Trovare gli aghi in un pagliaio – Indici di ricerca per la similarità di Jaccard
Indici di ricerca Jaccard - Trovare aghi in un pagliaio
Da concetti di base a indici esatti ed approssimati

I database vettoriali sono noti per essere la memoria esterna dei grandi modelli linguistici (LLM). I database vettoriali di oggi sono nuovi sistemi costruiti su una ricerca vecchia di decenni chiamata indici approssimati del vicino più prossimo (ANN). Questi algoritmi di indicizzazione prendono molti vettori ad alta dimensione (ad esempio, float32[]) e costruiscono una struttura dati che supporta la ricerca dei vicini approssimativi di un vettore di interrogazione nello spazio ad alta dimensione. È come se Google Map trovasse le case dei tuoi vicini dati la latitudine e la longitudine della tua casa, tranne che gli indici ANN operano in uno spazio molto più dimensionale.
Questo campo di ricerca ha una storia che risale a decenni fa. Alla fine degli anni ’90, i ricercatori di intelligenza artificiale creavano manualmente caratteristiche numeriche per dati multimediali come immagini e audio. La ricerca di similarità basata su questi vettori di caratteristiche è diventata un problema naturale. Per un po’, i ricercatori hanno affollato questa area. Questa bolla accademica è scoppiata quando un articolo fondamentale, Quando “Vicino più prossimo” è significativo?, ha fondamentalmente detto a tutti di smettere di perdere tempo perché il vicino più prossimo nello spazio ad alta dimensione delle caratteristiche create manualmente non è per lo più significativo – un argomento interessante per un altro post. Ancora oggi, continuo a vedere articoli di ricerca e benchmark di database vettoriali che pubblicano numeri di prestazione sul dataset SIFT-128, che consiste esattamente nei vettori di caratteristiche create manualmente con similarità insignificante.
Nonostante il rumore intorno alle caratteristiche create manualmente, c’è stata una linea di ricerca fruttuosa che si concentra su un tipo di dati ad alta dimensione con similarità significativa: insieme e Jaccard.
In questo post tratterò gli indici di ricerca per la similarità di Jaccard sugli insiemi. Inizierò con i concetti di base, per poi passare ad indici esatti ed approssimati.
- Un approccio semplice (ma efficace) per implementare i test unitari per i modelli dbt
- Come creare classifiche di paesi accattivanti utilizzando Python e Matplotlib
- Cinque modi per gestire spazi di azione ampi nell’apprendimento per rinforzo
Insieme e Jaccard
Un insieme è semplicemente una collezione di elementi distinti. Le canzoni che ti sono piaciute su Spotify sono un insieme; i tweet che hai retwittato la scorsa settimana sono un insieme; e i token distinti estratti da questo post del blog formano anche un insieme. L’insieme è un modo naturale per rappresentare punti dati in scenari applicativi come la raccomandazione musicale, le reti sociali e il rilevamento del plagio.
Diciamo che su Spotify seguo questi artisti:
[the weekend, taylor swift, wasia project]
e mia figlia segue questi artisti:
[the weekend, miley cyrus, sza]
Un modo ragionevole per misurare la similarità dei nostri gusti musicali è vedere quanti artisti seguiamo entrambi – la dimensione dell’intersezione. In questo caso seguiamo entrambi the weekend, quindi la dimensione dell’intersezione è 1.
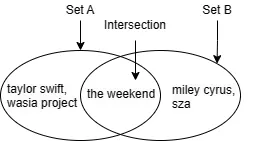
Tuttavia, puoi immaginare un altro paio di utenti che seguono ciascuno 100 artisti, e la dimensione dell’intersezione è sempre 1, ma la similarità tra i loro gusti dovrebbe essere molto più piccola rispetto alla similarità tra i gusti di mia figlia e i miei. Per rendere la misura comparabile tra diverse coppie di utenti, normalizziamo la dimensione dell’intersezione con la dimensione dell’unione. In questo modo, la similarità tra i gusti di mia figlia e i miei seguiti è 1 / 5 = 0.2, e la similarità tra i gusti dell’altro paio di utenti è 1 / 199 ~= 0.005. Questo è chiamato similarità di Jaccard.
