Introduzione agli algoritmi di ranking
Introduzione ranking algorithms
Scopri gli algoritmi principali di ranking per ordinare i risultati di ricerca

Introduzione
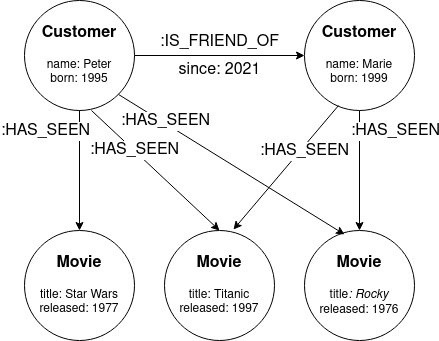
Learning to rank (LTR) è una classe di algoritmi di apprendimento automatico supervisionato che mirano a ordinare una lista di elementi in base alla loro rilevanza per una query. Nell’apprendimento automatico classico, in problemi come la classificazione e la regressione, l’obiettivo è prevedere un singolo valore basato su un vettore di caratteristiche. Gli algoritmi LTR operano su un insieme di vettori di caratteristiche e prevedono l’ordine ottimale degli elementi.
LTR ha molteplici applicazioni diverse. Ecco alcune di esse:
- Motori di ricerca. Un utente digita una query nella barra di ricerca del browser. Il motore di ricerca dovrebbe ordinare le pagine web in modo che i risultati più rilevanti appaiano nelle prime posizioni.
- Sistemi di raccomandazione. Un sistema di raccomandazione di film sceglie quale film raccomandare a un utente in base a una query di input.
Definiamo formalmente il problema del ranking:
- 3 errori silenziosi su Pandas di cui dovresti essere consapevole
- Semplificazione dei Transformers NLP all’avanguardia utilizzando parole comprensibili – parte 3 – Attenzione
- Trovare frammenti di dati in dati non strutturati
Dato un vettore di caratteristiche di n dimensioni che memorizza le informazioni su una query e un documento, l’obiettivo del ranking è trovare una funzione f che produce un numero reale che indica la rilevanza della query per il documento. Inoltre, se l’oggetto i viene classificato più in alto dell’oggetto j (i ▷ j), allora f(i) dovrebbe essere maggiore di f(j).
Nota. i ▷ j significa che il documento i viene classificato più in alto del documento j.
Dati
Vettori di caratteristiche
I vettori di caratteristiche sono composti da tre tipi di caratteristiche:
- Caratteristiche derivate solo da un documento (ad esempio, lunghezza del documento, numero di link in un documento).
- Caratteristiche derivate solo da una query (ad esempio, lunghezza della query, frequenza di una query).
- Caratteristiche derivate da una combinazione di un documento e una query (ad esempio, TF-IDF, BM25, BERT, numero di parole comuni in un documento e una query)
Dati di addestramento
Per addestrare un modello, abbiamo bisogno di dati di addestramento che verranno inseriti nel modello. Ci sono due approcci possibili in base a come vengono raccolti i dati di addestramento.
- LTR offline. I dati vengono annotati manualmente da un essere umano. L’essere umano valuta la rilevanza delle coppie (query, documento) per diverse query e documenti. Questo approccio è costoso e richiede tempo, ma fornisce annotazioni di alta qualità.
- LTR online. I dati vengono raccolti implicitamente dalle interazioni dell’utente con i risultati delle query (ad esempio, il numero di clic sugli elementi classificati, il tempo trascorso su una pagina web). In questo caso, è semplice ottenere dati di addestramento, ma le interazioni dell’utente non sono facilmente interpretabili.
Dopo di ciò, abbiamo vettori di caratteristiche e le relative etichette. Questo è tutto ciò di cui abbiamo bisogno per addestrare un modello. Il passo successivo è scegliere l’algoritmo di apprendimento automatico più adatto per un problema.
Tipi di ranking
Dal punto di vista generale, la maggior parte degli algoritmi LTR utilizza la discesa del gradiente stocastico per trovare il ranking più ottimale. A seconda di come un algoritmo sceglie e confronta i ranking degli elementi ad ogni iterazione, esistono tre metodi principali:
- Ranking punto a punto.
- Ranking a coppie.
- Ranking a lista.
Tutti questi metodi trasformano il compito del ranking in un problema di classificazione o regressione. Nelle sezioni seguenti, vedremo come operano nel dettaglio.
