Predizione della Malattia Renale Cronica Una Nuova Prospettiva
Predizione Malattia Renale Cronica Nuova Prospettiva
Utilizzare SHAP per costruire un modello interpretabile che sia coerente con la letteratura medica
Introduzione
I reni lavorano duramente per rimuovere scarti, tossine e fluidi in eccesso dal sangue e il loro corretto funzionamento è cruciale per una buona salute. La Malattia Renale Cronica (CKD) è una condizione in cui i reni non riescono a filtrare il sangue come dovrebbero, portando all’accumulo di fluidi e rifiuti nel sangue che nel lungo termine può portare all’insufficienza renale. [1] La CKD colpisce oltre il 10% della popolazione mondiale e si prevede che sarà la quinta causa più elevata di anni di vita persi a livello globale entro il 2040. [2]
In questo articolo, il mio obiettivo non era quello di costruire il modello più accurato in grado di prevedere l’insorgenza della CKD nei pazienti. Invece, era quello di verificare se il miglior modello sviluppato utilizzando algoritmi di machine learning standard è anche il modello più significativo secondo la letteratura medica. Ho utilizzato i principi di SHAP (SHapley Additive exPlanations), un approccio teorico dei giochi per spiegare l’output del modello di ML.
Cosa dice la Letteratura Medica?
La letteratura medica ha associato lo sviluppo e la progressione della CKD a alcuni sintomi chiave.
- Diabete mellito e Ipertensione: Il diabete e l’ipertensione sono due dei fattori di rischio più importanti associati alla CKD. In uno studio condotto negli USA dal 2011 al 2014, la prevalenza di CKD (stadi 3-4) è stata del 24,5% nei diabetici, del 14,3% nei prediabetici e del 4,9% nei non diabetici. Nello stesso studio, la prevalenza di CKD è stata osservata essere del 35,8% nei soggetti ipertesi, del 14,4% nei soggetti preipertesi e del 10,2% nei soggetti non ipertesi. [2]
- Diminuzione dei livelli di emoglobina e globuli rossi: I reni producono un ormone chiamato eritropoietina (EPO), che aiuta nella produzione dei globuli rossi. Nella CKD, i reni non sono in grado di produrre una quantità sufficiente di EPO, portando allo sviluppo di anemia, cioè una diminuzione del livello di globuli rossi e quindi di emoglobina nel sangue. [3]
- Aumento della creatinina sierica (nel sangue): La creatinina è un prodotto di scarto della normale rottura dei muscoli e delle proteine e l’eccesso viene eliminato dal sangue attraverso i reni. Nella CKD, il rene non è in grado di eliminare efficacemente la creatinina in eccesso, portando a livelli elevati nel sangue. [4]
- Diminuzione della gravità specifica delle urine: La gravità specifica delle urine è un indicatore di quanto bene il rene può concentrare l’urina. I pazienti affetti da CKD hanno una diminuzione della gravità specifica delle urine poiché i reni perdono la capacità di concentrare efficacemente l’urina. [5]
- Ematuria e Albuminuria: L’Ematuria e l’Albuminuria si riferiscono alla presenza di globuli rossi e albumina nelle urine rispettivamente. Normalmente, i filtri nei reni impediscono al sangue e all’albumina di entrare nelle urine. Tuttavia, un’alterazione di questi filtri può causare l’ingresso di sangue (o globuli rossi) e albumina nelle urine. [6][7]
Il Dataset
Il dataset utilizzato per questo articolo è il dataset “Malattia Renale Cronica” disponibile su Kaggle, inizialmente fornito dalla UCI nel loro repository di ML. È composto da dati di 400 pazienti, tra cui 24 caratteristiche e 1 variabile binaria target (CKD assente = 0, CKD presente = 1). Una descrizione dettagliata delle caratteristiche può essere trovata qui.
- Costruire Sistemi di Apprendimento Automatico Migliori — Capitolo 3 Modellazione. Che inizi il divertimento
- Più che semplici rettili Esplorare il toolkit delle iguane per l’Intelligenza Artificiale Spiegabile oltre i modelli a scatola nera
- Immagini di Intelligenza Artificiale Un’Analisi Accademica delle Complessità e dei Meccanismi delle GAN
Preelaborazione dei dati
Il dataset CKD presentava molti valori mancanti che dovevano essere imputati prima di ulteriori analisi. Questo grafico mostra una rappresentazione visiva dei dati mancanti, con le linee gialle che indicano i valori mancanti in quella colonna.
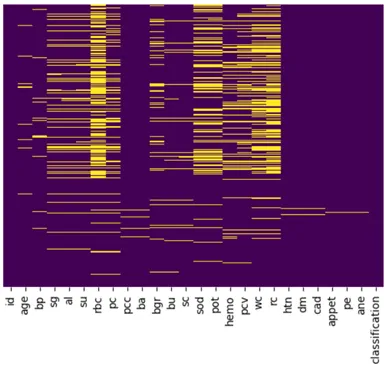
I valori mancanti sono stati sostituiti nei seguenti modi:
- Per le caratteristiche numeriche, i valori mancanti sono stati riempiti utilizzando la mediana. La media non è stata utilizzata perché la media è sensibile agli outlier, mentre la mediana no. A causa della presenza di outlier in queste colonne, la mediana è una misura migliore del valore centrale.
