Ricerca autonoma di informazioni visive con grandi modelli linguistici
Autonomous visual information retrieval with large language models
Pubblicato da Ziniu Hu, ricercatore studente, e Alireza Fathi, ricercatore scientifico, Google Research, Perception Team
Si è registrato un grande progresso nell’adattamento dei grandi modelli di linguaggio (LLM) per supportare input multimodali per compiti come la descrizione delle immagini, la risposta alle domande visive (VQA) e il riconoscimento del vocabolario aperto. Nonostante tali risultati, i modelli linguaggio visivo (VLM) all’avanguardia attuali svolgono un lavoro insufficiente sui set di dati di ricerca di informazioni visive, come Infoseek e OK-VQA, in cui è necessaria una conoscenza esterna per rispondere alle domande.
 |
| Esempi di query di ricerca di informazioni visive in cui è necessaria una conoscenza esterna per rispondere alla domanda. Le immagini sono tratte dal set di dati OK-VQA. |
In “AVIS: Ricerca autonoma di informazioni visive con grandi modelli di linguaggio”, presentiamo un nuovo metodo che ottiene risultati all’avanguardia nei compiti di ricerca di informazioni visive. Il nostro metodo integra LLM con tre tipi di strumenti: (i) strumenti di visione artificiale per estrarre informazioni visive dalle immagini, (ii) un motore di ricerca web per recuperare conoscenze e fatti dal mondo aperto e (iii) uno strumento di ricerca di immagini per ottenere informazioni rilevanti dai metadati associati alle immagini visualmente simili. AVIS utilizza un pianificatore alimentato da LLM per scegliere gli strumenti e le query ad ogni passo. Utilizza anche un ragionatore alimentato da LLM per analizzare gli output degli strumenti ed estrarre informazioni chiave. Un componente di memoria di lavoro conserva le informazioni durante tutto il processo.
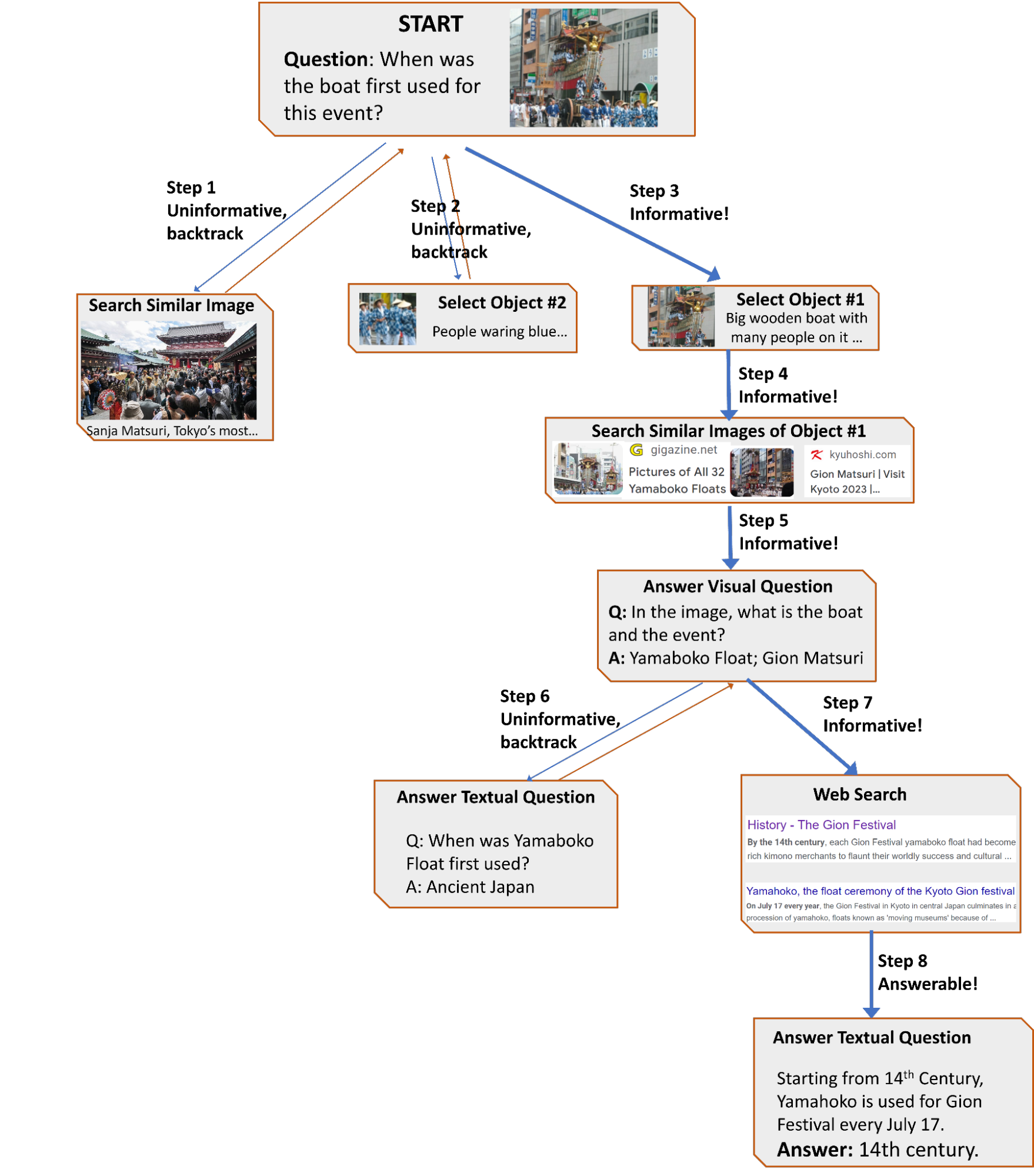 |
