L’effetto Lombard e come può aiutare con l’insufficienza uditiva
L'effetto Lombard e l'udito
TL;DR: L’effetto Lombard può essere applicato alla Conversione Vocale e alla Text-to-Speech per rendere la voce sintetica più comprensibile nel rumore.
Ti sei mai chiesto perché tendiamo a parlare più forte in una stanza rumorosa? Beh, anche i ricercatori del linguaggio e della lingua sono stati curiosi e hanno esplorato un concetto chiamato Effetto Lombard (scoperto da Étienne Lombard).
💬 L’Effetto Lombard in breve
Immaginati ad una festa, dove la musica suona e tutti stanno chiacchierando e ridendo. Ci si diverte! Per farti sentire dal tuo amico, il tuo cervello automaticamente aumenta il volume della tua voce, modifica la tonalità e addirittura regola la velocità del discorso. Ciò che è interessante è che tendiamo anche ad adattare la nostra voce in base al feedback che riceviamo dalla persona di fronte a noi e dal rumore intorno a noi, per assicurarci che capiscano il messaggio.
- Strategie digitali guidate dall’IA per lo sviluppo agile dei prodotti
- Candle Machine Learning minimalista in Rust
- Profilare il codice Python utilizzando timeit e cProfile
Ora, pensa a questo effetto applicato alla tecnologia, come i sistemi Text-to-Speech (TTS). Cosa succederebbe se Alexa o Google Home potessero parlare con un effetto Lombard? (Uno scenario già immaginato da SNL).
🔊 Effetto Lombard e Text-to-speech
Diversi lavori (Vedi [1], [2]) hanno esplorato come lo stile Lombard potesse essere applicato alla Text-to-Speech per migliorare l’intelligibilità. Il loro obiettivo era vedere se potevano allenarsi su una voce con registrazioni in stile Lombard e migliorare l’intelligibilità e la naturalezza. Hanno scoperto che era effettivamente un modo più naturale di migliorare l’intelligibilità rispetto all’elaborazione del segnale!
▴ Perché questo è importante
Invece di semplicemente aumentare il volume o elaborare il segnale alla fine della ricezione (come fanno la maggior parte degli apparecchi acustici), possiamo rendere il discorso più chiaro direttamente alla fonte!
Gli apparecchi acustici sono straordinari capolavori di ingegneria, ma presentano delle sfide. Non sono sempre comodi, possono essere costosi e alcune persone addirittura scelgono di non usarli regolarmente. Ma con il TTS in stile Lombard, il discorso viene automaticamente adattato per essere più distinto e facile da capire. Questo potrebbe essere un grande cambiamento, non solo per coloro che usano apparecchi acustici, ma anche per i non madrelingua (Vedi [3]) e chiunque si trovi in un ambiente rumoroso!
🚩 Problema attuale
I lavori menzionati in precedenza hanno utilizzato set di dati con molte esempi audio per una voce specifica. Cosa succede quando non si dispone di tutto ciò? Come possiamo sintetizzare una voce in stile Lombard senza dover registrare (faticoso, richiede molto tempo e costoso per i talenti vocali)?
🔍 Una soluzione?
La conversione vocale, il processo di trasferire la voce di una persona su registrazioni del discorso di qualcun altro, può essere applicata come approccio di aumento dei dati. L’idea è creare registrazioni della voce della persona in stile Lombard trasferendo l’identità del parlante sulle registrazioni del discorso Lombard.
📚 Il nostro studio
In un articolo che abbiamo presentato di recente al Clarity Workshop presso Interspeech 23′, abbiamo deciso di indagare su come poter preservare l’effetto Lombard durante la conversione vocale. Infatti, le informazioni sul parlante di destinazione potrebbero sopraffare le caratteristiche dell’effetto Lombard e non darci i risultati attesi. Vogliamo rispondere alla seguente domanda: Possiamo preservare lo stile di parlare Lombard responsabile dell’intelligibilità durante la Conversione Vocale, trasferendo anche l’identità del parlante?
Dato un modello di conversione vocale (VC), abbiamo esaminato diversi modi di condizionarlo. Qui di seguito puoi trovare i tre sistemi che abbiamo testato nei nostri esperimenti.
