Da Zero a Eroe Crea il tuo primo modello di apprendimento automatico con PyTorch
Crea il tuo primo modello di apprendimento automatico con PyTorch

Motivazione
PyTorch è il framework di Deep Learning basato su Python più ampiamente utilizzato. Fornisce un enorme supporto per tutte le architetture di apprendimento automatico e i flussi di dati. In questo articolo, affrontiamo tutti i concetti di base del framework per aiutarti a iniziare a implementare i tuoi algoritmi.
- Incontra Verba uno strumento open-source per costruire la tua pipeline di generazione di recupero aumentata RAG e utilizzare LLM per output basati internamente.
- Lavorare con Big Data Strumenti e Tecniche
- I ricercatori di Sony propongono BigVSAN Rivoluzionare la qualità audio con la suddivisione delle reti avversarie in vocoder basati su GAN.
Tutte le implementazioni di apprendimento automatico hanno 4 fasi principali:
- Gestione dei dati
- Architettura del modello
- Ciclo di addestramento
- Valutazione
Affrontiamo tutte queste fasi mentre implementiamo il nostro modello di classificazione delle immagini MNIST in PyTorch. Questo ti familiarizzerà con il flusso generale di un progetto di apprendimento automatico.
Importazioni
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
# Utilizziamo il dataset MNIST fornito da PyTorch
from torchvision.datasets.mnist import MNIST
import torchvision.transforms as transforms
# Importiamo il modello implementato in un file diverso
from model import Classifier
import matplotlib.pyplot as plt
Il modulo torch.nn fornisce supporto per le architetture delle reti neurali e ha implementazioni integrate per livelli popolari come livelli densi, reti neurali convoluzionali e molti altri.
torch.optim fornisce implementazioni per ottimizzatori come la discesa del gradiente stocastica e Adam.
Sono disponibili anche altri moduli di utilità per il supporto alla gestione dei dati e alle trasformazioni. Ne parleremo più dettagliatamente in seguito.
Dichiarazione degli iperparametri
Ogni iperparametro verrà spiegato in modo più dettagliato laddove appropriato. Tuttavia, è una buona pratica dichiararli all’inizio del nostro file per facilitare la modifica e la comprensione.
INPUT_SIZE = 784 # Immagini 28x28 appiattite
NUM_CLASSES = 10 # Cifre scritte a mano da 0 a 9.
BATCH_SIZE = 128 # Utilizziamo mini-batch per l'addestramento
LEARNING_RATE = 0.01 # Passo dell'ottimizzatore
NUM_EPOCHS = 5 # Epoche totali di addestramento
Caricamento dei dati e trasformazioni
data_transforms = transforms.Compose([
transforms.ToTensor(),
transforms.Lambda(lambda x: torch.flatten(x))
])
train_dataset = MNIST(root=".data/", train=True, download=True, transform=data_transforms)
test_dataset = MNIST(root=".data/", train=False, download=True, transform=data_transforms)
MNIST è un popolare dataset per la classificazione delle immagini, fornito di default in PyTorch. Consiste in immagini in scala di grigi di 10 cifre scritte a mano da 0 a 9. Ogni immagine ha dimensioni di 28 pixel per 28 pixel e il dataset contiene 60000 immagini di addestramento e 10000 immagini di test.
Carichiamo separatamente il dataset di addestramento e di test, indicato dall’argomento train nella funzione di inizializzazione di MNIST. L’argomento root dichiara la directory in cui il dataset deve essere scaricato.
Tuttavia, passiamo anche un ulteriore argomento transform. Per PyTorch, tutti gli input e gli output devono essere nel formato Torch.Tensor. Questo formato tensoriale fornisce supporto aggiuntivo per la manipolazione dei dati. Tuttavia, i dati MNIST che carichiamo sono nel formato PIL.Image. Dobbiamo trasformare le immagini in tensori compatibili con PyTorch. Di conseguenza, passiamo le seguenti trasformazioni:
data_transforms = transforms.Compose([
transforms.ToTensor(),
transforms.Lambda(lambda x: torch.flatten(x))
])
La trasformazione ToTensor() converte le immagini nel formato tensoriale. Successivamente, passiamo una trasformazione Lambda aggiuntiva. La funzione Lambda ci consente di implementare trasformazioni personalizzate. Qui dichiariamo una funzione per appiattire l’input. Le immagini hanno dimensioni 28×28, ma le appiattiamo cioè le convertiamo in un array unidimensionale di dimensioni 28×28 o 784. Questo sarà importante in seguito quando implementeremo il nostro modello.