| Un esempio di flusso di lavoro generato da AVIS per rispondere a una domanda complessa di ricerca di informazioni visive. L’immagine di input è tratta dal set di dati Infoseek. |
Confronto con lavori precedenti
Ricerche recenti (ad esempio, Chameleon, ViperGPT e MM-ReAct) hanno esplorato l’aggiunta di strumenti a LLM per input multimodali. Questi sistemi seguono un processo a due fasi: pianificazione (scomposizione delle domande in programmi o istruzioni strutturate) ed esecuzione (utilizzo di strumenti per raccogliere informazioni). Nonostante il successo nei compiti di base, questo approccio spesso fallisce in scenari complessi del mondo reale.
- INVE Rivoluzionare il montaggio video con la magia interattiva dell’IA
- Svelando le Reti Bayesiane a Flusso Una Nuova Frontiera nella Modellazione Generativa
- Valori p comprendere la significatività statistica in linguaggio semplice
C’è anche stato un aumento dell’interesse nell’applicazione di LLM come agenti autonomi (ad esempio, WebGPT e ReAct). Questi agenti interagiscono con il loro ambiente, si adattano in base a feedback in tempo reale e raggiungono i loro obiettivi. Tuttavia, questi metodi non limitano gli strumenti che possono essere invocati in ogni fase, portando a uno spazio di ricerca immenso. Di conseguenza, anche i LLM più avanzati oggi possono cadere in loop infiniti o propagare errori. AVIS affronta questo problema tramite l’utilizzo guidato di LLM, influenzato dalle decisioni umane da uno studio dell’utente.
Guidare la decisione di LLM con uno studio dell’utente
Molte delle domande visive nei set di dati come Infoseek e OK-VQA rappresentano una sfida anche per gli esseri umani, richiedendo spesso l’assistenza di vari strumenti e API. Di seguito è riportata un’esempio di domanda tratta dal set di dati OK-VQA. Abbiamo condotto uno studio sull’utente per comprendere la presa di decisioni umane nell’utilizzo di strumenti esterni.