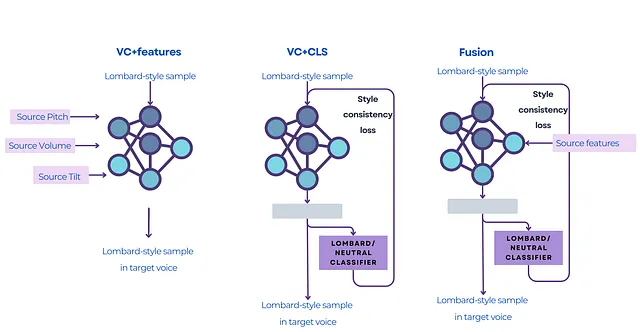
- VC+features (Condizionamento esplicito): Abbiamo prima deciso di isolare tre elementi chiave della voce: tonalità, volume e inclinazione. Abbiamo quindi fornito direttamente le caratteristiche estratte all’encoder del modello. Le abbiamo poi estratte sulle registrazioni Lombard e le abbiamo fornite al modello di conversione vocale per forzarlo a mantenerle nella registrazione finale, trasferendo anche la voce che vogliamo trasferire.
- VC+CLS (Condizionamento implicito): Cosa succede se vogliamo che il modello impari le caratteristiche da solo? Abbiamo testato questo aggiungendo un classificatore di stile che costringe il modello a mantenere lo stile di origine dopo la conversione vocale. Questa impostazione aiuta a preservare lo stile Lombard senza intoppi sulle caratteristiche da parte nostra.
- Fusion: Questo sistema combina entrambi i mondi con le caratteristiche selezionate attentamente e il classificatore che costringe il modello a mantenere lo stile di parlare originale.
Cosa abbiamo trovato? Come mostrato nel grafico a barre sottostante che mostra l’intelligibilità in condizioni di elevato rumore, abbiamo scoperto che
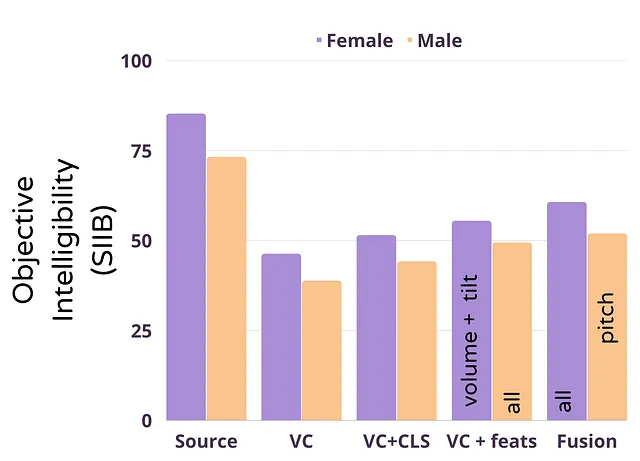
- In effetti, l’effetto Lombard viene perso durante la conversione
- Sia il condizionamento esplicito che implicito aiutano a migliorare l’intelligibilità finale
- La fusione funziona ancora meglio ma perde le informazioni del parlante di destinazione rendendola meno utile
- Le diverse caratteristiche hanno funzionato meglio per le voci femminili e maschili
👉 Qual è la conclusione?
Gli studi passati e il nostro lavoro mostrano che il TTS in stile Lombard aumenta effettivamente l’intelligibilità del parlato in ambienti rumorosi. Sebbene la naturalità possa essere compromessa, è meno evidente nel rumore e l’identità degli speaker non è così influenzata. Nel nostro studio, abbiamo scoperto che l’effetto di intelligibilità Lombard viene perso con la conversione vocale di base, ma utilizzando il condizionamento in modo esplicito o implicito siamo in grado di trasferirli meglio!
Consulta il nostro articolo qui per ulteriori dettagli!
🚀 Il futuro della parola intelligibile
Immagina un mondo in cui la sintesi del parlato imita i nostri adeguamenti naturali, rendendo la comunicazione più fluida in luoghi rumorosi. Con ulteriori ricerche e innovazioni, il TTS in stile Lombard potrebbe aiutare nelle attività quotidiane per le persone con problemi uditivi, come ascoltare musica, video di YouTube, guardare film, ecc., e migliorare le nostre interazioni con assistenti intelligenti e dispositivi attivati dalla voce!
Riferimenti
– [1] Bollepalli, Bajibabu, et al. “Adattamento normale a Lombard della sintesi del parlato utilizzando reti neurali ricorrenti a memoria a breve termine”. Speech Communication 110 (2019)
– [2] Paul, Dipjyoti, et al. “Miglioramento dell’intelligibilità del parlato nella sintesi del testo a parlato utilizzando la conversione dello stile di parola.” Proc. Interspeech (2020).
– [3] Marcoux, Katherine, et al. “Il beneficio di intelligibilità Lombard del parlato nativo e non nativo per ascoltatori nativi e non nativi.” Speech Communication 136 (2022)





