (10 esempi):
Chain del riassunto (Sequenziale) eseguita in 22,59 secondi.Chain delle caratteristiche (Sequenziale) eseguita in 22,85 secondi.
Se vuoi capire meglio i componenti che sto utilizzando, ti consiglio vivamente di guardare il Corso di IA Deep Learning.
I punti principali di questo codice sono i blocchi di costruzione per una catena, come eseguirla in modo sequenziale e il tempo impiegato per terminare questo ciclo. È importante ricordare che ci sono voluti circa 45 secondi per 10 esempi e il dataset completo contiene 130.000 righe. Quindi, l’implementazione asincrona è la Nuova Speranza per eseguire tutto questo in un tempo ragionevole.
Quindi, con il problema impostato e il punto di riferimento stabilito, vediamo come possiamo ottimizzare questo codice per eseguirlo molto più velocemente.
Come eseguire una singola catena asincrona con LangChain
Per fare ciò, useremo una risorsa chiamata chiamate asincrone. Per spiegare questo, prima spiegherò brevemente cosa sta facendo il codice e dove si sta impiegando troppo tempo.
Nel nostro esempio, scorriamo ogni riga del data frame, estraiamo alcune informazioni dalle righe, le aggiungiamo al nostro prompt e chiamiamo l’API GPT per ottenere una risposta. Dopo la risposta, la analizziamo e la aggiungiamo di nuovo al data frame.

Il principale collo di bottiglia qui è quando chiamiamo l’API GPT perché il nostro computer deve attendere inattivo la risposta da quella API (circa 3 secondi). Il resto dei passaggi è veloce e può ancora essere ottimizzato, ma non è l’obiettivo di questo articolo.
Quindi, anziché aspettare inattivamente la risposta, cosa succederebbe se inviassimo tutte le chiamate all’API contemporaneamente? In questo modo dovremmo aspettare solo una singola risposta e quindi elaborarle. Questo si chiama chiamate asincrone all’API.
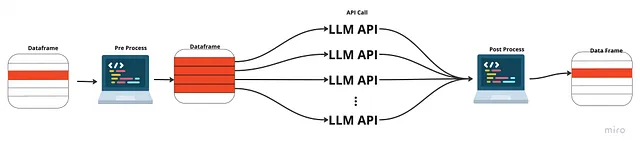
In questo modo effettuiamo il pre-processo e il post-processo in sequenza, ma le chiamate all’API non devono aspettare che la risposta precedente torni prima di inviare la successiva.
Ecco il codice per le catene asincrone:
In questo codice, utilizziamo la sintassi Python di async e await. LangChain ci fornisce anche il codice per eseguire la catena in modo asincrono, con la funzione arun(). Quindi all’inizio elaboriamo prima ogni riga in sequenza (può essere ottimizzata) e creiamo più “task” che attenderanno la risposta dall’API in parallelo e poi elaboriamo la risposta nel formato finale desiderato in sequenza (anche questo può essere ottimizzato).
Tempo di esecuzione (10 esempi):
La catena di riepilogo (Async) è stata eseguita in 3,35 secondi. La catena delle caratteristiche (Async) è stata eseguita in 2,49 secondi.
Confrontato con il sequenziale:
La catena di riepilogo (Sequenziale) è stata eseguita in 22,59 secondi. La catena delle caratteristiche (Sequenziale) è stata eseguita in 22,85 secondi.
Possiamo vedere un miglioramento di quasi 10 volte nel tempo di esecuzione. Quindi, per carichi di lavoro pesanti, consiglio vivamente di utilizzare questo metodo. Inoltre, il mio codice è pieno di cicli for che possono essere ulteriormente ottimizzati per migliorare le prestazioni.
Il codice completo di questo tutorial può essere trovato in questo Repository di Github.
Suggerimenti reali per flussi di lavoro lunghi con catene asincrone.
Quando ho dovuto eseguire questo, ho incontrato alcune limitazioni e alcuni ostacoli, che voglio condividere con voi.
I notebook non sono amichevoli per l’asincronia
Quando si eseguono chiamate asincrone su Jupyter Notebooks, potrebbero verificarsi alcuni problemi. Tuttavia, basta chiedere a Chat GPT e probabilmente può aiutarti con questo. Il codice che ho sviluppato è per eseguire carichi di lavoro pesanti in un file .py, quindi potrebbe essere necessario apportare alcune modifiche per eseguirlo in un notebook.
Troppi output chiave
Il primo problema è che la mia catena aveva più chiavi come output e al momento l’arun() accettava solo catene che avevano una chiave come output. Quindi per risolvere questo problema ho dovuto suddividere la mia catena in due separate.
Non tutte le catene possono essere asincrone
Avevo una logica che utilizzava un database vettoriale per esempi e confronti nel mio prompt e questo richiedeva che gli esempi venissero confrontati in sequenza e aggiunti al database. Ciò rendeva impraticabile l’uso dell’asincronia per questo collegamento nella catena completa.
Mancanza di contenuti
Per questa specifica questione, il miglior contenuto che ho potuto trovare era la documentazione ufficiale per l’asincronia e ho costruito da lì il mio caso d’uso. Quindi se lo esegui e scopri nuove cose, condividile con il mondo!
Conclusion
LangChain è uno strumento molto potente per creare applicazioni basate su LLM. Consiglio vivamente di imparare questo framework e di seguire i corsi citati sopra.
Per quanto riguarda l’argomento specifico dell’esecuzione di catene, per carichi di lavoro elevati abbiamo visto il potenziale miglioramento che hanno le chiamate asincrone, quindi il mio consiglio è di prendersi il tempo per capire cosa fa il codice e avere una classe boilerplate (come quella fornita nel mio codice) e eseguirla in modo asincrono!
Per carichi di lavoro ridotti o applicazioni che richiedono solo una chiamata a un’API, non è necessario farlo in modo asincrono, ma se hai una classe boilerplate, aggiungi semplicemente una funzione di sincronizzazione in modo da poter utilizzare facilmente l’uno o l’altro.
Grazie per la lettura.
Il codice completo può essere trovato qui.
Se ti piace il contenuto e vuoi supportarmi, puoi comprarmi un caffè:
Gabriel Cassimiro è un Data Scientist che condivide contenuti gratuiti alla comunità
Hey 👋 Ho appena creato una pagina qui. Ora puoi comprarmi un caffè!
www.buymeacoffee.com
Ecco alcuni altri articoli che potrebbero interessarti:
Risoluzione di un ambiente Unity con Deep Reinforcement Learning
Progetto end-to-end con codice di un’implementazione di Deep Reinforcement Learning Agent in PyTorch.
towardsdatascience.com
Rilevamento oggetti con modelli Tensorflow e OpenCV
Utilizzo di un modello addestrato per identificare oggetti su immagini statiche e video in diretta
towardsdatascience.com





