Come progettare un modello dbt da zero
Progettare un modello dbt da zero
Un framework semplice per creare modelli dbt che vengono davvero utilizzati.
Quando stavo cercando la Guida Definitiva a dbt, sono rimasto scioccato dalla mancanza di materiale sulla creazione effettiva di modelli da zero. Non intendo i passaggi esatti da seguire nel tool, perché tutto questo è già coperto in innumerevoli blog e tutorial. Intendo come si fa a scegliere il design giusto? Come si fa a far sì che gli stakeholder utilizzino quel modello? Come si può garantire che sia affidabile e comprensibile?
Quando implementiamo nuovi modelli senza seguire questi passaggi, possono esserci conseguenze significative:
- ci troviamo ad affrontare un’ondata di domande e richieste di approfondimento da parte degli stakeholder
- riceviamo suggerimenti per migliorare il codice da altri Data Engineer o Analytics Engineer
- dobbiamo tornare indietro e aggiungere le nuove funzionalità, apportare miglioramenti e rispondere a tutte le domande prima di considerare il nostro lavoro concluso
Se ripetiamo questo processo più volte, la fiducia tra i team di dati e i team aziendali inizia a deteriorarsi, poiché entrambe le parti si stancano sempre di più di questa frenesia di feedback, qualcosa che può essere molto difficile da ricostruire.
Questo sottolinea l’importanza di riflettere attentamente su come progettiamo i modelli, non solo da soli in dbt, ma collettivamente con tutti i nostri stakeholder, per garantire che il modello sia accurato ed efficace, e per non sprecare il nostro tempo costruendo ogni modello 4-5 volte prima che sia utile.
- Scomposizione dei modelli lineari generalizzati
- Analisi dell’EDA sulla qualità dell’acqua in Python e analisi della potabilità
- Analisi dei dati umanitari Tabelle non strutturate di Excel con l’interprete di codice ChatGPT
Questo articolo è il risultato di ricerche ed esperimenti su come progettare e implementare al meglio un modello dbt. Non conterrà comandi da eseguire in dbt, ma illustrerà come pensare al proprio modello e come strutturare il proprio workflow per evitare di sprecare tempo.

Un approccio diverso
Per fortuna, non sono il primo a pensare a questo problema. Molte altre discipline hanno affrontato sfide simili e hanno creato i propri framework e processi che posso sfruttare quando penso a come affrontare la modellazione dei dati. Ad esempio:
I principi Agili scoraggiano gli ingegneri del software dall’approccio di sviluppo a cascata, che è contrario a un ambiente di requisiti in continua evoluzione [1]. Invece, l’Agile favorisce un’iterazione rapida e riconosce il vantaggio competitivo di poter rispondere rapidamente ai cambiamenti dei requisiti.
Analogamente, i principi di progettazione riconoscono la necessità di essere deliberati su come si lavora con più stakeholder in un progetto di progettazione [2]. Il framework dà priorità alle persone e incoraggia il feedback in ogni fase dello sviluppo, in modo che la migliore soluzione possa essere trovata il più rapidamente possibile.

Anche il padre fondatore della modellazione dei dati, Ralph Kimball, riconosce l’importanza di ottenere un input di qualità dagli stakeholder all’inizio di un processo di modellazione nel suo processo di modellazione dei dati in 4 fasi [3]. La prima fase consiste nell’apprendere il più possibile sul processo aziendale prima ancora di pensare a costruire un modello.
Tuttavia, la fonte più influente che ho trovato quando riflettevo su questo problema sono state le euristiche di ingegneria dei sistemi: un insieme di verità sul lavoro su un problema complesso con molti stakeholder [4]:
- Non assumere che l’affermazione originale del problema sia necessariamente la migliore, o anche quella giusta.
- Nelle prime fasi di un progetto, le incognite sono un problema più grande dei problemi noti.
- Modellare prima di costruire, quando possibile.
- La maggior parte degli errori gravi si commettono all’inizio.
Queste fonti hanno contribuito a definire il seguente processo per la progettazione di modelli di dati da zero.
Un processo di progettazione per la modellazione dei dati
E quindi ho voluto creare un processo che rispettasse questi principi, che fosse ripetibile e che garantisse effettivamente che i miei modelli fossero costruiti bene fin dalla prima volta.
Ecco cosa ho ideato:

Esamineremo ogni passo in dettaglio di seguito.
Gli esempi seguenti mostreranno screenshot di count.co, una tela dei dati, dove sono Responsabile del Prodotto. È importante notare, tuttavia, che questo processo è indipendente dallo strumento. Puoi seguire l’esempio negli screenshot qui.
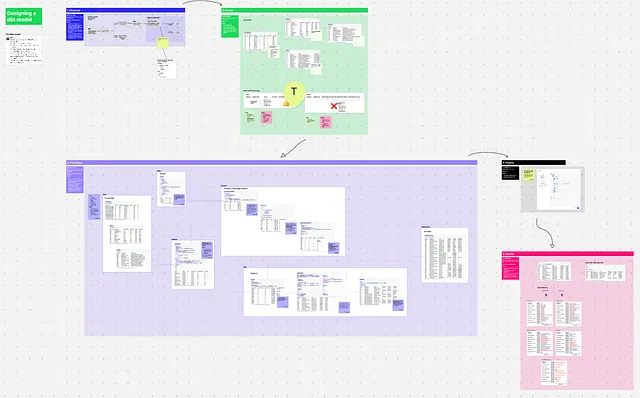
Passo 1: Scoprire
Obiettivo: Comprendere il processo aziendale che si sta modellando.
Partecipanti: Tu, Stakeholder aziendali
Attività:
- Mappare il processo aziendale
- Identificare cosa lo stakeholder desidera fare con la tabella finale (ad esempio, quali metriche deve calcolare, quali filtri deve aggiungere, ecc.)
- Capire come lo stanno facendo oggi (se lo stanno facendo). Cosa non va in quella soluzione?
- Chi altro utilizzerà questo? Dovresti parlare anche con altri stakeholder secondari?
- Altri contesti aziendali rilevanti? ad esempio, qualcuno ha una grande presentazione su questo argomento la prossima settimana
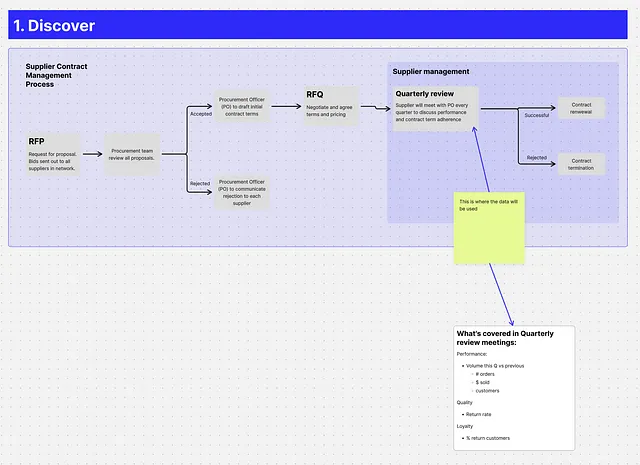
Passo 2: Progettazione (e iterazione!)
Obiettivo: Mappare possibili approcci per la costruzione del tuo modello
Partecipanti: Tu
Attività:
- Mappare la tabella finale
- quale granularità sceglierai?
- quali colonne includerai?
- Se ci sono più opzioni per la progettazione finale della tabella, mappale e ottieni feedback dagli stakeholder prima di procedere

Passo 3: Prototipo (e iterazione!)
Obiettivo: Mappare come arriverai alla tabella finale concordata. Includi codice e spiegazione.
Partecipanti: Tu, membri del team dei dati, stakeholder
Attività:
- Mappare ogni passo del modello, incluso il codice e i risultati ad ogni stadio
- assicurati che un altro membro del team dei dati revisioni il tuo codice
- passa in rassegna la logica con gli stakeholder per assicurarti che sia in linea con le loro aspettative e il contesto
- convalida i risultati del modello prototipato
- itera fino a quando sia gli stakeholder aziendali che il team dei dati comprendano e approvino l’approccio e i risultati
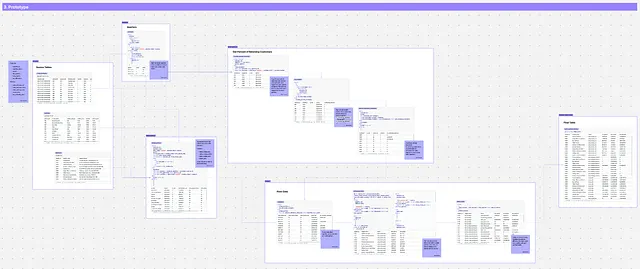
Passo 4: Distribuzione
Obiettivo: Distribuire il modello in dbt
Giocatori: Tu
Attività:
- prendere il codice prototipato finale e distribuirlo nella tua base di codice dbt
- assicurarsi che superi tutti i test

Passaggio 5: Consegna
Obiettivo: Informare gli stakeholder che la tabella è ora disponibile e come interagire con la tabella
Giocatori: Tu, Stakeholder Aziendali
Attività:
- creare documentazione (sia in dbt che altrove)
- inviare il link alla tabella e alla documentazione agli stakeholder
- [opzionale] Creare un’analisi di esempio con la tabella in modo che abbiano un punto di partenza
- [opzionale] Tenere una breve sessione per chiunque voglia un’introduzione alla nuova tabella

Passaggi successivi
Prova questo processo la prossima volta che inizi a costruire un modello dbt da zero. Sarà un grande cambiamento sia per te che per i tuoi stakeholder, ma si è dimostrato che riduce significativamente il tempo necessario per distribuire nuovi modelli e migliora l’adozione complessiva di tali modelli.
Il semplice atto di coinvolgere più persone nel processo di modellazione dei dati e dimostrare trasparenza aiuta a promuovere la fiducia e a fornire modelli di dati preziosi in modo rapido.
E se provi tutto questo, per favore lasciami un commento e fammi sapere come è andata e se hai idee per miglioramenti! Queste cose devono essere continuamente iterate, dopotutto…
Risorse
[1] Agile Manifesto. (2001). Principi di base dell’Agile Manifesto. Recuperato il 1 luglio 2023, da https://agilemanifesto.org/principles.html
[2] Design Council. (2004). Framework per l’innovazione. Recuperato il 1 luglio 2023, da https://www.designcouncil.org.uk/our-resources/framework-for-innovation/
[3] Holistics. Modellazione di dati dimensionali di Kimball. Recuperato il 1 luglio 2023, da https://www.holistics.io/books/setup-analytics/kimball-s-dimensional-data-modeling/
[4] Peter Brook. “Euristici di ingegneria dei sistemi”. in SEBoK Editorial Board. 2023. Guida al Corpo di conoscenza dell’ingegneria dei sistemi (SEBoK), v. 2.8, R.J. Cloutier (Editor in capo). Hoboken, NJ: I Trustee dell’Istituto di Tecnologia Stevens. Accesso [DATA]. www.sebokwiki.org. BKCASE è gestito e mantenuto dal Stevens Institute of Technology Systems Engineering Research Center, dal Consiglio Internazionale di Ingegneria dei Sistemi e dall’Institute of Electrical and Electronics Engineers Systems Council.