La funzione Compose combina in sequenza tutte le trasformazioni. Prima i dati vengono convertiti nel formato tensoriale e poi appiattiti in un array monodimensionale.
Dividere i nostri dati in lotti
Per motivi computazionali e di addestramento, non possiamo passare l’intero dataset al modello in una volta. Dobbiamo dividere il nostro dataset in mini-batch che verranno alimentati al modello in ordine sequenziale. Ciò consente un addestramento più rapido e aggiunge casualità al nostro dataset, il che può aiutare a un addestramento stabile.
PyTorch fornisce un supporto integrato per il batching dei nostri dati. La classe DataLoader del modulo torch.utils può creare batch di dati, dato un modulo dataset di torch. Come sopra, abbiamo già caricato il dataset.
train_dataloader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True)
test_dataloader = DataLoader(test_dataset, batch_size=BATCH_SIZE, shuffle=False)
Passiamo il dataset al nostro dataloader e il nostro iperparametro batch_size come argomenti di inizializzazione. Questo crea un dataloader iterabile, quindi possiamo facilmente iterare su ogni batch utilizzando un semplice ciclo for.
La nostra immagine iniziale era di dimensioni (784, ) con un singolo label associato. Il batching combina quindi diverse immagini e label in un batch. Ad esempio, se abbiamo una dimensione di batch di 64, la dimensione di input in un batch diventerà (64, 784) e avremo 64 label associate per ogni batch.
Abbiamo anche mescolato il batch di addestramento, il che cambia le immagini all’interno di un batch per ogni epoca. Ciò consente un addestramento stabile e una convergenza più rapida dei parametri del nostro modello.
Definire il nostro modello di classificazione
Utilizziamo una semplice implementazione composta da 3 hidden layer. Anche se semplice, questo può fornire una comprensione generale della combinazione di diversi layer per implementazioni più complesse.
Come descritto sopra, abbiamo un tensore di input di dimensioni (784, ) e 10 diverse classi di output, una per ogni cifra da 0 a 9.
** Per l’implementazione del modello, possiamo ignorare la dimensione del batch.
import torch
import torch.nn as nn
class Classificatore(nn.Module):
def __init__(
self,
input_size:int,
num_classes:int
) -> None:
super().__init__()
self.input_layer = nn.Linear(input_size, 512)
self.hidden_1 = nn.Linear(512, 256)
self.hidden_2 = nn.Linear(256, 128)
self.output_layer = nn.Linear(128, num_classes)
self.activation = nn.ReLU()
def forward(self, x):
# Passare l'input in modo sequenziale attraverso ogni layer denso e attivazione
x = self.activation(self.input_layer(x))
x = self.activation(self.hidden_1(x))
x = self.activation(self.hidden_2(x))
return self.output_layer(x)
Innanzitutto, il modello deve ereditare dalla classe torch.nn.Module. Questo fornisce funzionalità di base per le architetture delle reti neurali. Quindi dobbiamo implementare due metodi, __init__ e forward.
Nel metodo __init__, dichiariamo tutti i layer che il modello utilizzerà. Utilizziamo i layer Lineari (anche chiamati Dense) forniti da PyTorch. Il primo layer mappa l’input su 512 neuroni. Possiamo passare input_size come parametro del modello, in modo da poterlo utilizzare successivamente per input di dimensioni diverse. Il secondo layer mappa i 512 neuroni su 256. Il terzo hidden layer mappa i 256 neuroni dal layer precedente a 128. Infine, il layer di output si riduce infine alla dimensione dell’output. La nostra dimensione di output sarà un tensore di dimensione (10, ) perché stiamo prevedendo dieci numeri diversi.