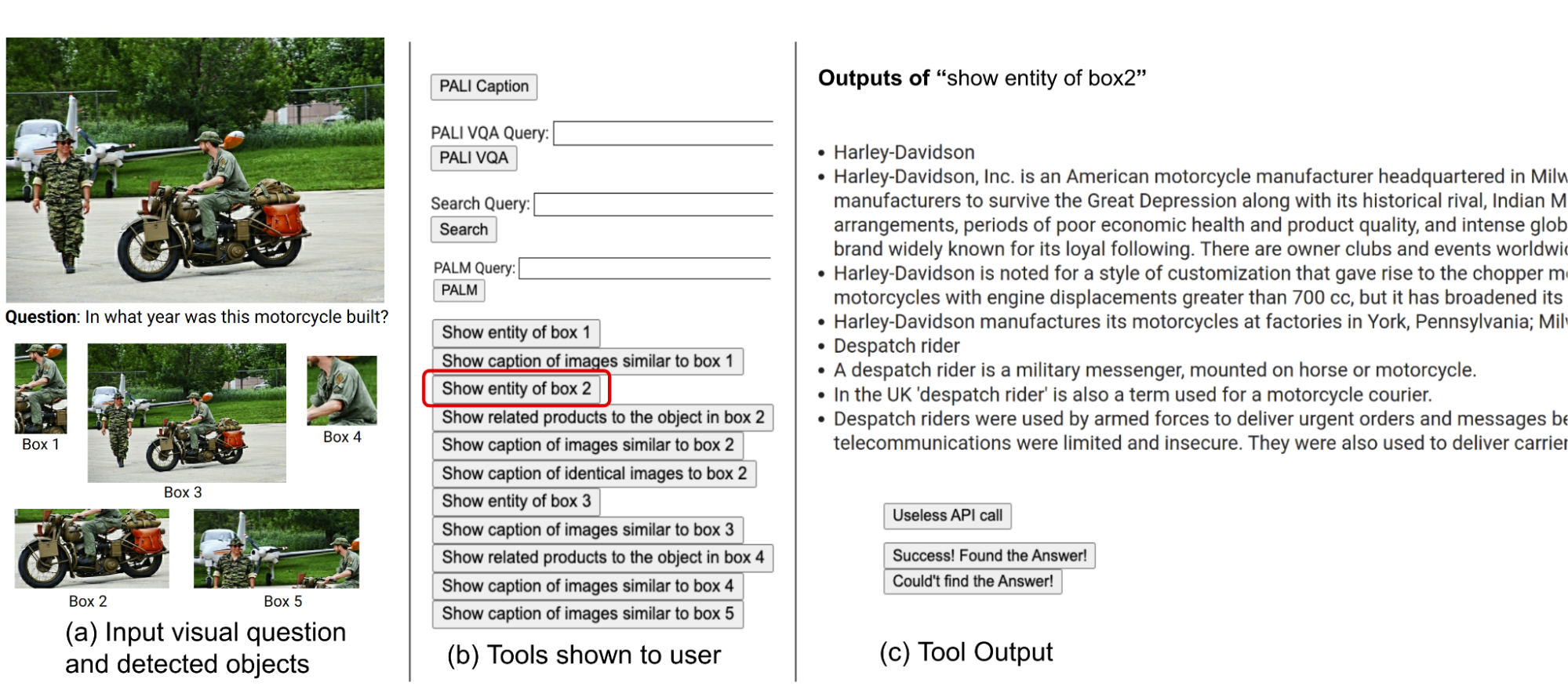 |
| Abbiamo condotto uno studio sugli utenti per comprendere la presa di decisioni umane nell’utilizzo di strumenti esterni. L’immagine è tratta dal dataset OK-VQA. |
Gli utenti sono stati forniti di un identico set di strumenti come il nostro metodo, inclusi PALI, PaLM e la ricerca web. Hanno ricevuto immagini di input, domande, ritagli di oggetti rilevati e pulsanti collegati ai risultati della ricerca di immagini. Questi pulsanti offrivano informazioni diverse sui ritagli di oggetti rilevati, come entità del grafo delle conoscenze, didascalie di immagini simili, titoli di prodotti correlati e didascalie di immagini identiche.
Registriamo le azioni e le uscite degli utenti e le utilizziamo come guida per il nostro sistema in due modi chiave. Primo, costruiamo un grafico di transizione (mostrato di seguito) analizzando la sequenza di decisioni prese dagli utenti. Questo grafico definisce stati distinti e limita l’insieme di azioni disponibili in ogni stato. Ad esempio, nello stato iniziale, il sistema può compiere solo una di queste tre azioni: didascalia PALI, PALI VQA o rilevamento di oggetti. Secondo, utilizziamo gli esempi di decisioni umane per guidare il nostro pianificatore e ragionatore con istanze contestuali rilevanti al fine di migliorare le prestazioni e l’efficacia del nostro sistema.
