Comprensione di Flash-Attention e Flash-Attention-2 La via per aumentare la lunghezza del contesto dei modelli di linguaggio.
Comprensione di Flash-Attention-2 per aumentare il contesto dei modelli di linguaggio.
I due metodi forniscono miglioramenti significativi per elaborare sequenze di testo più lunghe nei modelli di linguaggio.

Recentemente ho avviato una newsletter educativa focalizzata sull’intelligenza artificiale, che conta già più di 160.000 iscritti. TheSequence è una newsletter orientata all’apprendimento automatico che richiede solo 5 minuti di lettura e non contiene hype, notizie, ecc. L’obiettivo è tenervi aggiornati su progetti di apprendimento automatico, articoli di ricerca e concetti. Provate a iscrivervi qui di seguito:
TheSequence | Jesus Rodriguez | Substack
La migliore fonte per rimanere aggiornati sugli sviluppi nell’intelligenza artificiale, nell’apprendimento automatico e nei dati…
thesequence.substack.com
Il ridimensionamento del contesto dei grandi modelli di linguaggio (LLM) rimane una delle sfide più grandi per espandere l’universo dei casi d’uso. Negli ultimi mesi, abbiamo visto fornitori come Anthropic o OpenAI spingere le lunghezze del contesto dei loro modelli a nuove vette. Questo trend è destinato a continuare, ma probabilmente richiederà alcune scoperte di ricerca. Uno dei lavori più interessanti in questo ambito è stato recentemente pubblicato dall’Università di Stanford. Chiamato FlashAttention, questa nuova tecnica è stata rapidamente adottata come uno dei principali meccanismi per aumentare il contesto dei LLM. La seconda iterazione di FlashAttention, FlashAttention-2, è stata pubblicata di recente. In questo articolo, vorrei fare una revisione dei fondamenti di entrambe le versioni.
FashAttention v1
Nel campo degli algoritmi all’avanguardia, FlashAttention emerge come un cambiamento di gioco. Questo algoritmo non solo riordina il calcolo dell’attenzione, ma utilizza anche tecniche classiche come il tiling e il recomputation per ottenere un notevole aumento di velocità e una riduzione sostanziale dell’utilizzo di memoria. Il cambiamento è trasformativo, passando da una memoria quadratica a una memoria lineare in relazione alla lunghezza della sequenza. Per la maggior parte degli scenari, FlashAttention funziona molto bene, ma ha un avvertimento: non è stato ottimizzato per sequenze eccezionalmente lunghe, in cui manca il parallelismo.
- Top importanti articoli di Computer Vision della settimana dal 4/9 al 10/9
- 10 Concetti Matematici per Programmatori
- Ricercatori di Princeton propongono CoALA un quadro concettuale di intelligenza artificiale per comprendere e costruire sistematicamente agenti linguistici
Quando si affronta la sfida di addestrare grandi trasformatori su sequenze estese, è fondamentale utilizzare tecniche moderne di parallelismo come il parallelismo dati, il parallelismo delle pipeline e il parallelismo tensoriale. Questi approcci dividono dati e modelli su numerose GPU, il che può comportare dimensioni di batch minime (pensate a un batch size di 1 con il parallelismo delle pipeline) e un numero modesto di heads, di solito compreso tra 8 e 12 con il parallelismo tensoriale. È proprio in questo scenario che FlashAttention cerca di ottimizzare.
Per ogni attenzione, FlashAttention adotta tecniche classiche di tiling per ridurre al minimo le letture e le scritture di memoria. Trasporta blocchi di query, chiavi e valori dalla HBM (memoria principale) della GPU alla sua SRAM (cache veloce). Dopo aver eseguito i calcoli di attenzione su questo blocco, scrive l’output nella HBM. Questa riduzione delle letture e delle scritture di memoria porta a un notevole aumento di velocità, spesso compreso tra 2 e 4 volte la velocità originale nella maggior parte dei casi d’uso.
