Questa ricerca sull’IA propone DISC-MedLLM una soluzione completa che sfrutta i grandi modelli di linguaggio (LLM) per fornire risposte mediche accurate.
This AI research proposes DISC-MedLLM, a comprehensive solution that leverages large language models (LLM) to provide accurate medical answers.


L’avvento della telemedicina ha cambiato il modo in cui viene fornita l’assistenza sanitaria, aprendo reti professionali, abbassando i prezzi e consentendo consulenze mediche a distanza. Inoltre, i sistemi medici intelligenti hanno migliorato i servizi medici online aggiungendo funzionalità come l’estrazione delle informazioni mediche, le raccomandazioni sui farmaci, la diagnosi automatizzata e le risposte alle domande sulla salute. Sebbene ci sia stato un progresso nella costruzione di sistemi sanitari intelligenti, le ricerche precedenti si sono concentrate su problemi o malattie specifiche con applicazioni limitate, creando un divario tra gli sviluppi sperimentali e l’uso reale. Per colmare questo divario, sono necessarie soluzioni complete per una vasta gamma di scenari medici e servizi sanitari conversazionali end-to-end di alta qualità per i consumatori.
I modelli di linguaggio di grandi dimensioni hanno recentemente dimostrato una sorprendente capacità di conversare in modo significativo e seguire le istruzioni degli esseri umani. Questi progressi hanno creato nuove opportunità per lo sviluppo di sistemi per la consulenza medica. Tuttavia, le circostanze che coinvolgono le consulenze mediche sono tipicamente complesse e al di fuori del campo di applicazione dei modelli di linguaggio di grandi dimensioni dell’area generale. La Figura 1 mostra un’illustrazione di una consulenza medica reale. Mostra due caratteristiche. In primo luogo, è necessaria una conoscenza medica approfondita e affidabile per comprendere la conversazione e rispondere in modo appropriato in ogni fase. I modelli di linguaggio di dominio generale forniscono output non correlati al caso specifico, esponendo importanti preoccupazioni di allucinazione.
In secondo luogo, spesso sono necessarie diverse sessioni di conversazione per ottenere sufficienti informazioni sul paziente per fornire consulenza sanitaria, e ogni sessione di conversazione ha un obiettivo definito. Tuttavia, i modelli di linguaggio di dominio ampio hanno spesso limitate capacità di interrogazione multi-turno sui dettagli dello stato di salute dell’utente e sono agenti single-turno. Sulla base di queste due constatazioni, i ricercatori dell’Università Fudan, dell’Università Politecnica del Nordovest e dell’Università di Toronto sostengono che i modelli di linguaggio medico dovrebbero codificare una conoscenza medica approfondita e affidabile, rispettando la distribuzione delle conversazioni mediche reali. Ispirati al successo di Instruction Tuning, investigano come costruire dataset di Supervised Fine-tuning di alta qualità per allenare i modelli di linguaggio medico e includere la conoscenza della medicina e i modelli di comportamento della consulenza.
- Come possono i robot prendere decisioni migliori? Ricercatori del MIT e di Stanford presentano Diffusion-CCSP per un ragionamento e pianificazione avanzati dei robot
- Rendere la vita più amichevole con i robot personali
- Adept AI Labs rende open-source Persimmon-8B un potente modello di linguaggio con licenza pienamente concessa
Nella pratica effettiva, creano campioni utilizzando tre diversi metodi:
• Lo sviluppo di campioni basati sulle conoscenze mediche del grafo. Seguendo una distribuzione delle query dei pazienti raccolta da un dataset di consulenze reali, selezionano triple di conoscenza da una rete di conoscenze mediche utilizzando un approccio orientato al dipartimento. GPT-3.5 viene utilizzato per creare in pochi passi coppie domanda-risposta per ogni tripla. Ne risultano 50.000 campioni.
• Ricostruzione del dialogo reale. Per migliorare i modelli di linguaggio, i record di consulenza raccolti da forum medici sono fonti adatte. Il linguaggio utilizzato in questi documenti è informale, la terminologia viene presentata in modo inconsistente e i diversi operatori sanitari hanno stili espressivi variabili. Di conseguenza, utilizzano GPT-3.5 per ricreare la discussione utilizzando casi reali. Ne risultano 420.000 campioni.
• Dopo la raccolta dei campioni, preferenza umana. Scelgono manualmente un gruppo limitato di voci dai record delle discussioni mediche reali che coprono vari contesti di consulenza e riscrivono alcuni esempi per allinearli all’intenzione umana. Garantiscono inoltre la qualità complessiva di ogni discussione dopo la ricostruzione guidata dall’uomo. Ne risultano 2.000 campioni. DISC-MedLLM viene quindi addestrato utilizzando i dataset SFT appena creati utilizzando un processo di addestramento a due fasi su un modello di linguaggio di dominio generale cinese con 13 miliardi di parametri. Valutano le prestazioni del modello da due angolazioni per determinarne la capacità di offrire consulenze sistematiche in discussioni multi-turno e risposte accurate in dialoghi single-turno.
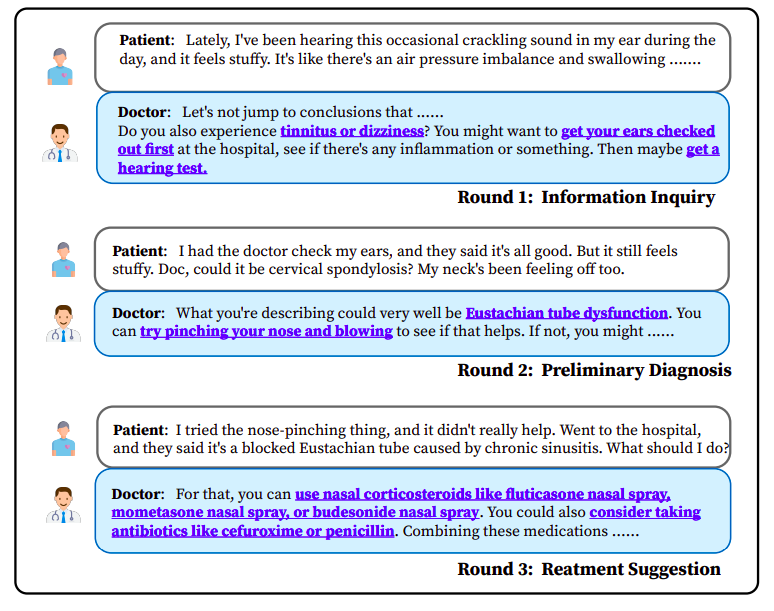
Costruiscono un benchmark di domande a scelta multipla raccolte da tre dataset medici pubblici e valutano l’accuratezza del modello utilizzando questo benchmark per una valutazione a singolo turno. Per una revisione a più turni, creano innanzitutto una piccola collezione di casi di consultazione eccellenti, utilizzando GPT-3.5 per simulare un paziente e dialogare con il modello. Valutano la proattività, l’accuratezza, l’utilità e la qualità linguistica del modello utilizzando GPT-4. I risultati sperimentali mostrano che, sebbene non raggiunga GPT-3.5, DISCMedLLM supera il HuatuoGPT medico su larga scala con parametri identici di oltre il 10% in media.
Inoltre, DISC-MedLLM si comporta meglio complessivamente in contesti di consultazione medica simulata rispetto a modelli di base come GPT-3.5, HuatuoGPT e BianQue. DISC-MedLLM supera altri LLM medici cinesi, in particolare nei casi che coinvolgono reparti medici e intenzioni dei pazienti.