Per un insieme A e un insieme B, la formula per la similarità di Jaccard è:
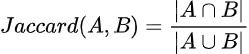
Perché il set è un tipo di dato ad alta dimensionalità? Un set può essere codificato come un vettore “one-hot”, le cui dimensioni mappano uno a uno tutti gli elementi possibili (ad esempio, tutti gli artisti su Spotify). Una dimensione in questo vettore ha un valore di 1 se il set contiene l’elemento corrispondente a questa dimensione, altrimenti ha un valore di 0. Quindi, il set vettorizzato dei miei artisti seguiti appare come segue:
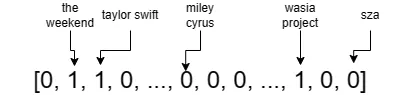
dove le seconde, terze e terze dimensioni dalla fine sono the weekend, taylor swift e wasia project. Ci sono oltre 10 milioni di artisti su Spotify, quindi un vettore come questo è estremamente ad alta dimensionalità e molto sparso – la maggior parte delle dimensioni sono 0.
Indici invertiti per la ricerca di Jaccard
Le persone vogliono trovare le cose rapidamente, quindi gli scienziati informatici hanno inventato strutture dati chiamate indici per rendere le prestazioni di ricerca soddisfacenti per le applicazioni software. In particolare, un indice di ricerca di Jaccard viene costruito su una collezione di set e, dato un set di query, restituisce k set che hanno il Jaccard più alto con il set di query.
L’indice di ricerca di Jaccard si basa su una struttura dati chiamata indice invertito. Un indice invertito ha un’interfaccia estremamente semplice: inserendo un elemento di un set, ad esempio the weekend, restituisce una lista di ID di set che contengono l’elemento di input, ad esempio [ 32, 231, 432, 1322, ...]. L’indice invertito è essenzialmente una tabella di ricerca le cui chiavi sono tutti gli elementi possibili del set e i valori sono liste di ID di set. In questo esempio, ogni lista nell’indice invertito rappresenta gli ID dei follower di un artista.
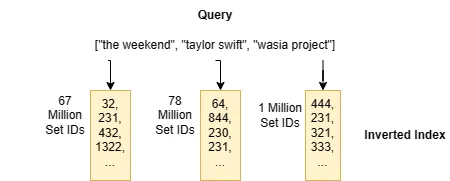

Puoi vedere il motivo per cui questo viene chiamato “indice invertito”: ti consente di passare da un elemento di un set per trovare i set che contengono l’elemento.
Algoritmo di ricerca esatto
L’indice invertito è una struttura dati incredibilmente potente per velocizzare la ricerca. Utilizzando l’indice invertito, anziché scorrere tutti i set e confrontare ciascuno con il set di query – molto costoso se hai milioni di set – è sufficiente elaborare gli ID dei set che condividono almeno un elemento con il set di query. È possibile ottenere gli ID dei set direttamente dalle liste dell’indice invertito.
Questa idea è implementata dall’algoritmo di ricerca seguente:
def search_top_k_merge_list(index, sets, q, k): """Ricerca dei primi k Jaccard utilizzando l'indice invertito. Args: index: un indice invertito, la chiave è l'elemento del set sets: una tabella di ricerca per i set, la chiave è l'ID del set q: un set di query k: parametro di ricerca k Returns: list: al massimo k ID di set. """ # Inizializza una tabella di ricerca vuota per i candidati. candidates = defaultdict(0) # Itera sugli elementi del set in q. for x in q: ids = index[x] # Ottieni una lista di ID di set dall'indice. for id in ids: candidates[id] += 1 # Incrementa il conteggio per la dimensione dell'intersezione. # Ora candidates[id] memorizza la dimensione dell'intersezione del set con ID id. # Una semplice routine per calcolare il Jaccard utilizzando la dimensione dell'intersezione e # le dimensioni dei set, basata sul principio di inclusione-esclusione. jaccard = lambda id: candidates[id] / (len(q) + len(sets(id) - candidates[id])) # Trova i candidati di top-k ordinati per Jaccard. return sorted(list(candidates.keys()), key=jaccard, reverse=True)[:k]In parole semplici, l’algoritmo attraversa ogni lista dell’indice invertito corrispondente agli elementi nell’insieme di query e utilizza una tabella dei candidati per tenere traccia del numero di volte in cui ogni ID dell’insieme appare. Se un ID dell’insieme appare n volte, l’insieme indicizzato ha n elementi in comune con l’insieme di query. Alla fine, l’algoritmo utilizza tutte le informazioni nella tabella dei candidati per calcolare le similarità di Jaccard e restituisce gli ID dei k insiemi più simili.
