Mastery di Visual BERT | Libera il potere del tuo primo incontro
Mastery di Visual BERT | Libera il potere del primo incontro
Introduzione
Google afferma che BERT è un passo avanti importante, uno dei miglioramenti più significativi nella storia della Ricerca. Aiuta Google a capire in modo più accurato ciò che le persone stanno cercando. La padronanza del Visual BERT è speciale perché può capire le parole in una frase guardando le parole prima e dopo di esse. Questo aiuta a comprendere meglio il significato delle frasi. È come quando comprendiamo una frase considerando tutte le sue parole.

BERT aiuta i computer a capire il significato del testo in diverse situazioni. Ad esempio, può aiutare a classificare il testo, a comprendere i sentimenti delle persone in un messaggio, a rispondere a domande riconosciute e a riconoscere i nomi di cose o persone. L’utilizzo di BERT in Google Search mostra quanto i modelli linguistici abbiano fatto progressi e rendano le nostre interazioni con i computer più naturali e utili.
Obiettivi di apprendimento
- Imparare cosa significa BERT (Bidirectional Encoder Representations from Transformers).
- Conoscenza di come BERT viene addestrato su una grande quantità di dati testuali.
- Comprendere il concetto di pre-addestramento e come aiuta BERT a sviluppare la comprensione del linguaggio.
- Riconoscere che BERT considera sia i contesti a sinistra che a destra delle parole in una frase.
- Utilizzare BERT nei motori di ricerca per comprendere meglio le query degli utenti.
- Esplorare il modello di linguaggio mascherato e le attività di previsione della frase successiva utilizzate nell’addestramento di BERT.
Questo articolo è stato pubblicato come parte del Data Science Blogathon.
- Metodi di approssimazione di Monte Carlo Quale dovresti scegliere e quando?
- Utilizzando l’IA generativa e i modelli di apprendimento automatico per l’ottimizzazione delle linee oggetto delle email e dei dispositivi mobili
- Come definire un problema di intelligenza artificiale
Cos’è Bert?
BERT significa Bidirectional Encoder Representations from Transformers. È un modello informatico speciale che aiuta i computer a comprendere e processare il linguaggio umano. È uno strumento intelligente che può leggere e comprendere il testo come noi.
Ciò che rende BERT speciale è che può capire il significato delle parole in una frase guardando le parole prima e dopo di esse. È come leggere una frase e comprendere cosa significa considerando tutte le parole insieme.

BERT viene addestrato utilizzando testi tratti da libri, articoli e siti web. Ciò aiuta a imparare modelli e connessioni tra le parole. Quindi, quando diamo a BERT una frase, può capire il significato e il contesto di ogni parola in base al suo addestramento.
Questa potente capacità di BERT di comprendere il linguaggio viene utilizzata in molti modi diversi. Può anche aiutare con compiti come la classificazione del testo, la comprensione del sentimento o dell’emozione in un messaggio e la risposta a domande.
Dataset SST2
Link del dataset: https://github.com/clairett/pytorch-sentiment-classification/tree/master/data/SST2
In questo articolo, useremo il dataset sopra menzionato, che consiste in frasi estratte da recensioni di film. Il valore 1 rappresenta un’etichetta positiva e il valore 0 rappresenta un’etichetta negativa per ogni frase.

Addestrando un modello su questo dataset, possiamo insegnare al modello a classificare nuove frasi come positive o negative in base ai modelli appresi dai dati etichettati.
Modelli: Classificazione del Sentimento delle Frasi
Aimiamo a creare un modello di analisi del sentimento per classificare le frasi come positive o negative.

Combattendo la potenza delle capacità di elaborazione delle frasi di DistilBERT con le capacità di classificazione della regressione logistica, possiamo costruire un modello di analisi del sentimento efficiente e preciso.

Genera i vettori di frase con DistilBERT: Utilizza il modello pre-addestrato di DistilBERT per generare i vettori di frase per 2.000 frasi.

