7 Lezioni dal Corso di Deep Learning di Fast.AI
7 Lezioni Fast.AI Corso Deep Learning
Cosa ho imparato dal corso di DL più popolare
Recentemente ho completato il corso di Deep Learning pratico di Fast.AI. Ho frequentato molti corsi di Machine Learning in passato, quindi posso fare dei confronti. Questo è sicuramente uno dei più pratici e ispiratori. Quindi, vorrei condividere con voi le mie principali conclusioni.
Riguardo al corso
Il corso Fast.AI è guidato da Jeremy Howard, un ricercatore fondatore di Fast.AI. In passato era anche il primo nella classifica di Kaggle. Quindi puoi sicuramente fidarti della sua competenza in Machine Learning e Deep Learning.
Il corso copre le basi del Deep Learning e delle Reti Neurali e spiega anche gli algoritmi degli Alberi Decisionali. La versione attuale è del 2022, quindi suppongo che i contenuti siano cambiati rispetto alle recensioni precedenti su TDS.
Questo corso è progettato per persone con una certa esperienza di programmazione. Nella maggior parte dei casi vengono utilizzati esempi di codice anziché formule. Devo confessare che per me è più facile capire il codice dopo averlo scritto per anni, anche se ho una laurea magistrale in Matematica.
- Dalle codifiche ai embedding
- Come Archiviare Dati Storici in Modo Molto Più Efficientemente
- Sintetizza i podcast con ChatGPT Sfrutta l’IA per estrarre informazioni
Un’altra caratteristica interessante di questo corso è l’approccio top-down. Si parte con un modello di Machine Learning funzionante. Ad esempio, ho creato la mia prima app basata su Deep Learning durante la seconda settimana del corso. È un classificatore di immagini che può riconoscere le mie razze di cani preferite. Successivamente, nelle settimane successive, si approfondisce e si comprende come funziona tutto.
Passiamo ora alle mie principali conclusioni da questo corso.
Lezione n. 1: Matematica necessaria per comprendere il Deep Learning
Iniziamo con qualcosa di semplice. Prometto che le conclusioni seguenti saranno meno banali.
Credo sia importante parlarne perché molte persone sono intimidite dal Deep Learning. Il DL è considerato una scienza complicata, ma si basa su pochi concetti matematici che potresti imparare in un giorno.
Una Rete Neurale è una combinazione di funzioni lineari e attivazioni. Ecco una funzione lineare.
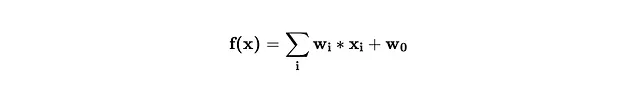
Dato che una combinazione di funzioni lineari è ancora lineare, abbiamo bisogno di attivazioni che aggiungano non linearità.
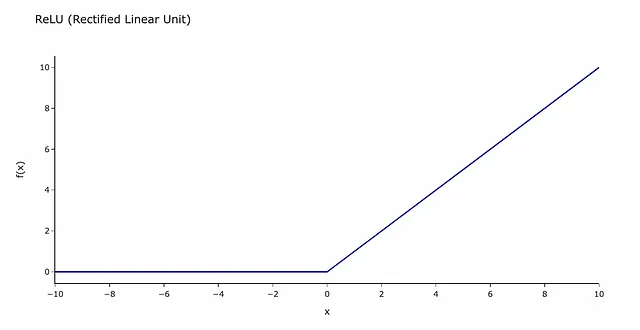
La funzione di attivazione più comune è ReLU (Rectified Linear Unit). Può sembrare spaventosa, ma in realtà è solo una funzione come questa.
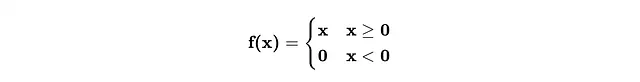
Puoi pensarla come una barriera che i segnali devono superare. Se un segnale è al di sotto della soglia (0 nel nostro caso), le sue informazioni non passeranno al livello successivo della Rete Neurale.
Alcuni altri concetti matematici utilizzati:
- SGD (Stochastic Gradient Descent) – un approccio di ottimizzazione basato sul calcolo del gradiente. Puoi leggere un articolo per avere una comprensione generale di come funziona.