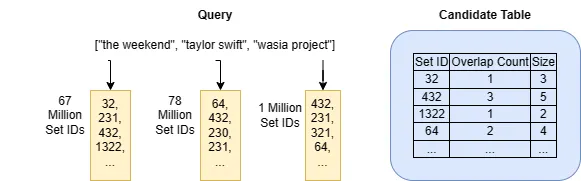
L’algoritmo search_top_k_merge_list può essere veloce quando: (1) il numero di elementi nell’insieme di query è piccolo e (2) il numero di ID nelle liste dell’indice invertito per gli elementi di query è piccolo. Nello scenario di Spotify, potrebbe essere il caso se la maggior parte delle persone segue alcuni artisti (probabilmente vero) e tutti gli artisti hanno più o meno lo stesso numero di follower (non vero). Sappiamo tutti che è un dato di fatto che alcuni artisti di punta sono seguiti dalla maggior parte delle persone e la maggior parte degli artisti ha pochi follower. Dopotutto, l’industria musicale segue la distribuzione di Pareto.
Taylor Swift ha 78 milioni di follower su Spotify e The Weekend ne ha 67 milioni. Averli nella mia lista di seguiti significa che l’algoritmo search_top_k_merge_list dovrà attraversare almeno 145 milioni di ID di insiemi e la tabella dei candidati candidates crescerà fino a questa dimensione astronomicamente grande. Nonostante il fatto che i computer di oggi siano veloci e potenti, sul mio computer Intel i7, la creazione di una tabella di questa dimensione richiede comunque almeno 30 secondi (in Python) e alloca dinamicamente 2,5 GB di memoria.
La maggior parte delle persone segue alcuni di questi artisti super famosi. Quindi, se utilizzi questo algoritmo nella tua applicazione di ricerca, otterrai sicuramente una bolletta di hosting cloud gigantesca per un grande utilizzo delle risorse e un’esperienza utente terribile per l’alta latenza di ricerca.
Ottimizzazione Branch and Bound
In modo intuitivo, l’algoritmo precedente search_top_k_merge_list elabora tutti i candidati potenziali in modo breadth-first perché utilizza solo l’indice invertito per calcolare l’intersezione. Questo algoritmo ha prestazioni scadenti a causa degli artisti super famosi con milioni di follower.
Un altro approccio consiste nel selezionare con maggiore attenzione i candidati potenziali. Immagina di intervistare candidati per un lavoro e di essere il responsabile delle assunzioni. Non puoi permetterti di intervistare tutti i potenziali candidati che ti inviano i CV, quindi classifichi i candidati in gruppi in base ai tuoi criteri di lavoro e inizi a intervistare i candidati che soddisfano principalmente i criteri che ti interessano di più. Mentre li intervisti uno per uno, valuti se ognuno di loro soddisfa effettivamente tutti o la maggior parte dei tuoi criteri e interrompi l’intervista quando trovi qualcuno.
Questo approccio funziona anche quando si tratta di trovare insiemi simili di artisti seguiti. L’idea è di partire dall’artista con il minor numero di follower nel tuo insieme di query. Perché? Semplicemente perché quegli artisti ti danno meno insiemi candidati con cui lavorare, in modo da poter elaborare meno liste di artisti dall’indice invertito e trovare più velocemente i tuoi migliori k candidati. Nella mia lista di seguiti di Spotify, wasian project ha solo 1 milione di follower, molto meno di taylor swift. Quelle persone molto meno numerose che seguono wasian project hanno la stessa potenziale probabilità di essere tra i migliori k candidati rispetto a quelle persone molto più numerose che seguono taylor swift.
