Nuova ricerca allinea il testo alla voce senza sforzo | Google
'New research aligns text with voice effortlessly | Google.
Superare la discrepanza di lunghezza della sequenza senza specificarla esplicitamente.
TLDR
Allenare un modello multimodale di testo-voce presenta i suoi problemi. Dato che il tasso di campionamento audio è elevato, la lunghezza della sequenza per l’audio è molto maggiore rispetto al testo corrispondente. Per allenare contemporaneamente sia il testo che l’audio, è necessario superare questa disparità (in modo pigro, senza dover generare dati di allenamento esplicitamente annotati). Questo documento risolve tale problema.
Sommario
L’ultimo anno ha visto un progresso sbalorditivo nella generazione di immagini basata su testo, basata sull’idea di uno spazio di rappresentazione cross-modale in cui i domini del testo e delle immagini sono rappresentati congiuntamente.
Nel riconoscimento automatico del parlato (ASR), questa idea è stata applicata come codificatori congiunti di parlato e testo che possono scalare alle capacità di modelli con molti parametri, allenandoli sia sul parlato che sul testo non accoppiati. Sebbene questi metodi sembrino promettenti, richiedono un trattamento speciale della discrepanza di lunghezza della sequenza intrinseca al parlato e al testo, sia mediante euristiche di sovracampionamento che mediante un modello di allineamento esplicito.
In questo lavoro, offriamo prove che i codificatori congiunti di parlato e testo raggiungono naturalmente rappresentazioni coerenti tra le modalità ignorando la lunghezza della sequenza, e sosteniamo che le perdite di coerenza potrebbero perdonare le differenze di lunghezza e assumere semplicemente il miglior allineamento. Mostriamo che una tale perdita migliora il tasso di errore di parole (WER) in un sistema monolingue e multilingue con molti parametri.
- Accelerare le manipolazioni di stringhe in Pandas
- I più grandi inserzionisti del mondo abbracciano il potere dell’AI un cambio di paradigma nella pubblicità
- Pluggable Diffractive Neural Networks (P-DNN) Un paradigma generale che ricorre alle metasuperfici in cascata che può essere applicato per riconoscere varie attività mediante la commutazione di plugin interni
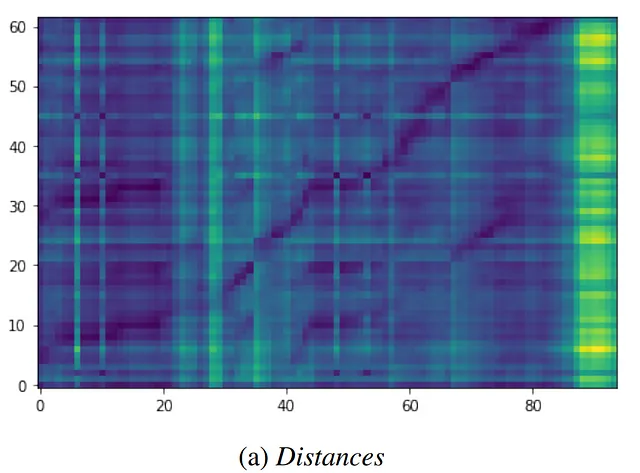
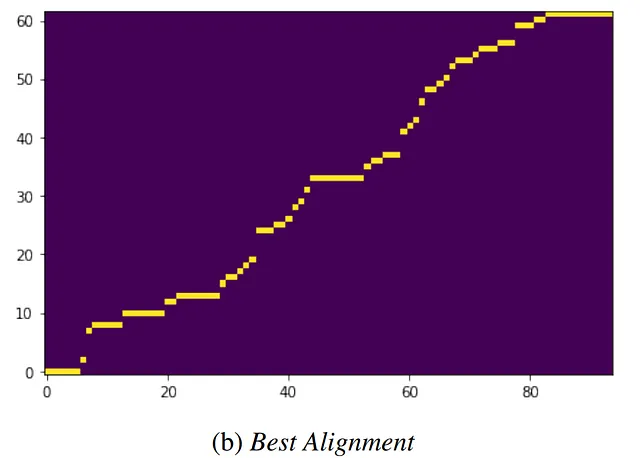
Teoria della soluzione
Allenare un grande codificatore su entrambe le modalità (in questo caso, audio e testo) separatamente. In questo modo, ogni modalità fornisce un esempio non accoppiato, e il meta-modello impara a mappare esempi accoppiati nella dimensione temporale. Questa rappresentazione può fornire prestazioni all’avanguardia nella modalità immagine+testo. Tuttavia, non funziona altrettanto bene nella combinazione di modalità audio+testo.
Il riconoscimento del parlato presenta la sfida particolare di due modalità di sequenza, una di…