Ranking punto a punto
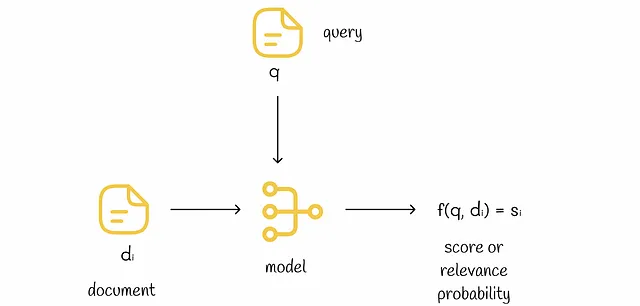
Nell’approccio punto a punto, i punteggi vengono previsti individualmente per ogni vettore di caratteristiche. Alla fine, i punteggi previsti vengono ordinati. Non importa che tipo di modello (albero decisionale, rete neurale, ecc.) viene utilizzato per la previsione.
Questo tipo di ranking trasforma il problema del ranking nel compito di regressione, in cui un modello di regressione cerca di prevedere la rilevanza corretta rispetto a una funzione di perdita scelta (ad esempio, MSE).
Un altro approccio valido è trasformare i ranking di verità fondamentale in rappresentazioni one-hot e alimentare questi dati al modello. In questo caso, è possibile utilizzare un modello di regressione o di classificazione (con perdita di entropia incrociata).
Nonostante il metodo sia molto semplice, presenta alcuni problemi elencati di seguito.
Sbilanciamento di classe
Un problema comune nell’utilizzo del metodo pointwise è lo sbilanciamento di classe. Se viene presa una query casuale nella vita reale, è molto probabile che solo una piccola parte di tutti i documenti nella collezione sia rilevante per essa. Pertanto, c’è uno squilibrio elevato tra documenti relativi e non relativi a una query nei dati di addestramento.
Anche se è possibile superare questo problema, c’è un problema molto più serio da considerare.
Metrica di ottimizzazione non valida
La classificazione pointwise ha un problema fondamentale con il suo obiettivo di ottimizzazione:
La classificazione pointwise ottimizza i punteggi dei documenti in modo indipendente e non tiene conto dei punteggi relativi tra documenti diversi. Pertanto, non ottimizza direttamente la qualità della classificazione.
Considera l’esempio seguente in cui un algoritmo pointwise ha effettuato previsioni per due insiemi di documenti. Supponiamo che la perdita MSE sia ottimizzata durante l’addestramento.
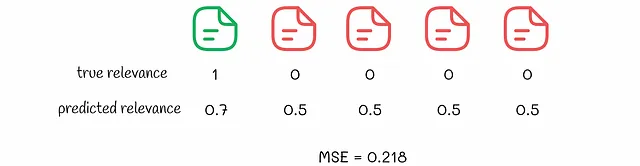
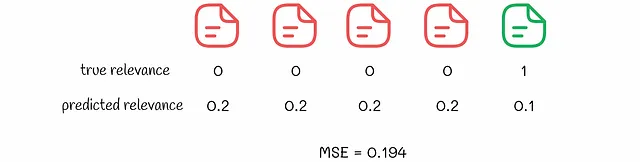
Dati due risultati di classificazione, possiamo vedere che dal punto di vista dell’algoritmo, il secondo risultato è migliore perché il valore MSE corrispondente è più basso. Tuttavia, scegliere il secondo risultato significa che all’utente verranno mostrati tutti i risultati non rilevanti per primi. A proposito, nel primo esempio, viene mostrato per primo il risultato rilevante, il che è molto migliore dal punto di vista dell’esperienza utente. Normalmente, un utente non presta molta attenzione a ciò che viene consigliato dopo.
Questo esempio mostra che nella vita reale ci preoccupiamo di mostrare risultati rilevanti per primi e dell’ordine relativo degli elementi. Con l’elaborazione indipendente dei documenti, il metodo pointwise non garantisce questi aspetti. Una perdita inferiore non equivale a una classificazione migliore.
Classificazione pairwise
I modelli pairwise lavorano con una coppia di documenti ad ogni iterazione. A seconda del formato di input, esistono due tipi di modelli pairwise.
Modelli con input di coppia
L’input per il modello sono due vettori di caratteristiche. L’output del modello è la probabilità che il primo documento sia classificato più in alto del secondo. Durante l’addestramento, queste probabilità vengono calcolate per diverse coppie di vettori di caratteristiche. I pesi del modello vengono regolati tramite discesa del gradiente in base ai ranghi veri.