- Le caratteristiche categoriche ‘rbc’ e ‘pc’ avevano rispettivamente il 38% e il 16,25% dei loro dati mancanti. Poiché si tratta di una grande quantità di dati mancanti, i valori mancanti sono stati riempiti come ‘sconosciuto’. Utilizzare la moda qui non sarebbe stata la decisione migliore in quanto sarebbe stato un po’ rischioso categorizzare un così grande gruppo di osservazioni nella stessa categoria.
- Tutte le altre caratteristiche categoriche avevano meno o uguale al 1% dei loro dati mancanti. Pertanto, i valori mancanti sono stati riempiti utilizzando le rispettive mode.
Costruzione del modello e verifica dell’interpretabilità utilizzando SHAP
Dopo aver riempito i valori mancanti, i dati sono stati divisi in train e test (split del 70-30) ed è stato eseguito un semplice modello di classificazione Random Forest. L’accuratezza del test è stata del 100%, ovvero il modello è stato in grado di classificare correttamente i pazienti che non aveva mai visto prima il 100% delle volte. La matrice di confusione è stata mostrata di seguito.
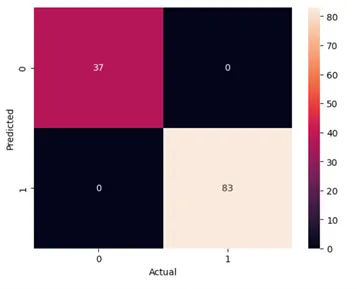
Ora, ovviamente, abbiamo un ottimo modello di classificazione. Ma cosa succederebbe se fossimo interessati all’interpretabilità, ovvero come ogni caratteristica contribuisce positivamente o negativamente alla previsione? Quali sono le caratteristiche più importanti che guidano le previsioni? I risultati sono in linea con le scoperte cliniche? Queste sono domande a cui SHAP può aiutarci a rispondere.
SHAP è un approccio matematico basato sulla teoria dei giochi che può essere utilizzato per spiegare la previsione di qualsiasi modello di apprendimento automatico calcolando il contributo di ogni caratteristica alla previsione. Può aiutarci a determinare le caratteristiche più importanti che contribuiscono alla previsione e la direzione in cui influenzano la variabile target. [8] È stato adattato un SHAP explainer ai dati di test ed è stata generata una rappresentazione grafica dell’importanza delle caratteristiche globali come mostrato di seguito.
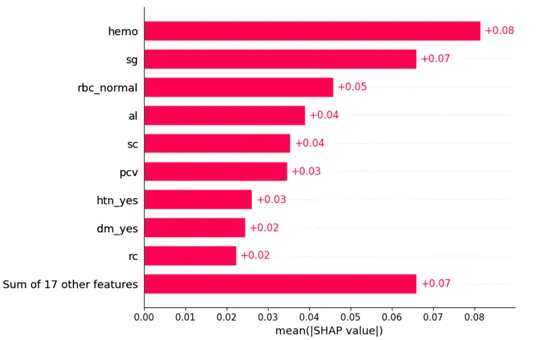
Le tre caratteristiche principali che guidano la previsione sono i livelli di emoglobina (‘hemo’), la densità specifica dell’urina (‘sg’) e se il paziente aveva globuli rossi nelle urine (‘rbc_normal’). Poiché l’importanza delle caratteristiche viene calcolata prendendo la media del valore SHAP assoluto per quella caratteristica su tutti i campioni dati, il grafico fornisce solo informazioni sull’ordine di importanza e non sulla direzione di influenza. Produrremo quindi un grafico più informativo che comprenda entrambi questi obiettivi.
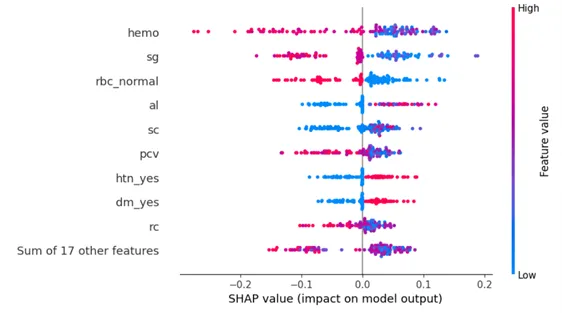
Questo grafico Beeswarm è un ottimo modo per mostrare come le caratteristiche principali in un dataset influenzano la previsione del modello. I punti rosa indicano i pazienti che sono stati previsti come affetti da CKD e i punti blu indicano i pazienti che sono stati previsti come non affetti da CKD. Ora che conosciamo le caratteristiche principali che guidano la previsione, vediamo se la loro direzione di influenza è in accordo con le scoperte cliniche presentate in precedenza in questo articolo.