La versione iniziale di FlashAttention si è impegnata nella parallelizzazione rispetto alle dimensioni del batch e al numero di heads. Coloro che conoscono bene la programmazione CUDA apprezzeranno l’impiego di un blocco di thread per elaborare ciascuna attenzione, con un totale di blocco di thread batch_size * num_heads. Ciascun blocco di thread viene attentamente pianificato per essere eseguito su un multiprocessore di streaming (SM), con una GPU A100 che dispone di un generoso numero di 108 di questi SM. Questa capacità di pianificazione brilla davvero quando batch_size * num_heads raggiunge valori considerevoli, ad esempio superiori o uguali a 80. In tali casi, consente l’utilizzo efficiente di quasi tutte le risorse computazionali della GPU.
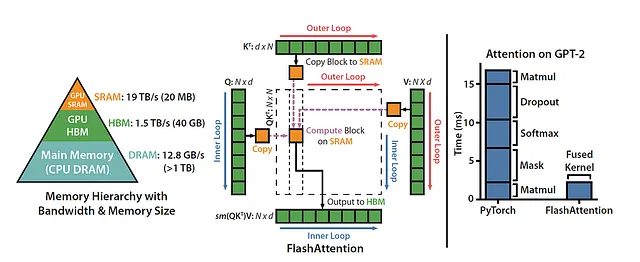
Tuttavia, quando si tratta di gestire sequenze lunghe – di solito associate a dimensioni di batch ridotte o a un numero limitato di heads – FlashAttention adotta un approccio diverso. Ora introduce la parallelizzazione sulla dimensione della lunghezza della sequenza, ottenendo notevoli miglioramenti di velocità adattati a questo dominio specifico.
Per quanto riguarda il passaggio all’indietro, FlashAttention opta per una strategia di parallelizzazione leggermente modificata. Ogni worker si occupa di un blocco di colonne all’interno della matrice di attenzione. Questi worker collaborano e comunicano per aggregare il gradiente relativo alla query, impiegando operazioni atomiche a questo scopo. È interessante notare che FlashAttention ha scoperto che la parallelizzazione per colonne è più efficiente della parallelizzazione per righe in questo contesto. La ridotta comunicazione tra i worker si rivela fondamentale, poiché la parallelizzazione per colonne comporta l’aggregazione del gradiente della query, mentre la parallelizzazione per righe comporta l’aggregazione del gradiente della chiave e del valore.

FlashAttention-2
Con FlashAttention-2, il team di Stanford apporta un’attenta raffinazione alla versione iniziale, concentrandosi sulla riduzione dei FLOP non matmul all’interno dell’algoritmo. Questo aggiustamento ha una profonda importanza nell’era delle moderne GPU, dotate di unità di calcolo specializzate come i Tensor Core di Nvidia, che accelerano notevolmente le moltiplicazioni di matrici (matmul).
FlashAttention-2 rivede anche la tecnica di softmax online su cui si basa. L’obiettivo è semplificare le operazioni di ridimensionamento, il controllo dei limiti e la mascheratura causale, preservando al contempo l’integrità dell’output.
Nella sua prima versione, FlashAttention sfruttava il parallelismo sia sulla dimensione del batch che sul numero di testate. Qui, ogni testata di attenzione veniva elaborata da un blocco di thread dedicato, risultando in un totale di (dimensione del batch * numero di testate) blocchi di thread. Questi blocchi di thread venivano pianificati in modo efficiente su multiprocessori di streaming (SM), con un esemplare di GPU A100 che vantava 108 SM. Questa strategia di pianificazione si è rivelata particolarmente efficace quando il numero totale di blocchi di thread era elevato, superando tipicamente 80, poiché consentiva l’utilizzo ottimale delle risorse computazionali della GPU.
Per migliorare in scenari che coinvolgono sequenze lunghe, spesso accompagnate da dimensioni di batch ridotte o un numero limitato di testate, FlashAttention-2 introduce una dimensione di parallelismo aggiuntiva: la parallelizzazione della lunghezza della sequenza. Questa adattamento strategico porta a notevoli miglioramenti di velocità in questo contesto particolare.
Anche all’interno di ogni blocco di thread, FlashAttention-2 deve suddividere opportunamente il carico di lavoro tra diversi warp, che rappresentano gruppi di 32 thread che operano all’unisono. Di solito vengono impiegati 4 o 8 warp per blocco di thread, e lo schema di suddivisione è illustrato di seguito. In FlashAttention-2, questa metodologia di suddivisione viene raffinata, al fine di ridurre la sincronizzazione e la comunicazione tra i vari warp, minimizzando così le letture e le scritture nella memoria condivisa.