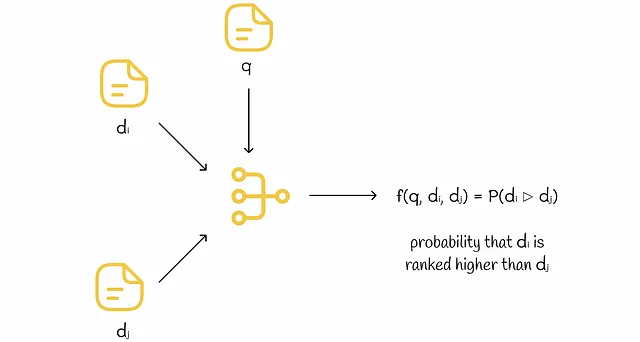
Questo metodo ha due svantaggi principali durante l’infereza:
- Per classificare n documenti per una determinata query durante l’infereza, ogni coppia di questi documenti deve essere elaborata dal modello per ottenere tutte le probabilità pairwise. Il numero totale di coppie è quadratico (esattamente uguale a n * (n — 1) / 2), il che è molto inefficiente.
- Anche avendo le probabilità pairwise di tutti i documenti, non è ovvio come classificarli definitivamente, specialmente in situazioni paradossali come i circoli viziosi in cui ci sono triplette di documenti (x, y, z) che sono classificati dal modello in un modo tale che: x ▷ y, y ▷ z e z ▷ x.
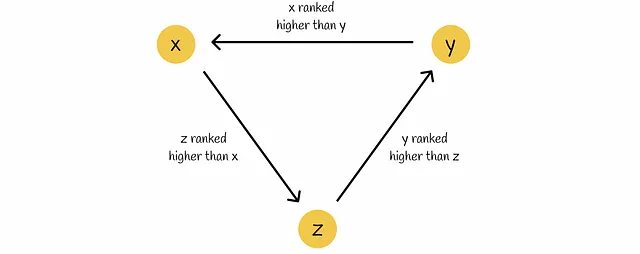
A causa di questi svantaggi, i modelli a input accoppiato sono raramente utilizzati nella pratica e i modelli a input singolo sono preferiti rispetto a essi.
Modelli a input singolo
Il modello accetta un singolo vettore di caratteristiche come input. Durante l’addestramento, ogni documento in una coppia viene alimentato indipendentemente nel modello per ricevere il proprio punteggio. Quindi entrambi i punteggi vengono confrontati e il modello viene regolato tramite discesa del gradiente basata sui rank veri.
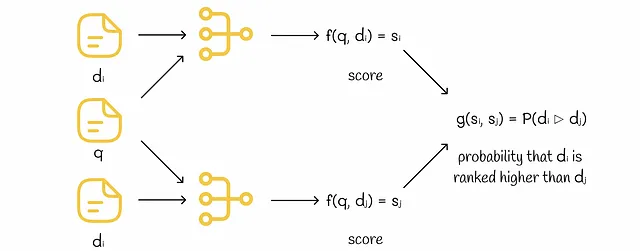
Durante l’inferenza, ogni documento riceve un punteggio passando al modello. I punteggi vengono quindi ordinati per ottenere la classifica finale.
Per coloro che sono familiari con le reti Siamese (FaceNet, SBERT, ecc.), i modelli a input singolo possono essere considerati reti Siamese.
Funzioni di perdita pairwise
Durante ogni iterazione di addestramento, il modello predice i punteggi per una coppia di documenti. Pertanto, la funzione di perdita dovrebbe essere pairwise e considerare i punteggi di entrambi i documenti.
In generale, la perdita pairwise prende come argomento z la differenza tra due punteggi s[i] – s[j] moltiplicata per una costante σ. A seconda dell’algoritmo, la funzione di perdita può assumere una delle seguenti forme:

A volte la differenza di punteggio z può essere moltiplicata per una costante.
RankNet è uno degli algoritmi di ranking pairwise più popolari. Esamineremo i dettagli della sua implementazione nella prossima sezione.