- La presenza di diabete mellito (‘dm_yes’) e ipertensione (‘htn_yes’) è associata alla presenza di CKD. Questo corrisponde alle scoperte cliniche, anche se ci si aspetterebbe di vederli più in alto in termini di importanza globale poiché sono importanti fattori di rischio associati a CKD.
- Avere bassi livelli di emoglobina (‘hemo’), basso volume di ematocrito (‘pcv’: la percentuale di volume dei globuli rossi nel sangue) e basso conteggio dei globuli rossi (‘rc’) sono associati a CKD. Questo corrisponde anche alle scoperte cliniche poiché i pazienti affetti da CKD non sono in grado di produrre livelli sufficienti di globuli rossi.
- Avere una bassa densità specifica dell’urina (‘sg’) è associato a CKD, cosa che può essere spiegata clinicamente poiché i reni perdono la loro capacità di concentrare l’urina.
- Avere un elevato livello di albumina nell’urina (‘al’) e alti livelli di creatinina sierica (‘sc’) sono associati a CKD, il che è in accordo con le scoperte cliniche poiché i reni perdono la loro capacità di filtrare il sangue in modo efficace.
- La presenza di globuli rossi nelle urine o di urine anomale (‘rbc_normal’; una caratteristica categorica binaria in cui il valore = 1 suggerisce urine normali senza globuli rossi e il valore = 0 suggerisce urine anomale che potrebbero contenere globuli rossi) è associata a CKD. Questo supporta le scoperte cliniche poiché l’ematuria è più comune nei pazienti affetti da CKD.
In sintesi, le principali caratteristiche e le loro direzioni di influenza sulla previsione sono in accordo con la letteratura medica.
Conclusioni
In questo articolo, ci sono due punti principali da considerare:
- La letteratura medica ha associato lo sviluppo e la progressione della CKD alle stesse principali caratteristiche che il modello di apprendimento automatico utilizza per classificare se un paziente è predetto di avere la CKD.
- La direzione in cui queste principali caratteristiche influenzano la variabile target supporta le scoperte cliniche, suggerendo che il modello non sia solo accurato al 100% nella previsione della CKD, ma anche significativo dal punto di vista medico e che i risultati siano completamente interpretabili.
Una possibile limitazione di questo studio è la ridotta dimensione del campione. Una volta disponibili ulteriori dati, il modello dovrebbe essere testato su un gruppo di pazienti più ampio per verificare se continua a funzionare con elevata precisione. Sarebbe anche interessante vedere se l’ordine di importanza delle caratteristiche cambia per un gruppo di pazienti più ampio.
Nel campo medico, il modello più accurato non è sempre il modello più significativo. In questo studio, è stato utilizzato SHAP per verificare se il nostro modello è in accordo con la letteratura medica. Il vantaggio del modello risultante è che non è solo altamente accurato, ma anche facilmente interpretabile e supportato da scoperte cliniche. Questo modello può essere di grande utilità nella telemedicina, dove può essere utilizzato per identificare pazienti a rischio più elevato di sviluppare la CKD. Studi futuri possono coinvolgere l’analisi delle singole osservazioni e vedere quali caratteristiche del modello guidano la previsione a livello individuale.
Il codice per questo progetto può essere trovato qui. Tutte le immagini presenti in questo articolo sono state generate da me tramite Google Colab.
Riferimenti
Licenza per il dataset originale: L. Rubini, P. Soundarapandian e P. Eswaran, Chronic_Kidney_Disease (2015), UCI Machine Learning Repository (CC BY 4.0)
Dataset “Chronic Kidney Disease” su Kaggle: https://www.kaggle.com/datasets/mansoordaku/ckdisease
Documentazione originale di SHAP: https://shap.readthedocs.io/en/latest/api_examples.html#plots
[1] Concetti di base sulla malattia renale cronica (2022), Centers for Disease Control and Prevention
[2] C.P. Kovesdy, Epidemiologia della malattia renale cronica: un aggiornamento 2022 (2022), Kidney International Supplements
[3] H. Shaikh, M.F. Hashmi e N.R. Aeddula, Anemia della malattia renale cronica (2023), National Library of Medicine
[4] Creatinina sierica (sangue) (2023), National Kidney Foundation
[5] J.A. Simerville, W.C. Maxted e J.J. Pahira, Uroanalisi: una revisione completa (2005), American Family Physician
[6] P.F. Orlandi, et al., Ematuria come fattore di rischio per la progressione della malattia renale cronica e la morte: risultati dello studio Chronic Renal Insufficiency Cohort (CRIC) (2018), BMC Nephrology
[7] Albuminuria (2016), National Institute of Diabetes and Digestive and Kidney Diseases
[8] R. Bagheri, Introduzione ai valori SHAP e la loro applicazione nell’apprendimento automatico (2022), Towards Data Science