Queste incapsulazioni delle frasi catturano informazioni importanti sul significato e il contesto delle frasi.
Eseguire la suddivisione dei dati di addestramento/test: Suddividere il set di dati in set di addestramento e di test.

Utilizzare il set di addestramento per addestrare il modello di regressione logistica, mentre il set di test sarà utilizzato per la valutazione.
Addestrare il modello di regressione logistica: Utilizzare il set di addestramento per addestrare il modello di regressione logistica utilizzando scikit-learn.

Il modello di regressione logistica impara a classificare le frasi come positive o negative in base alle incapsulazioni delle frasi.
Seguendo questo piano, possiamo sfruttare il potere di DistilBERT per generare incapsulazioni informative delle frasi e quindi addestrare un modello di regressione logistica per eseguire la classificazione dei sentimenti. La fase di valutazione ci consente di valutare le prestazioni del modello nella previsione del sentimento di nuove frasi.
Come viene calcolata una singola previsione?
Ecco una spiegazione di come un modello addestrato calcola la sua previsione utilizzando la frase di esempio “un’approfondita riflessione visivamente suggestiva sull’amore”:
Tokenizzazione: Ogni parola della frase viene divisa in componenti più piccoli chiamati token. Il tokenizer inserisce inoltre specifici token come ‘CLS’ all’inizio e ‘SEP’ alla fine.

Conversione token a ID: Il tokenizer sostituisce quindi ogni token con il suo ID corrispondente dalla tabella di incapsulamento. La tabella di incapsulamento è un componente fornito dal modello addestrato e mappa i token alle loro rappresentazioni numeriche.
La forma dell’input: Dopo la tokenizzazione e la conversione, DistilBERT trasforma la frase di input nella forma corretta per l’elaborazione. Rappresenta la frase come una sequenza di ID di token con l’aggiunta di token unici.

Si noti che è possibile eseguire tutti questi passaggi, inclusa la tokenizzazione e la conversione degli ID, utilizzando una singola riga di codice con il tokenizer fornito dalla libreria.

Seguendo questi passaggi di preprocessing, la frase di input è preparata in un formato che può essere alimentato al modello DistilBERT per ulteriori elaborazioni e previsioni.
Flusso attraverso DistilBERT
Effettivamente, il passaggio del vettore di input attraverso DistilBERT segue un processo simile a quello di BERT. L’output consisterà in un vettore per ogni token di input, in cui ogni vettore contiene 768 numeri (float).

Nel caso della classificazione delle frasi, ci concentriamo solo sul primo vettore, che corrisponde al token [CLS]. Il token [CLS] è progettato per catturare il contesto generale dell’intera sequenza, quindi utilizzare solo il primo vettore (il token [CLS]) per la classificazione delle frasi in modelli come BERT funziona. La posizione di questo token, la sua funzione nel pre-addestramento e la tecnica di pooling contribuiscono tutte alla sua capacità di codificare informazioni significative per compiti di classificazione. Inoltre, utilizzando solo il token [CLS] si riduce la complessità computazionale e i requisiti di memoria consentendo al modello di effettuare previsioni accurate per una vasta gamma di compiti di classificazione. Questo vettore viene passato come input al modello di regressione logistica.
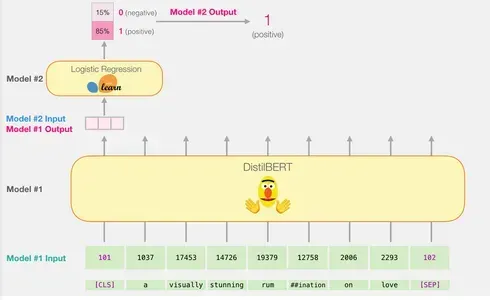
Il ruolo del modello di regressione logistica è quello di classificare questo vettore in base a ciò che ha appreso durante la sua fase di addestramento. Possiamo immaginare il calcolo della previsione come segue:
- Il modello di regressione logistica prende il vettore di input (associato al token [CLS]) come input.
- Applica un insieme di pesi appresi a ciascuno dei 768 numeri nel vettore.
- I numeri pesati vengono sommati e viene aggiunto un termine di bias aggiuntivo.
Infine, il risultato della somma viene passato attraverso una funzione sigmoide per produrre il punteggio di previsione.