RankNet
Dopo aver ottenuto i punteggi per i documenti i e j, RankNet utilizza la funzione softmax per normalizzarli. In questo modo, RankNet ottiene la probabilità P[i][j] = P(i ▷ j) che il documento i sia classificato più in alto del documento j. Inversamente, possiamo calcolare la probabilità P̃[j][i] = P(j ▷ i) = 1 – P(i ▷ j). Per semplicità, supponiamo che nella realtà i sia classificato più in alto di j, quindi P̃[i][j] = 1 e P̃[j][i] = 0. Per l’aggiornamento dei pesi del modello, RankNet utilizza la perdita di cross-entropia che è semplificata nel seguente modo:
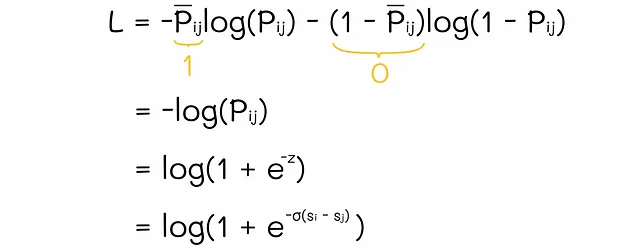
I pesi del modello vengono regolati tramite la discesa del gradiente. La prossima volta che il modello riceve la stessa coppia di documenti i e j, il documento i avrà probabilmente un punteggio più alto rispetto a prima e il documento j sarà probabilmente spinto verso il basso.
Fattorizzazione di RankNet
Per semplicità, non approfondiremo la matematica, ma c’è stato un interessante risultato di ricerca presentato nel paper originale in cui gli autori hanno trovato un modo per semplificare il processo di addestramento. Ciò viene fatto introducendo la variabile S[i][j] che assume uno dei tre valori possibili:

Dopo alcuni trucchi matematici, la derivata della perdita di cross-entropia si fattorizza come:
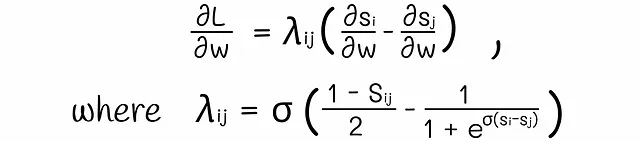
Il valore lambda nella formula è una costante che può essere calcolata relativamente velocemente per tutte le coppie di documenti. Prendendo valori positivi o negativi, queste lambda agiscono come forze che spingono i documenti verso l’alto o verso il basso.
Possiamo sommare tutte le lambda a coppie per un singolo documento i. Questa somma dà come risultato la forza totale applicata al documento i nella classifica.
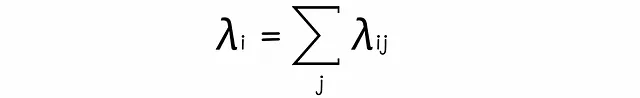
Lavorare direttamente con le lambda porta a un tempo di addestramento più veloce e a una migliore interpretazione dei risultati.
Anche se gli algoritmi a coppie funzionano meglio rispetto agli approcci punto a punto, hanno due svantaggi.
Probabilità non interpretabili
Le probabilità di output del modello mostrano solo quanto il modello sia sicuro che un certo oggetto i sia classificato più in alto dell’oggetto j. Tuttavia, queste probabilità non sono reali e talvolta possono essere approssimate dal modello, quindi non è una buona idea usarle sempre per l’interpretazione, specialmente in casi confusi con cerchi viziosi che abbiamo visto in precedenza.
La minimizzazione delle inversioni non è ottimale
Questo problema è molto più critico rispetto al precedente. Il problema fondamentale della maggior parte degli algoritmi a coppie e in particolare di RankNet è che minimizzano il numero di inversioni di classifica. Anche se potrebbe sembrare naturale ottimizzare il numero di inversioni, questo non è ciò che la maggior parte degli utenti finali desidera realmente. Considera il seguente esempio con due classifiche. Quale classifica è migliore, secondo te?


Anche se la seconda classifica ha meno inversioni, che è la priorità per l’algoritmo, un utente normale preferirebbe comunque la prima classifica perché c’è almeno un risultato rilevante in cima. Ciò significa che l’utente non deve scorrere molti documenti per trovare il primo risultato rilevante. Allo stesso modo, sarebbe meglio utilizzare metriche orientate all’utente come nDCG o ERR che mettono maggiore enfasi sui risultati in cima anziché sul numero di inversioni.
Come conseguenza, possiamo vedere che non tutte le coppie di documenti sono altrettanto importanti. L’algoritmo deve essere regolato in modo da attribuire molta più importanza all’ottenimento di una classifica corretta in cima piuttosto che in fondo.
Gli autori del paper presentano un esempio ben illustrato di come l’ottimizzazione della classifica con RankNet possa portare a risultati non ottimali:

Possiamo vedere che il documento in prima posizione è stato spostato al 4° e il documento al 15° al 10°, quindi il numero totale di inversioni è diminuito di 2. Tuttavia, dal punto di vista dell’esperienza dell’utente, la nuova classifica è peggiorata. Il problema principale risiede nel fatto che RankNet assegna gradienti più grandi ai documenti in posizioni peggiori. Tuttavia, per ottimizzare le metriche orientate all’utente, questo dovrebbe funzionare al contrario: i documenti in posizioni migliori dovrebbero essere spinti più in alto rispetto a quelli in posizioni peggiori. In questo modo, le metriche orientate all’utente come nDCG saranno più alte.