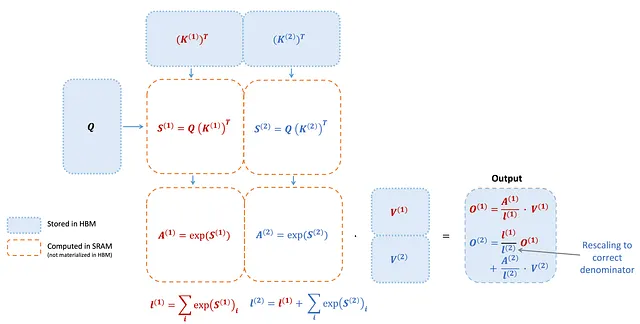
Nella configurazione precedente, FlashAttention divideva K e V tra 4 warp, mantenendo al contempo l’accessibilità di Q per tutti i warp, chiamato “sliced-K” scheme. Tuttavia, questo approccio mostrava inefficienze, poiché tutti i warp dovevano scrivere i loro risultati intermedi nella memoria condivisa, sincronizzarsi e quindi aggregare questi risultati. Queste operazioni sulla memoria condivisa rappresentavano un collo di bottiglia delle prestazioni per il passaggio in avanti di FlashAttention.
In FlashAttention-2, la strategia prende una direzione diversa. Ora Q viene allocato tra 4 warp, garantendo che K e V rimangano accessibili a tutti i warp. Dopo che ogni warp effettua una moltiplicazione di matrici per ottenere una porzione di Q K^T, semplicemente lo moltiplica con la porzione condivisa di V per ottenere la propria porzione di output. Questa disposizione elimina la necessità di comunicazione tra warp. La riduzione delle letture e scritture nella memoria condivisa si traduce in un significativo aumento di velocità.
La versione precedente di FlashAttention supportava dimensioni di testata fino a 128, sufficienti per la maggior parte dei modelli ma lasciando alcuni in secondo piano. FlashAttention-2 estende il supporto alle dimensioni di testata fino a 256, adattandosi a modelli come GPT-J, CodeGen, CodeGen2 e StableDiffusion 1.x. Questi modelli possono ora sfruttare FlashAttention-2 per una migliore velocità ed efficienza di memoria.
Inoltre, FlashAttention-2 introduce il supporto per l’attenzione multi-query (MQA) e l’attenzione raggruppata-query (GQA). Queste sono varianti specializzate di attenzione in cui più testate della query si rivolgono contemporaneamente alla stessa testa della chiave e del valore. Questa manovra strategica mira a ridurre le dimensioni della cache KV durante l’inferenza, portando a un aumento significativo della velocità di inferenza.
Miglioramenti
Il team di Stanford ha valutato FlashAttention-2 su diversi benchmark, ottenendo miglioramenti notevoli rispetto alla versione originale e ad altre alternative. I test includevano diverse variazioni dell’architettura dell’attenzione e i risultati sono stati piuttosto significativi.
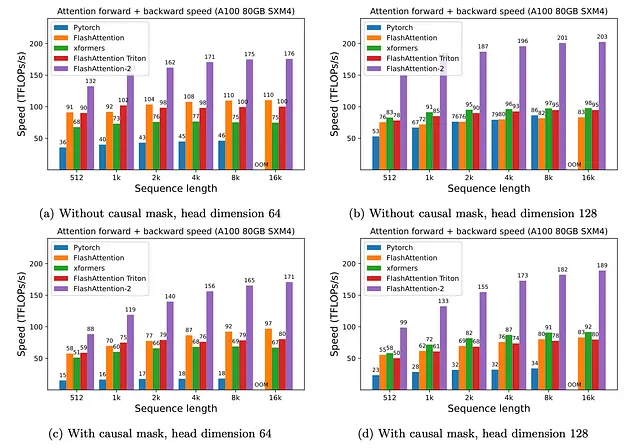
FlashAttention e FlashAttention-2 sono due delle tecniche fondamentali utilizzate per scalare il contesto dei LLM. La ricerca rappresenta una delle più grandi scoperte scientifiche in questo campo e sta influenzando nuovi metodi che possono aiutare ad aumentare la capacità dei LLM.