- Moltiplicazione di matrici aiuta a eseguire calcoli più rapidamente in batch. C’è anche un ottimo articolo a riguardo.
Se desideri imparare tutti i dettagli, consulta la lezione sulle fondamenta delle reti neurali del corso Fast.AI.
Lezione n. 2: Come pulire i tuoi dati
Siamo abituati a iniziare l’analisi pulendo i dati. Abbiamo tutti sentito il mantra “spazzatura dentro – spazzatura fuori” molte volte. Sorprendentemente, addestrare un modello semplice e poi usarlo per pulire i tuoi dati potrebbe essere più efficace.
Puoi addestrare un modello semplice e poi osservare i casi con la perdita più alta per individuare eventuali problemi. Nel mio articolo precedente, questo approccio mi ha aiutato a individuare immagini con etichette errate.
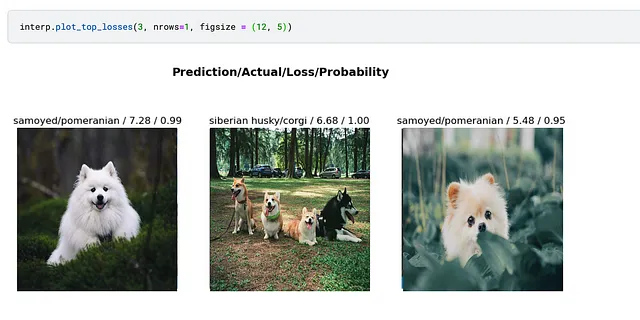
Crea la tua prima applicazione di Deep Learning in meno di un’ora
Deploy di un Modello di Classificazione delle Immagini utilizzando HuggingFace Spaces e Gradio
towardsdatascience.com
Lezione n. 3: Come scegliere un modello di Visione Artificiale
Oggi esistono molti modelli pre-addestrati. Ad esempio, PyTorch Image Models (timm) ha 1.242 modelli.
import timmpretrained_models = timm.list_models(pretrained=True)print(len(pretrained_models))print(pretrained_models[:5])1242['bat_resnext26ts.ch_in1k', 'beit_base_patch16_224.in22k_ft_in22k', 'beit_base_patch16_224.in22k_ft_in22k_in1k', 'beit_base_patch16_384.in22k_ft_in22k_in1k', 'beit_large_patch16_224.in22k_ft_in22k']Come principiante, ci si sente spesso bloccati di fronte a molte opzioni. Per fortuna, esiste uno strumento utile per scegliere l’architettura di Deep Learning.
Questo grafico mostra la relazione tra il tempo di inferenza (quanto tempo impiega per elaborare un’immagine) e l’accuratezza su ImageNet.

Come ci si potrebbe aspettare, c’è un compromesso tra velocità e accuratezza, quindi è necessario decidere quale è più importante. Dipende molto dal tuo compito. Hai bisogno che il tuo modello sia più veloce o più preciso?
È meglio iniziare con un modello piccolo ed iterare. La regola generale è creare il primo modello il primo giorno. In questo modo, puoi utilizzare modelli semplici come Resnet18 o Resnet34 per provare diverse tecniche di data augmentation o dataset esterni. Poiché stai lavorando con un modello semplice, le iterazioni saranno rapide. Puoi passare ad architetture di modelli più lente quando trovi la versione migliore.
Consiglio di Jeremy Howard: “Prova le architetture complesse solo alla fine”.
Lezione n. 4: Come allenare modelli grandi su Kaggle
Molti principianti utilizzano i notebook di Kaggle per il Machine Learning. Le GPU di Kaggle hanno una memoria limitata, quindi potresti esaurire la memoria, specialmente quando si utilizzano modelli grandi.
C’è un trucco utile che può risolvere questo problema. Si chiama Accumulo dei Gradienti (Gradient Accumulation). Con l’Accumulo dei Gradienti, non aggiorniamo i pesi dopo ogni batch, ma sommiamo i gradienti per K batch. Quindi, aggiorniamo i pesi del modello con questo gradiente accumulato per il batch totale uguale a K * batch_size, in modo che per ogni iterazione abbiamo una dimensione del batch K volte più piccola.