L’idea chiave qui è che non vogliamo elaborare tutte le liste di potenziali candidati, ma fermarci quando abbiamo elaborato abbastanza. La parte complicata è sapere quando fermarsi. Di seguito è riportata una versione modificata dell’algoritmo precedente che implementa l’idea.
import heapqdef search_top_k_probe_set(index, sets, q, k): # Inizializza una coda prioritaria per memorizzare i candidati migliori correnti. heap = [] # Inizializza un insieme per tenere traccia dei candidati esplorati. seen_ids = set() # Itera sugli elementi in q dal meno al più frequente in base alle lunghezze delle loro liste nell'indice invertito. for i, x in enumerate(sorted(q, key=lambda x: len(index[x]))): ids = index[x] # Ottieni una lista di ID di insiemi dall'indice. for id in ids: if id in seen_ids: continue # Salta il candidato già esplorato. s = sets[id] intersect_size = len(q.intersection(s)) jaccard = intersect_size / (len(q) + len(s) - intersect_size) # Aggiungi il candidato alla coda prioritaria. if len(heap) < k: heapq.heappush(heap, (jaccard, id)) else: # Solo i candidati con un Jaccard maggiore del k-esimo # candidato corrente saranno aggiunti in questa operazione. heapq.heappushpop(heap, (jaccard, id)) seen_ids.add(id) # Se un nuovo candidato dalle liste rimanenti non può avere un Jaccard maggiore di quello dei migliori k candidati attuali, non è necessario fare altro lavoro. if (len(q) - i - 1) / len(q) (<= min(heap)[0]: break # Restituisci i migliori k candidati. return [id for _, id in heapq.nlargest(k, heap)]L’algoritmo search_top_k_probe_set calcola la similarità di Jaccard per ogni nuovo candidato trovato. Tieni traccia dei migliori attuali k candidati in ogni momento e si ferma quando il limite superiore di Jaccard di qualsiasi nuovo candidato non è maggiore della Jaccard minima dei migliori attuali k candidati.
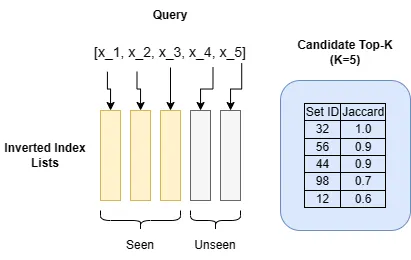
Come calcolare il limite superiore di Jaccard? Dopo l’elaborazione di n liste di candidati, per qualsiasi candidato non visto, la sua intersezione massima con l’insieme di query è al massimo uguale al numero di liste non elaborate rimanenti: |Q|-n. Diamo a tale candidato il massimo beneficio del dubbio, affermando che potrebbe apparire in ogni singola delle |Q|-n liste rimanenti. Ora possiamo usare semplice matematica per ottenere il limite superiore di Jaccard di tale candidato X.
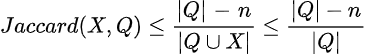
Questa tecnica intelligente è chiamata Filtro Prefisso nella letteratura di ricerca sulla similarità degli insiemi. Ho scritto un articolo al riguardo che approfondisce maggiormente i dettagli e le ottimizzazioni algoritmiche. Ho anche creato una libreria Python SetSimilaritySearch che implementa una versione molto più ottimizzata dell’algoritmo search_top_k_probe_set che supporta anche le misure di similarità coseno e contenimento.
Indice Approssimato per la Ricerca di Jaccard
Nella sezione precedente, ho spiegato due algoritmi di ricerca che lavorano su un indice invertito. Questi algoritmi sono esatti, il che significa che i k migliori candidati che restituiscono sono i veri k migliori candidati. Suona banale? Beh, questa è una domanda che dovremmo farci ogni volta che progettiamo algoritmi di ricerca su dati su larga scala, perché in molti scenari non è necessario ottenere i veri k migliori candidati.
Pensa di nuovo all’esempio di Spotify: ti interessa davvero se il risultato di una ricerca può perdere alcune persone con gusti simili ai tuoi? La maggior parte delle persone capisce che nelle applicazioni quotidiane (Google, Spotify, Twitter, ecc.), la ricerca non è mai esaustiva o esatta. Queste applicazioni non sono abbastanza critiche da giustificare una ricerca esatta. Ecco perché gli algoritmi di ricerca più ampiamente utilizzati sono tutti approssimati.