La fase di addestramento del modello di regressione logistica e il codice completo per l’intero processo saranno discussi nella prossima sezione.
Implementazione da zero
In questa sezione verrà evidenziato il codice per addestrare questo modello di classificazione delle frasi.
Carica la libreria
Iniziamo importando gli strumenti del mestiere. Possiamo utilizzare df.head() per visualizzare le prime cinque righe del dataframe e vedere come sono i dati.

Importazione del modello DistilBERT pre-addestrato e del tokenizer
<p-Tokenizzeremo l'insieme di dati, ma con una piccola differenza rispetto all'esempio precedente. Invece di tokenizzare e elaborare una frase alla volta, elaboreremo tutte le frasi insieme come batch.
model_class, tokenizer_class, pretrained_weights = (ppb.DistilBertModel, ppb.DistilBertTokenizer,
'distilbert-base-uncased')
##Vuoi BERT invece di distilBERT?
##Togli il commento alla riga seguente:
#model_class, tokenizer_class, pretrained_weights = (ppb.BertModel, ppb.BertTokenizer,
'bert-base-uncased')
# Carica il modello/tokenizer pre-addestrato
tokenizer = tokenizer_class.from_pretrained(pretrained_weights)
model = model_class.from_pretrained(pretrained_weights)Ad esempio, supponiamo di avere un insieme di dati di recensioni di film e vogliamo tokenizzare e elaborare contemporaneamente 2.000 recensioni. Utilizzeremo un tokenizer chiamato DistilBertTokenizer, uno strumento appositamente progettato per tokenizzare il testo utilizzando il modello DistilBERT.
Il tokenizer prende l’intero batch di frasi e esegue la tokenizzazione, che consiste nella suddivisione delle frasi in unità più piccole chiamate token. Aggiunge anche token speciali, come [CLS] all’inizio e [SEP] alla fine di ogni frase.
Tokenizzazione
Come risultato, ogni frase diventa una lista di ID. L’insieme di dati è costituito da una lista di liste (o una serie/dataframe di pandas). Le frasi più brevi devono essere riempite con l’ID del token 0 per rendere tutti i vettori della stessa lunghezza. Ora abbiamo una matrice/tensore che può essere fornita a BERT dopo il padding:
tokenized = df[0].apply((lambda x: tokenizer.
encode(x, add_special_tokens=True)))

Elaborazione con DistilBERT
La matrice dei token con padding viene ora convertita in un tensore di input, che viene inviato a DistilBERT.
input_ids = torch.tensor(np.array(padded))
with torch.no_grad():
last_hidden_states = model(input_ids)Gli output di DistilBERT vengono memorizzati in last_hidden_states dopo aver completato questo passaggio. Poiché abbiamo considerato solo 2000 istanze nel nostro scenario, questo sarà 2000 (il numero di token nella sequenza più lunga tra i 2000 esempi) e 768 (il numero di unità nascoste nel modello DistilBERT).
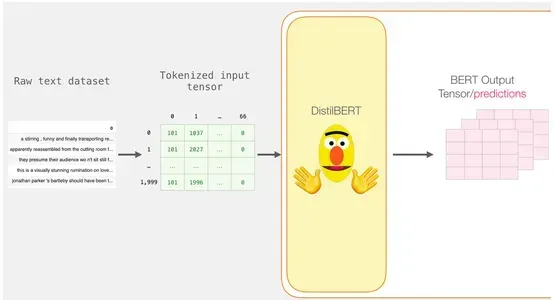
Scomposizione del tensore di output di BERT
Esaminiamo le dimensioni del tensore di output 3D e lo estraiamo. Supponendo di avere la variabile last_hidden_states, che contiene il tensore di output di DistilBERT.
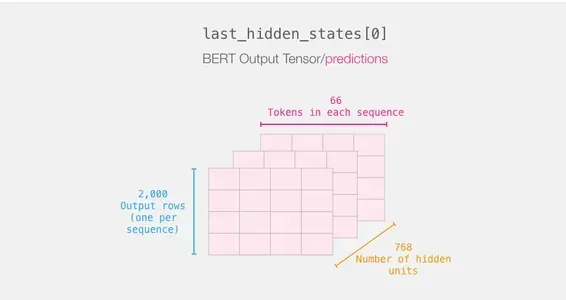
Ricapitolando il percorso di una frase
Ogni riga ha un testo del nostro dataset allegato ad essa. Per rivedere il flusso di elaborazione della prima frase, immaginalo come segue:

Tagliare la parte importante
Scegliamo solo quel segmento del cubo per la categorizzazione delle frasi poiché siamo interessati solo al risultato di BERT per il token [CLS].

Per ottenere il tensore 2D di nostro interesse da quel tensore 3D, lo tagliamo come segue:
# Taglia l'output per la prima posizione per tutte le sequenze, prendi tutti gli output delle unità nascoste
features = last_hidden_states[0][:,0,:].numpy()Infine, la caratteristica è una matrice numpy 2D che include tutte le sentence embeddings delle frasi del nostro dataset.

Applica la regressione logistica
Ora che abbiamo l’output di BERT, abbiamo il dataset necessario per addestrare il nostro modello di regressione logistica. Le 768 colonne nel nostro primo dataset comprendono le caratteristiche e le etichette.

Possiamo definire e addestrare il nostro modello di regressione logistica sul dataset dopo aver effettuato la suddivisione convenzionale tra train e test dell’apprendimento automatico.
labels = df[1]
train_features, test_features, train_labels, test_labels = train_test_split(features, labels)Utilizzando questo, il dataset viene diviso in set di addestramento e di test:

Il modello di regressione logistica viene quindi addestrato utilizzando il set di addestramento.
lr_clf = LogisticRegression()
lr_clf.fit(train_features, train_labels)Dopo che il modello è stato addestrato, possiamo confrontare i suoi risultati con il set di test:
lr_clf.score(test_features, test_labels)Che dà al modello una precisione di circa l’81%.
Conclusione
In conclusione, BERT è un potente modello di linguaggio che aiuta i computer a comprendere meglio il linguaggio umano. Considerando il contesto delle parole e addestrandosi su vaste quantità di dati testuali, BERT può catturare il significato e migliorare la comprensione del linguaggio.
Punti chiave
- BERT è un modello di linguaggio che aiuta i computer a comprendere meglio il linguaggio umano.
- Considera il contesto delle parole in una frase, rendendolo più intelligente nella comprensione del significato.
- BERT è addestrato su grandi quantità di dati testuali per apprendere i modelli linguistici.
- Può essere perfezionato per compiti specifici come la classificazione del testo o la risposta alle domande.
- BERT migliora i risultati della ricerca e la comprensione del linguaggio nelle applicazioni.
- Gestisce le parole sconosciute suddividendole in parti più piccole.
- TensorFlow e PyTorch sono utilizzati con BERT.
BERT ha migliorato applicazioni come i motori di ricerca e la classificazione del testo, rendendoli più intelligenti e utili. Nel complesso, BERT rappresenta un passo significativo nel rendere i computer in grado di comprendere in modo più efficace il linguaggio umano.
Domande frequenti
I media mostrati in questo articolo non sono di proprietà di Analytics Vidhya e sono utilizzati a discrezione dell’autore.