Classifica globale
Gli algoritmi di classifica globale ottimizzano esplicitamente le metriche di classifica. Per ottimizzare una certa metrica con la discesa del gradiente, è necessario calcolare la derivata per quella metrica. Purtroppo, la maggior parte delle metriche di classifica come nDCG o precision non sono continue e non differenziabili, quindi sono stati inventati altri avanzati tecniche.
A differenza dei metodi di classificazione punto per punto o a coppie, i metodi di classificazione per liste prendono in input un’intera lista di documenti contemporaneamente. A volte ciò comporta calcoli complessi ma garantisce una maggiore robustezza poiché l’algoritmo dispone di più informazioni ad ogni iterazione.
LambdaRank
A seconda dell’implementazione, LambdaRank può essere considerato un metodo a coppie o per liste.
Quando si considera l’nDCG, sembra ottimale assegnare gradienti più grandi alle coppie di documenti il cui scambio di posizione produce un nDCG più alto. Questa idea centrale è alla base di LambdaRank.
La “lambda” nel nome dell’algoritmo suggerisce che LambdaRank utilizza anche le lambda descritte in RankNet per l’ottimizzazione.
I ricercatori hanno ottenuto un risultato straordinario e hanno dimostrato che se il valore di perdita in RankNet viene moltiplicato per |nDCG|, allora l’algoritmo tende a ottimizzare direttamente l’nDCG! Detto questo, l’algoritmo LambdaRank è molto simile a RankNet ad eccezione del fatto che questa volta le lambda vengono moltiplicate per il cambiamento di nDCG:

Ciò che è incredibile anche della ricerca è il fatto che questo trucco funziona non solo per l’nDCG ma anche per altre metriche di recupero delle informazioni! Allo stesso modo, se le lambda vengono moltiplicate per il cambiamento di precisione, allora la precisione verrà ottimizzata.
Recentemente, è stato dimostrato teoricamente che LambdaRank ottimizza un limite inferiore su determinate metriche di recupero delle informazioni.
Altri metodi
Non discuteremo in dettaglio come funzionano gli altri metodi per liste, ma forniremo comunque l’idea principale dietro le implementazioni di due algoritmi onorevoli.
LambdaMart è un famoso approccio per liste che utilizza alberi di boosting dei gradienti con una funzione di perdita derivata da LambdaRank. In pratica, ha prestazioni migliori rispetto a LambdaRank.
SoftRank affronta il problema dell’esistenza delle derivate per l’nDCG. Crea una nuova metrica chiamata “SoftNDCG” che rappresenta e approssima in modo uniforme l’nDCG, rendendo possibile trovare una derivata corrispondente e aggiornare i pesi del modello tramite discesa del gradiente. In effetti, questo approccio può essere applicato allo stesso modo ad altre metriche.
Conclusioni
Abbiamo trattato la classificazione – un compito importante nell’apprendimento automatico per ordinare un insieme di oggetti nell’ordine rilevante. Gli approcci punto per punto e a coppie non vengono utilizzati così spesso, mentre i metodi per liste sono i più robusti. Ovviamente, abbiamo discusso solo una piccola parte degli algoritmi di classificazione, ma queste informazioni sono essenziali per comprendere tecniche più complesse come ListNet o ListMLE. Un elenco completo di algoritmi per liste può essere trovato qui.
Vale la pena notare che LambdaRank è attualmente uno degli algoritmi di classificazione più avanzati che offre molta flessibilità per l’ottimizzazione di una metrica specifica.
Se desideri trovare ulteriori informazioni sulle metriche di classificazione, ti consiglio vivamente di leggere il mio altro articolo su questo argomento.
Guida completa alle metriche di valutazione della classificazione
Esplora un’ampia scelta di metriche e trova quella migliore per il tuo problema
towardsdatascience.com
Risorse
- Da RankNet a LambdaRank a LambdaMART: una panoramica
- Apprendimento della classificazione utilizzando la discesa del gradiente
- Recupero delle informazioni | Apprendimento della classificazione | Harrie Oosterhuis
- Apprendimento della classificazione | Wikipedia
- SoftRank: Ottimizzazione di metriche di classificazione non lisce
Tutte le immagini, salvo diversa indicazione, sono dell’autore