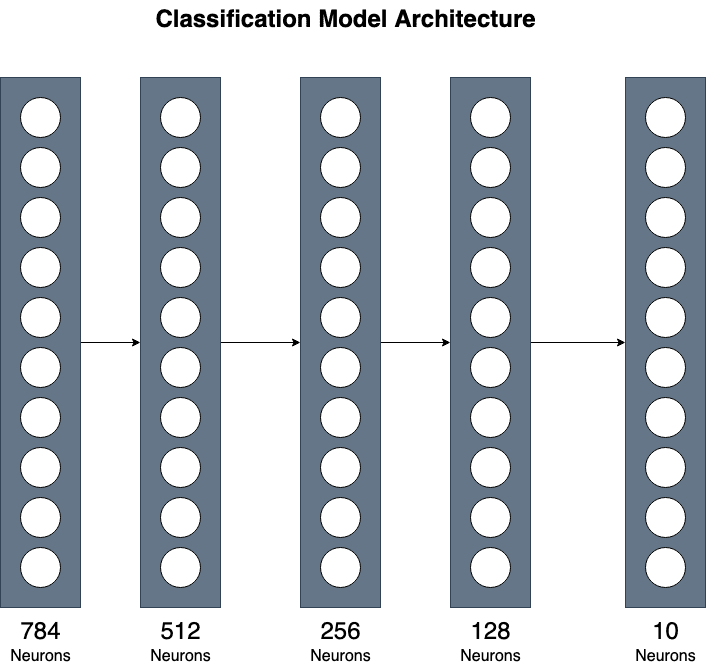
Inoltre, inizializziamo un layer di attivazione ReLU per la non linearità nel nostro modello.
La funzione forward riceve immagini e forniamo il codice per elaborare l’input. Utilizziamo i layer dichiarati e passiamo in modo sequenziale il nostro input attraverso ogni layer, con un layer di attivazione ReLU intermedio.
Nel nostro codice principale, possiamo quindi inizializzare il modello fornendogli la dimensione dell’input e dell’output per il nostro dataset.
model = Classificatore(input_size=784, num_classes=10)
model.to(DEVICE)
Una volta inizializzato, cambiamo il dispositivo del modello (che può essere sia la GPU CUDA che la CPU). Abbiamo verificato il nostro dispositivo quando abbiamo inizializzato gli iperparametri. Ora dobbiamo cambiare manualmente il dispositivo per i nostri tensori e i layer del modello.
Ciclo di addestramento
Prima di tutto, dobbiamo dichiarare la nostra funzione di perdita e l’ottimizzatore che verranno utilizzati per ottimizzare i parametri del nostro modello.
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=LEARNING_RATE)
Prima di tutto, dobbiamo dichiarare la nostra funzione di perdita e l’ottimizzatore che verranno utilizzati per ottimizzare i parametri del nostro modello.
Utilizziamo la perdita di entropia incrociata che viene principalmente utilizzata per modelli di classificazione multi-etichetta. Applica prima softmax alle previsioni e calcola le etichette target fornite e i valori previsti.
L’ottimizzatore Adam è la funzione di ottimizzazione più utilizzata che consente una discesa del gradiente stabile verso la convergenza. È la scelta predefinita per l’ottimizzatore al giorno d’oggi e fornisce risultati soddisfacenti. Passiamo i parametri del nostro modello come argomento che indica i pesi che verranno ottimizzati.
Per il nostro ciclo di addestramento, costruiamo passo dopo passo e riempiamo le parti mancanti man mano che acquisiamo una comprensione.
Come punto di partenza, iteriamo su tutto il dataset più volte (chiamato epoca) e ottimizziamo il nostro modello ogni volta. Tuttavia, abbiamo diviso i nostri dati in batch. Quindi, per ogni epoca, dobbiamo iterare anche su ogni batch. Il codice per questo sarà il seguente:
for epoch in range(NUM_EPOCHS):
for batch in iter(train_dataloader):
# Addestra il modello per ogni batch.
Ora possiamo addestrare il modello dato un singolo input batch. Il nostro batch è composto da immagini ed etichette. Prima di tutto, dobbiamo separare ognuno di questi. Il nostro modello richiede solo immagini come input per effettuare previsioni. Confrontiamo quindi le previsioni con le etichette vere, per stimare le prestazioni del nostro modello.
for epoch in range(NUM_EPOCHS):
for batch in iter(train_dataloader):
images, labels = batch # Separa input ed etichette
# Converti i Tensor dei dispositivi hardware in GPU o CPU
images = images.to(DEVICE)
labels = labels.to(DEVICE)
# Chiama la funzione model.forward() per generare previsioni
predictions = model(images)
Passiamo il batch di immagini direttamente al modello che verrà elaborato dalla funzione forward definita all’interno del modello. Una volta ottenute le previsioni, possiamo ottimizzare i pesi del nostro modello.
Il codice di ottimizzazione è il seguente:
# Calcola la perdita di entropia incrociata
loss = criterion(predictions, labels)
# Cancella i valori del gradiente dal batch precedente
optimizer.zero_grad()
# Calcola il gradiente di backpropagation in base alla perdita
loss.backward()
# Ottimizza i pesi del modello
optimizer.step()
Utilizzando il codice precedente, possiamo calcolare tutti i gradienti di backpropagation e ottimizzare i pesi del modello utilizzando l’ottimizzatore Adam. Tutti i codici sopra combinati possono addestrare il nostro modello verso la convergenza.