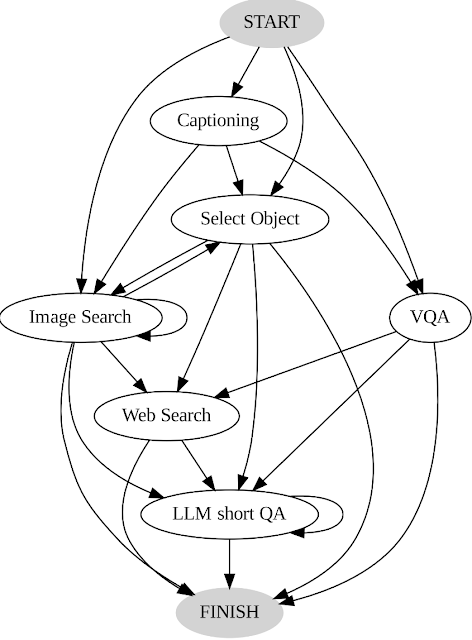 |
| Grafico di transizione AVIS. |
Quadro generale
Il nostro approccio utilizza una strategia di presa di decisioni dinamica progettata per rispondere alle query di ricerca di informazioni visive. Il nostro sistema ha tre componenti principali. Primo, abbiamo un pianificatore per determinare l’azione successiva, inclusa la chiamata API appropriata e la query che deve elaborare. Secondo, abbiamo una memoria di lavoro che conserva informazioni sui risultati ottenuti dalle esecuzioni API. Infine, abbiamo un ragionatore, il cui ruolo è elaborare le uscite delle chiamate API. Determina se le informazioni ottenute sono sufficienti per produrre la risposta finale o se è necessario recuperare ulteriori dati.
Il pianificatore intraprende una serie di passaggi ogni volta che è necessaria una decisione su quale strumento utilizzare e quale query inviare ad esso. Sulla base dello stato attuale, il pianificatore fornisce una serie di azioni potenziali successive. Lo spazio di azione potenziale può essere così ampio da rendere lo spazio di ricerca inaffidabile. Per affrontare questo problema, il pianificatore fa riferimento al grafico di transizione per eliminare le azioni irrilevanti. Il pianificatore esclude anche le azioni già eseguite in precedenza e memorizzate nella memoria di lavoro.
Successivamente, il pianificatore raccoglie un insieme di esempi rilevanti nel contesto che sono assemblati dalle decisioni precedentemente prese dagli esseri umani durante lo studio sugli utenti. Con questi esempi e la memoria di lavoro che conserva i dati raccolti dalle interazioni passate degli strumenti, il pianificatore formula un prompt. Il prompt viene quindi inviato all’LLM, che restituisce una risposta strutturata, determinando lo strumento successivo da attivare e la query da inviare ad esso. Questo design consente al pianificatore di essere invocato più volte durante il processo, facilitando così la presa di decisioni dinamiche che conducono gradualmente a rispondere alla query di input.
Utilizziamo un ragionatore per analizzare l’output dell’esecuzione degli strumenti, estrarre le informazioni utili e decidere in quale categoria rientra l’output dello strumento: informativo, non informativo o risposta finale. Il nostro metodo utilizza l’LLM con un prompt appropriato e esempi nel contesto per effettuare il ragionamento. Se il ragionatore conclude di essere pronto a fornire una risposta, restituirà la risposta finale, concludendo così il compito. Se determina che l’output dello strumento non è informativo, tornerà al pianificatore per selezionare un’altra azione in base allo stato attuale. Se trova l’output dello strumento utile, modificherà lo stato e trasferirà il controllo nuovamente al pianificatore per prendere una nuova decisione nel nuovo stato.
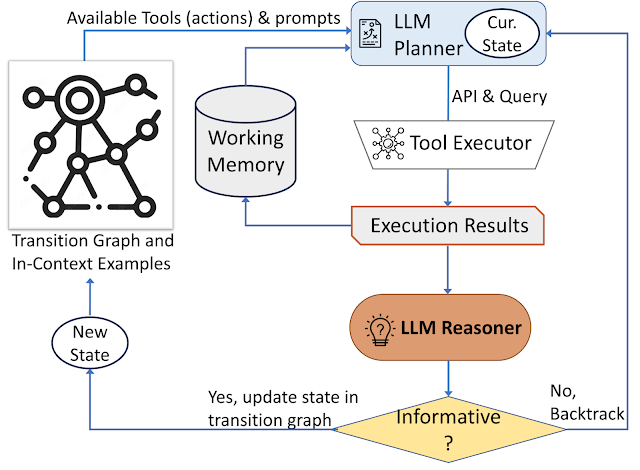 |
| AVIS utilizza una strategia decisionale dinamica per rispondere alle richieste di informazioni visive. |
Risultati
Valutiamo AVIS sui dataset Infoseek e OK-VQA. Come mostrato di seguito, anche modelli robusti di linguaggio visivo, come OFA e PaLI, non riescono a ottenere un’alta precisione quando vengono addestrati su Infoseek. Il nostro approccio (AVIS), senza addestramento fine-tuning, raggiunge una precisione del 50,7% sulla suddivisione delle entità non viste di questo dataset.