Ci sono principalmente due vantaggi nell’utilizzare algoritmi di ricerca approssimati:
- Più veloci. Puoi tagliare molti angoli se non hai più bisogno di risultati esatti.
- Consumo di risorse prevedibile. Questo è meno ovvio, ma per diversi algoritmi approssimati, il loro utilizzo delle risorse (ad esempio, la memoria) può essere configurato a priori indipendentemente dalla distribuzione dei dati.
In questo post, scrivo dell’indice approssimato più ampiamente utilizzato per Jaccard: Minwise Locality Sensitive Hashing (MinHash LSH).
Cosa è LSH?
Gli indici Locality Sensitive Hashing sono vere meraviglie nell’informatica. Sono magie algoritmiche alimentate dalla teoria dei numeri. Nella letteratura di apprendimento automatico, sono modelli k-NN, ma a differenza dei tipici modelli di apprendimento automatico, gli indici LSH sono agnostici rispetto ai dati, quindi la loro accuratezza condizionata alla similarità può essere determinata a priori prima di inglobare nuovi punti dati o cambiare la distribuzione dei dati. Quindi, sono più simili agli indici invertiti che a un modello.
Un indice LSH è essenzialmente un insieme di tabelle hash, ognuna con una diversa funzione di hash. Proprio come una tipica tabella hash, la funzione di hash di un indice LSH prende un punto dati (ad esempio, un insieme, un vettore di caratteristiche o un vettore di embedding) in input e restituisce una chiave di hash binaria. Tuttavia, a parte questo, possono essere molto diversi.
Una tipica funzione di hash restituisce chiavi che sono pseudo-casualmente e uniformemente distribuite su tutto lo spazio delle chiavi per qualsiasi dato di input. Ad esempio, MurmurHash è una nota funzione di hash che restituisce valori quasi uniformemente e casualmente distribuiti su uno spazio di chiavi a 32 bit. Ciò significa che per due input qualsiasi, come abcdefg e abcefg, purché siano diversi, le loro chiavi MurmurHash non dovrebbero essere correlate e dovrebbero avere la stessa probabilità di essere una qualsiasi delle chiavi nell’intero spazio delle chiavi a 32 bit. Questa è una proprietà desiderata di una funzione di hash, perché si desidera una distribuzione uniforme delle chiavi tra i bucket di hash per evitare concatenazioni o ridimensionamenti costanti della tabella hash.
La funzione di hash di un LSH fa qualcosa di opposto: per una coppia di input simili, con la similarità definita attraverso una misura dello spazio metrico, le loro chiavi di hash dovrebbero essere più probabili di essere uguali rispetto a un’altra coppia di chiavi di hash di input dissimili.
Cosa significa questo? Significa che una funzione di hash LSH ha una probabilità più alta di collisione delle chiavi di hash per punti dati che sono più simili. In pratica, stiamo utilizzando questa maggiore probabilità di collisione per il recupero basato sulla similarità.
MinHash LSH
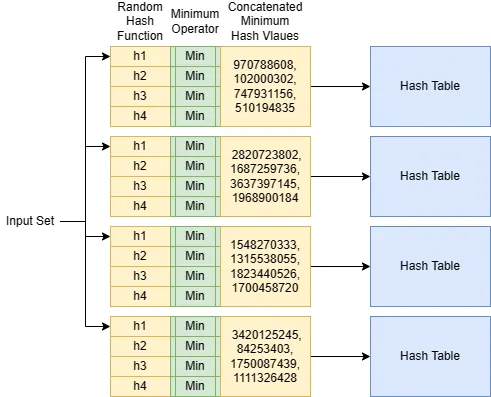
Per ogni metrica di similarità/distanza, esiste una funzione di hash LSH. Per Jaccard, la funzione si chiama Minwise Hash Function o funzione MinHash. Data un’insieme di input, una funzione MinHash consuma tutti gli elementi con una funzione di hash casuale e tiene traccia del valore di hash minimo osservato. È possibile costruire un indice LSH utilizzando una singola funzione MinHash. Vedere il diagramma qui sotto.