L’Accumulo dei Gradienti è assolutamente matematicamente identico a meno che la normalizzazione del batch (batch normalization) venga utilizzata nell’architettura del modello. Ad esempio, convnext non utilizza la normalizzazione del batch, quindi non c’è differenza.
Con questo approccio, utilizziamo significativamente meno memoria. Ciò significa che non è necessario acquistare GPU giganti, puoi adattare il tuo modello anche sul tuo laptop.
Puoi trovare l’esempio completo su Kaggle.
Lezione n. 5: Quali algoritmi di Machine Learning utilizzare
Oggi ci sono molte tecniche di Machine Learning diverse. Ad esempio, la documentazione di scikit-learn ha almeno una dozzina di approcci per il Machine Learning Supervisionato.
Jeremy Howard suggerisce di concentrarsi solo su un paio di tecniche essenziali:
- Se hai dati strutturati, dovresti iniziare con gli insiemi di alberi decisionali (Random Forest o algoritmi di Gradient Boosting).
- La migliore soluzione per dati non strutturati (come testi naturali, audio, video o immagini) è una rete neurale multistrato.
Le reti neurali sono applicabili anche ai dati strutturati, ma gli alberi decisionali sono spesso più facili da usare:
- Puoi addestrare un insieme di alberi decisionali molto più velocemente.
- Hanno meno parametri da regolare.
- Non è necessaria una GPU speciale per addestrarli.
- Inoltre, gli alberi decisionali sono spesso più facili da interpretare e capire il motivo per cui si ottiene un certo risultato per ogni oggetto, ad esempio, quali caratteristiche sono i predittori più forti e quali possiamo tranquillamente ignorare.
Se confrontiamo gli insiemi di alberi decisionali, Random Forest è più facile da usare (perché è quasi impossibile sovradattare). Tuttavia, Gradient Boosting di solito fornisce risultati leggermente migliori.
Lezione n. 6: Funzioni utili di Python
Anche se uso Python e Pandas da quasi dieci anni, ho scoperto anche un paio di trucchi utili di Pandas.
Il famoso dataset del Titanic è stato utilizzato per mostrare la potenza di Pandas. Diamo un’occhiata.
Il primo esempio ci mostra come convertire una colonna in una stringa, ottenere la prima lettera e convertirla usando un dizionario. Nota che se un valore non è menzionato nel dizionario, verrà restituito NaN.
# mio approccio abitualedecks_dict = {'A': 'ABC', 'B': 'ABC', 'C': 'ABC', 'D': 'DE', 'E': 'DE', 'F': 'FG', 'G': 'FG'}df['Deck'] = df.Cabin.map( lambda x: decks_dict.get(str(x)[0]))# versione dal corso df['Deck'] = df.Cabin.str[0].map(dict(A="ABC", B="ABC", C="ABC", D="DE", E="DE", F="FG", G="FG"))Il prossimo esempio mostra come calcolare la frequenza utilizzando la funzione di trasformazione. Questa versione è più concisa rispetto alla merge che di solito uso.
# mio approccio abitualedf = df.merge( df.groupby('Ticket', as_index = False).PassengerId.count()\ .rename(columns = {'PassengerId': 'TicketFreq'}))# versione dal corso df['TicketFreq'] = df.groupby('Ticket')['Ticket'].transform('count')L’ultimo esempio è il più complesso su come analizzare i titoli.
# mio approccio abitualedf['Title'] = df.Name.map(lambda x: x.split(', ')[1].split('.')[0])df['Title'] = df.Title.map( lambda x: x if x in ('Mr', 'Miss', 'Mrs', 'Master') else None)# versione dal corso df['Title'] = df.Name.str.split(', ', expand=True)[1]\ .str.split('.', expand=True)[0]df['Title'] = df.Title.map(dict(Mr="Mr",Miss="Miss",Mrs="Mrs",Master="Master"))Vale la pena guardare la prima parte df per capire come funziona. Puoi eseguire il codice:df.Name.str.split(‘, ‘, expand=True) e vedere un dataframe in cui i nomi sono suddivisi da virgole su due colonne.