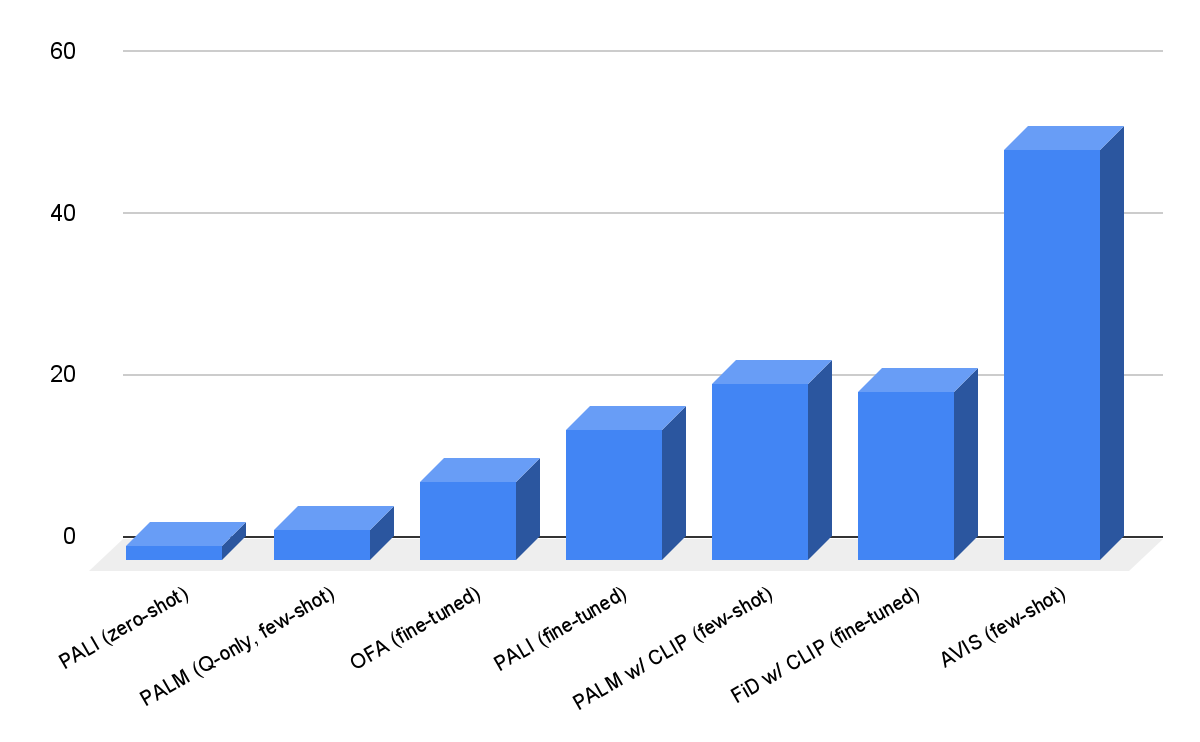 |
| Risultati di AVIS nella risposta alle domande visive sul dataset Infoseek. AVIS ottiene una precisione maggiore rispetto alle basi precedenti basate su PaLI, PaLM e OFA. |
I nostri risultati sul dataset OK-VQA sono mostrati di seguito. AVIS con pochi esempi in contesto raggiunge una precisione del 60,2%, superiore alla maggior parte dei lavori precedenti. AVIS raggiunge una precisione inferiore ma paragonabile rispetto al modello PALI addestrato su OK-VQA. Questa differenza, rispetto a Infoseek in cui AVIS supera PALI addestrato, è dovuta al fatto che la maggior parte degli esempi di domande-risposte in OK-VQA si basano sulla conoscenza del buon senso piuttosto che sulla conoscenza dettagliata. Pertanto, PaLI è in grado di codificare tale conoscenza generica nei parametri del modello e non richiede conoscenze esterne.