La teoria matematica alla base della funzione MinHash afferma che la probabilità che due insiemi abbiano lo stesso valore di hash minimo (cioè, collisione delle chiavi di hash) è la stessa del loro Jaccard.
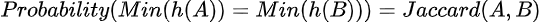
È un risultato magico, ma la dimostrazione è piuttosto semplice.
Un indice LSH MinHash con una singola funzione MinHash non fornisce una precisione soddisfacente perché la probabilità di collisione è linearmente proporzionale al Jaccard. Vedere il grafico seguente per capire il motivo.
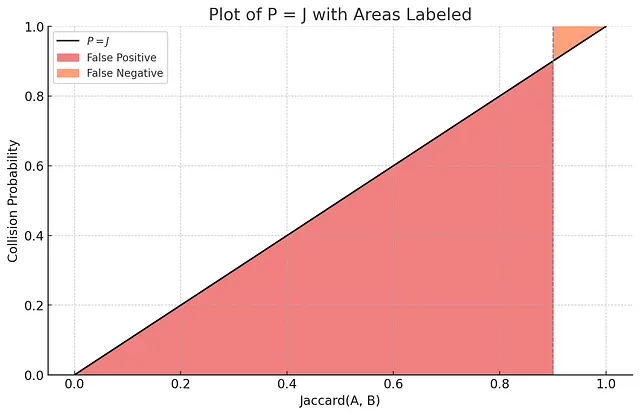
Immagina che tracciamo una soglia a Jaccard = 0,9: i risultati con un Jaccard superiore a 0,9 rispetto all’insieme di query sono rilevanti, mentre i risultati con un Jaccard inferiore a 0,9 sono irrilevanti. Nel contesto della ricerca, il concetto di “falso positivo” significa che vengono restituiti risultati irrilevanti, mentre il concetto di “falso negativo” significa che non vengono restituiti risultati rilevanti. Sulla base del grafico sopra e guardando l’area corrispondente al falso positivo: se l’indice utilizza solo una singola funzione MinHash, produrrà falsi positivi con una probabilità molto alta.
Aumentare l’accuratezza di MinHash LSH
Ecco perché abbiamo bisogno di un’altra magia LSH: un processo chiamato boosting. Possiamo potenziare l’indice in modo che sia molto più attento alla soglia di rilevanza specificata.
Invece di utilizzare solo una, utilizziamo m funzioni MinHash generate attraverso un processo chiamato Universal Hashing, ovvero m permutazioni casuali della stessa funzione hash di un intero a 32 o 64 bit. Per ogni insieme indicizzato, generiamo m valori hash minimi utilizzando l’hashing universale.
Immagina di elencare i m valori hash minimi per un insieme indicizzato. Raggruppiamo ogni r numero di valori hash in una banda di valori hash e creiamo b di tali bande. Ciò richiede m = b * r.

La probabilità che due insiemi abbiano una “collisione di banda” – tutti i valori hash in una banda collidono tra due insiemi, o r collisioni di hash contigue – è Jaccard(A, B)^r. Questa probabilità è molto più piccola di un singolo valore hash. Tuttavia, la probabilità di avere almeno una “collisione di banda” tra due insiemi è 1 - (1-Jaccard(A, B)^r)^b.
Perché ci interessa 1 - (1-Jaccard(A, B)^r)^b? Perché questa funzione ha una forma particolare:
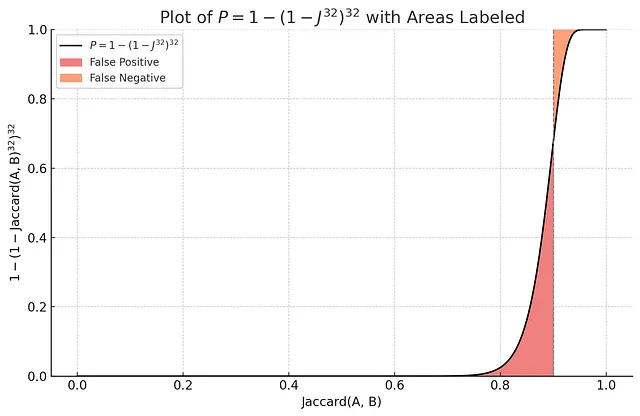
Nel grafico sopra, puoi vedere che utilizzando m funzioni MinHash, la probabilità di “almeno una collisione di banda” è una funzione a forma di S con un rapido aumento intorno a Jaccard = 0,9. Assumendo che la soglia di rilevanza sia 0,9, la probabilità di falsi positivi di questo indice è molto più piccola rispetto all’indice che utilizza solo una funzione hash casuale.