Quindi, selezioniamo colonna 1 e facciamo una divisione simile in base al punto. La seconda riga sostituisce tutti i casi diversi da Mr, Mrs, Miss o Master con NaN.
A dir la verità, continuerei a usare il mio approccio abituale per l’ultimo caso perché secondo me è più facile da capire.
Lezione n. 7: Trucchi di Machine Learning
Ci sono molti trucchi e tecniche utili o strumenti menzionati in questo corso. Ecco quelli che ho trovato utili.
Modello multi-target
Sorprendentemente, aggiungere un altro obiettivo alla Rete Neurale può aiutarti a migliorare la qualità del tuo modello.
Jeremy ha mostrato un esempio di un modello multi-target per la competizione di Classificazione delle Malattie del Riso. L’obiettivo di questa competizione è prevedere le malattie del riso attraverso le foto. Possiamo prevedere non solo la malattia, ma anche la varietà di riso, il che potrebbe aiutare il modello a imparare caratteristiche preziose. Le caratteristiche utili per prevedere la varietà di riso potrebbero essere utili anche per la rilevazione delle malattie.
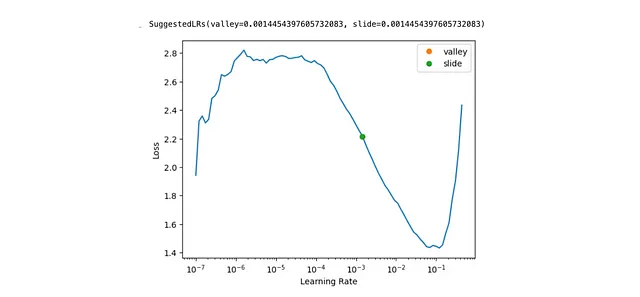
Trovare un tasso di apprendimento ottimale
Il tasso di apprendimento definisce la dimensione del passo per ogni iterazione di SGD (Stochastic Gradient Descent). Se il tasso di apprendimento è troppo piccolo, il modello si adatterà molto lentamente. Se è troppo alto, il modello potrebbe non convergere mai all’ottimo. Ecco perché è così importante scegliere il tasso di apprendimento corretto.
Fast.AI fornisce uno strumento che ti aiuta a farlo con una sola riga di codice learn.lr_find(suggest_funcs=(valley, slide)).
Test Time Augmentation
Le augmentations sono modifiche alle immagini (ad esempio, miglioramenti del contrasto, rotazioni o ritagli). Le augmentations vengono spesso utilizzate durante l’addestramento per ottenere immagini leggermente diverse ad ogni epoca. Ma possiamo utilizzare le augmentations anche durante la fase di inferenza. Questa tecnica si chiama Test Time Augmentation.

Funziona in modo molto semplice. Generiamo diverse versioni di ogni immagine utilizzando le augmentations e otteniamo le previsioni per ognuna di esse. Successivamente, calcoliamo il risultato aggregato utilizzando il massimo o la media. L’idea è simile al Bagging.
Arricchimento delle date
Puoi ottenere ulteriori informazioni dal tuo dataset se hai delle date nel tuo dataset. Ad esempio, invece di avere solo 2023–09–01, puoi considerare le caratteristiche separate: mese, giorno della settimana, anno, ecc.
Fast.AI ha una funzione add_datepart appositamente per questo, quindi non è necessario implementarla da soli.
Domanda senza risposta: Perché il sigmoid?
Durante il corso, ho avuto solo una domanda teorica che non è stata completamente trattata. Come in molti altri corsi di ML, non c’è spiegazione del motivo per cui utilizziamo la funzione sigmoid e non un’altra per convertire l’output del modello lineare in probabilità. Fortunatamente, c’è una lettura approfondita in cui puoi trovare tutte le risposte.
Per riassumere, il corso Fast.AI ha molti tesori nascosti che possono stimolare la tua riflessione anche se hai esperienza in data science. Quindi, ti consiglio sicuramente di ascoltarlo.
Grazie mille per aver letto questo articolo. Spero che sia stato illuminante per te. Se hai domande o commenti da fare, ti prego di lasciarli nella sezione dei commenti.