Il ciclo di addestramento completo è il seguente:
for epoch in range(NUM_EPOCHS):
total_epoch_loss = 0
steps = 0
for batch in iter(train_dataloader):
images, labels = batch # Separa input ed etichette
# Converti i Tensor dei dispositivi hardware in GPU o CPU
images = images.to(DEVICE)
labels = labels.to(DEVICE)
# Chiama la funzione model.forward() per generare previsioni
predictions = model(images)
# Calcola la perdita di entropia incrociata
loss = criterion(predictions, labels)
# Cancella i valori del gradiente dal batch precedente
optimizer.zero_grad()
# Calcola il gradiente di backpropagation in base alla perdita
loss.backward()
# Ottimizza i pesi del modello
optimizer.step()
steps += 1
total_epoch_loss += loss.item()
print(f'Epoca: {epoch + 1} / {NUM_EPOCHS}: Perdita media: {total_epoch_loss / steps}')
La perdita diminuisce gradualmente e raggiunge valori vicini a zero. Quindi, possiamo valutare il modello sul dataset di test che abbiamo dichiarato inizialmente.
Valutazione delle prestazioni del nostro modello
for batch in iter(test_dataloader):
images, labels = batch
images = images.to(DEVICE)
labels = labels.to(DEVICE)
predictions = model(images)
# Prendendo l'etichetta prevista con la probabilità più alta
predictions = torch.argmax(predictions, dim=1)
predizioni_corrette += (predictions == labels).sum().item()
predizioni_totali += labels.shape[0]
print(f"\nACCURATEZZA DEL TEST: {((predizioni_corrette / predizioni_totali) * 100):.2f}")
Simile al ciclo di addestramento, iteriamo su ogni batch nel dataset di test per la valutazione. Generiamo previsioni per gli input. Tuttavia, per la valutazione, abbiamo bisogno solo dell’etichetta con la probabilità più alta. La funzione argmax fornisce questa funzionalità per ottenere l’indice del valore con il valore più alto nel nostro array di previsioni.
Per il punteggio di precisione, possiamo quindi confrontare se l’etichetta prevista corrisponde all’etichetta target reale. Calcoliamo quindi la precisione dei numeri di etichette corrette diviso per il totale delle etichette previste.
Risultati
Ho allenato il modello solo per cinque epoche e ho raggiunto una precisione di test superiore al 96 percento, rispetto alla precisione del 10 percento prima dell’addestramento. L’immagine sottostante mostra le previsioni del modello dopo cinque epoche di addestramento.
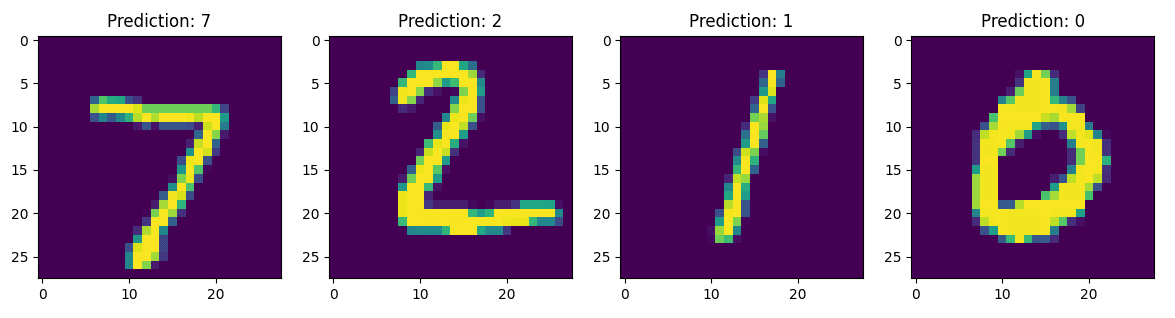
Ecco fatto. Hai ora implementato un modello da zero che può differenziare cifre scritte a mano solo dai valori dei pixel dell’immagine.
Questo non è in alcun modo una guida esaustiva su PyTorch, ma ti fornisce una comprensione generale della struttura e del flusso di dati in un progetto di apprendimento automatico. Questa è comunque una conoscenza sufficiente per iniziare a implementare architetture all’avanguardia nell’apprendimento approfondito.