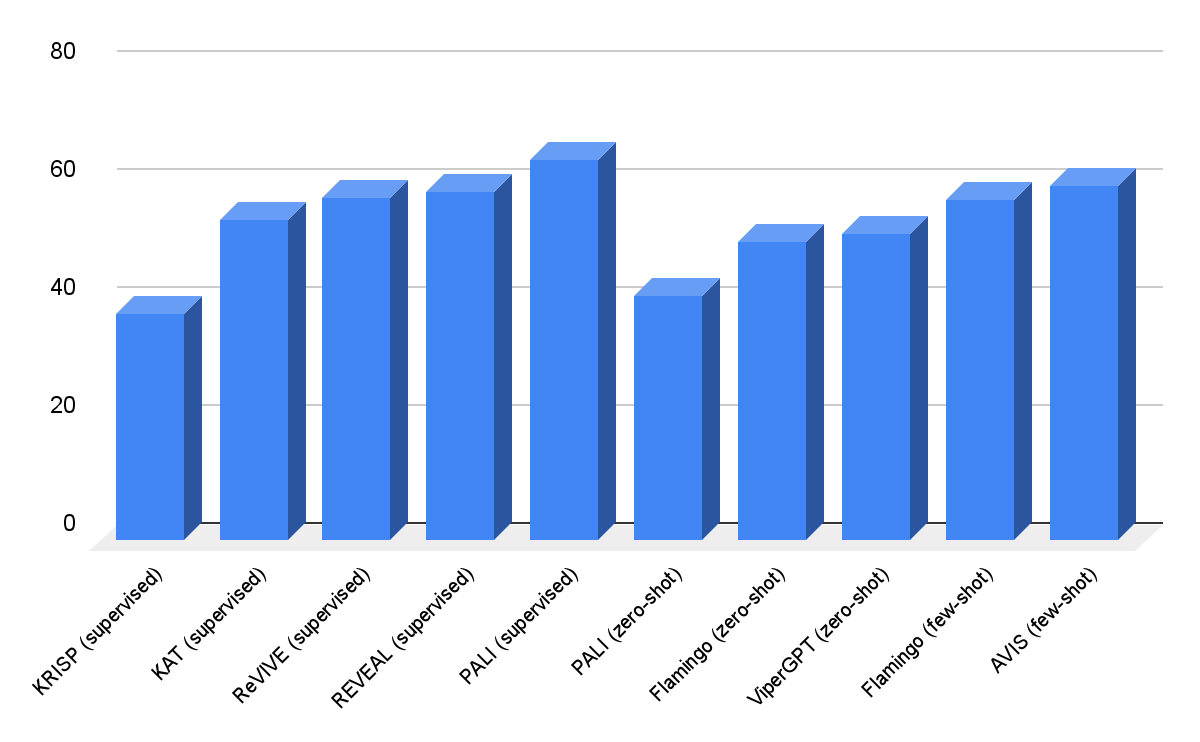 |
| Risultati della risposta alle domande visive su A-OKVQA. AVIS ottiene una precisione maggiore rispetto ai lavori precedenti che utilizzano l’apprendimento a pochi o zero esempi, tra cui Flamingo, PaLI e ViperGPT. AVIS ottiene anche una precisione maggiore rispetto alla maggior parte dei lavori precedenti che sono stati addestrati sul dataset OK-VQA, tra cui REVEAL, ReVIVE, KAT e KRISP, e ottiene risultati vicini al modello PaLI addestrato. |
Conclusione
Presentiamo un nuovo approccio che dota LLM di capacità di utilizzare una varietà di strumenti per rispondere a domande visive legate alla conoscenza. La nostra metodologia, basata su dati di decision-making umano raccolti da uno studio utente, impiega un framework strutturato che utilizza un pianificatore potenziato da LLM per decidere dinamicamente la selezione degli strumenti e la formazione delle query. Un ragionatore potenziato da LLM ha il compito di elaborare ed estrarre informazioni chiave dall’output dello strumento selezionato. Il nostro metodo utilizza in modo iterativo il pianificatore e il ragionatore per sfruttare diversi strumenti fino a quando tutte le informazioni necessarie per rispondere alla domanda visiva sono accumulate.
Ringraziamenti
Questa ricerca è stata condotta da Ziniu Hu, Ahmet Iscen, Chen Sun, Kai-Wei Chang, Yizhou Sun, David A. Ross, Cordelia Schmid e Alireza Fathi.