A causa di ciò, un indice LSH utilizza sempre b bande di r funzioni MinHash per aumentare l’accuratezza. Ogni banda è una tabella hash che memorizza puntatori a insiemi indicizzati. Durante la ricerca, viene restituito qualsiasi insieme indicizzato che collida con l’insieme di query su qualsiasi banda.
Per costruire un indice MinHash LSH, possiamo specificare una soglia di rilevanza precedente e probabilità accettabili di falsi positivi e negativi condizionate dalla similarità di Jaccard e calcolare il valore ottimale di m, b e r, prima di indicizzare qualsiasi punto dati. Questo è un grande vantaggio nell’utilizzare LSH rispetto ad altri indici approssimati.
Puoi trovare la mia implementazione di MinHash LSH nel pacchetto Python datasketch. Include anche altri algoritmi correlati a MinHash come LSH Forest e Weighted MinHash.
Considerazioni finali
In questo post ho affrontato molti argomenti, ma ho appena toccato la superficie degli indici di ricerca per la similarità di Jaccard. Se sei interessato a leggere di più su questi argomenti, ho una lista di letture ulteriori per te:
- Mining of Massive Datasets di Jure Leskovec, Anand Rajaraman e Jeff Ullman. Il terzo capitolo approfondisce MinHash e LSH. Penso che sia un ottimo capitolo per acquisire l’intuizione di MinHash. Tieni presente che l’applicazione descritta nel capitolo è incentrata sul confronto di testo basato su n-grammi.
- JOSIE: Overlap Set Similarity Search per trovare tabelle unibili in Data Lakes. La sezione preliminare di questo articolo spiega l’intuizione dietro gli algoritmi
search_top_k_merge_listesearch_top_k_probe_set. La sezione principale spiega come prendere in considerazione il costo quando gli insiemi di input sono grandi, come ad esempio una colonna di tabella. - Le librerie Datasketch e SetSimilaritySearch implementano rispettivamente gli indici di ricerca di similarità di Jaccard approssimativa e esatta all’avanguardia. La lista dei problemi del progetto datasketch è una miniera di scenari di applicazione e considerazioni pratiche nell’applicazione di MinHash LSH.
Cosa succede con gli Embeddings?
Negli ultimi anni, grazie alle scoperte nell’apprendimento delle rappresentazioni utilizzando reti neurali profonde come i Transformers, la similarità tra i vettori di embedding appresi ha un significato quando i dati di input fanno parte dello stesso dominio in cui è stato addestrato il modello di embedding. Le principali differenze tra questo scenario e lo scenario di ricerca descritto in questo post sono:
- I vettori di embedding sono vettori densi con tipicamente da 60 a 700 dimensioni. Ogni dimensione è diversa da zero. Al contrario, gli insiemi, quando rappresentati come vettori one-hot, sono sparsi: da 10k a milioni di dimensioni, ma la maggior parte delle dimensioni è zero.
- La similarità del coseno (o prodotto scalare su vettori normalizzati) viene tipicamente utilizzata per i vettori di embedding. Per gli insiemi utilizziamo la similarità di Jaccard.
- È difficile specificare una soglia di rilevanza sulla similarità tra i vettori di embedding, perché i vettori sono rappresentazioni “black-box” apprese dei dati originali come immagini o testo. D’altra parte, la soglia di similarità di Jaccard per gli insiemi è molto più facile da specificare perché gli insiemi sono i dati originali.
A causa delle differenze sopra indicate, non è immediato confrontare gli embedding e gli insiemi perché sono tipi di dati distinti, anche se entrambi possono essere classificati come ad alta dimensionalità. Sono adatti a scenari di applicazione diversi.