Codice completo
Il codice completo è il seguente:
model.py:
import torch
import torch.nn as nn
class Classifier(nn.Module):
def __init__(
self,
input_size:int,
num_classes:int
) -> None:
super().__init__()
self.input_layer = nn.Linear(input_size, 512)
self.hidden_1 = nn.Linear(512, 256)
self.hidden_2 = nn.Linear(256, 128)
self.output_layer = nn.Linear(128, num_classes)
self.activation = nn.ReLU()
def forward(self, x):
# Pass Input Sequentially through each dense layer and activation
x = self.activation(self.input_layer(x))
x = self.activation(self.hidden_1(x))
x = self.activation(self.hidden_2(x))
return self.output_layer(x)
main.py
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
# Using MNIST dataset provided by PyTorch
from torchvision.datasets.mnist import MNIST
import torchvision.transforms as transforms
# Import Model implemented in a different file
from model import Classifier
import matplotlib.pyplot as plt
if __name__ == "__main__":
INPUT_SIZE = 784 # Flattened 28x28 images
NUM_CLASSES = 10 # 0-9 hand-written digits.
BATCH_SIZE = 128 # Using Mini-Batches for Training
LEARNING_RATE = 0.01 # Opitimizer Step
NUM_EPOCHS = 5 # Total Training Epochs
DEVICE = 'cuda' if torch.cuda.is_available() else 'cpu'
# Will be used to convert Images to PyTorch Tensors
data_transforms = transforms.Compose([
transforms.ToTensor(),
transforms.Lambda(lambda x: torch.flatten(x))
])
train_dataset = MNIST(root=".data/", train=True, download=True, transform=data_transforms)
test_dataset = MNIST(root=".data/", train=False, download=True, transform=data_transforms)
train_dataloader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True)
test_dataloader = DataLoader(test_dataset, batch_size=BATCH_SIZE, shuffle=False)
model = Classifier(input_size=784, num_classes=10)
model.to(DEVICE)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=LEARNING_RATE)
for epoch in range(NUM_EPOCHS):
total_epoch_loss = 0
steps = 0
for batch in iter(train_dataloader):
images, labels = batch # Separate inputs and labels
# Convert Tensor Hardware Devices to either GPU or CPU
images = images.to(DEVICE)
labels = labels.to(DEVICE)
# Calls the model.forward() function to generate predictions
predictions = model(images)
# Calculate Cross Entropy Loss
loss = criterion(predictions, labels)
# Clears gradient values from previous batch
optimizer.zero_grad()
# Computes backprop gradient based on the loss
loss.backward()
# Optimizes the model weights
optimizer.step()
steps += 1
total_epoch_loss += loss.item()
print(f'Epoca: {epoch + 1} / {NUM_EPOCHS}: Perdita media: {total_epoch_loss / steps}')
# Save Trained Model
torch.save(model.state_dict(), 'trained_model.pth')
model.eval()
correct_predictions = 0
total_predictions = 0
for batch in iter(test_dataloader):
images, labels = batch
images = images.to(DEVICE)
labels = labels.to(DEVICE)
predictions = model(images)
# Taking the predicted label with highest probability
predictions = torch.argmax(predictions, dim=1)
correct_predictions += (predictions == labels).sum().item()
total_predictions += labels.shape[0]
print(f"\nACCURATEZZA DEL TEST: {((correct_predictions / total_predictions) * 100):.2f}")
# -- Codice per la visualizzazione dei risultati -- #
batch = next(iter(test_dataloader))
images, labels = batch
fig, ax = plt.subplots(nrows=1, ncols=4, figsize=(16,8))
for i in range(4):
image = images[i]
prediction = torch.softmax(model(image), dim=0)
prediction = torch.argmax(prediction, dim=0)
# print(type(prediction), type(prediction.item()))
ax[i].imshow(image.view(28,28))
ax[i].set_title(f'Previsione: {prediction.item()}')
plt.show()Muhammad Arham è un Ingegnere di Deep Learning che lavora in Visione Artificiale e Elaborazione del Linguaggio Naturale. Ha lavorato sulla distribuzione e l’ottimizzazione di diverse applicazioni di intelligenza artificiale generativa che hanno raggiunto le classifiche globali di Vyro.AI. È interessato alla creazione e all’ottimizzazione di modelli di apprendimento automatico per sistemi intelligenti e crede nel miglioramento continuo.






