Hollywood a casa DragNUWA è un modello di intelligenza artificiale in grado di realizzare la generazione di video controllabile
Il modello DragNUWA è un'intelligenza artificiale che genera video controllabili, portando Hollywood a casa tua.


L’IA generativa ha compiuto un enorme balzo negli ultimi due anni grazie al rilascio di modelli di diffusione su larga scala. Questi modelli sono un tipo di modello generativo che può essere utilizzato per generare immagini realistiche, testo e altri dati.
I modelli di diffusione funzionano partendo da un’immagine o un testo di rumore casuale e aggiungendo gradualmente dettagli nel tempo. Questo processo è chiamato diffusione ed è simile a come un oggetto del mondo reale diventa gradualmente più dettagliato durante la sua formazione. Di solito vengono addestrati su un grande dataset di immagini o testi reali.
D’altra parte, la generazione di video ha anche registrato notevoli progressi negli ultimi anni. Comprende la possibilità entusiasmante di generare contenuti video realistici e dinamici. Questa tecnologia sfrutta l’apprendimento profondo e i modelli generativi per generare video che vanno da paesaggi onirici surreali a simulazioni realistiche del nostro mondo.
- Nuovo metodo sviluppato da ricercatori di Microsoft e MIT spera di ridurre le allucinazioni dell’IA
- Amazon si spinge ancora di più nell’IA con un investimento di 4 miliardi di dollari in Anthropic
- Come diventare un data scientist dopo la laurea in economia?
La capacità di utilizzare la potenza dell’apprendimento profondo per generare video con un controllo preciso sul loro contenuto, disposizione spaziale ed evoluzione temporale offre grandi promesse per una vasta gamma di applicazioni, dall’intrattenimento all’istruzione e oltre.
Storicamente, la ricerca in questo ambito si è concentrata principalmente su segnali visivi, facendo affidamento pesantemente sulle immagini del frame iniziale per guidare la generazione successiva del video. Tuttavia, questo approccio aveva i suoi limiti, in particolare nella previsione delle complesse dinamiche temporali dei video, compresi i movimenti della telecamera e le intricate traiettorie degli oggetti. Per superare queste sfide, la ricerca recente si è spostata verso l’incorporazione di descrizioni testuali e dati sulle traiettorie come meccanismi di controllo aggiuntivi. Sebbene questi approcci abbiano rappresentato passi significativi, hanno anche i loro vincoli.
Incontriamo quindi DragNUWA che affronta queste limitazioni.
DragNUWA è un modello di generazione video consapevole delle traiettorie con controllo dettagliato. Integra senza soluzione di continuità informazioni testuali, immagini e traiettorie per fornire un controllo forte e user-friendly.

DragNUWA ha una formula semplice per generare video dall’aspetto realistico. I tre pilastri di questa formula sono il controllo semantico, spaziale e temporale. Questi controlli vengono effettuati rispettivamente tramite descrizioni testuali, immagini e traiettorie.
Il controllo testuale viene effettuato sotto forma di descrizioni testuali. Questo inietta significato e semantica nella generazione del video. Consente al modello di comprendere ed esprimere l’intento dietro un video. Ad esempio, può fare la differenza tra rappresentare un pesce che nuota nel mondo reale e un dipinto di un pesce.
Per il controllo visivo vengono utilizzate le immagini. Le immagini forniscono contesto e dettagli spaziali, aiutando a rappresentare accuratamente oggetti e scene nel video. Servono come un complemento cruciale alle descrizioni testuali, aggiungendo profondità e chiarezza ai contenuti generati.
Tutte queste cose ci sono familiari, e la vera differenza che DragNUWA apporta si può vedere nell’ultimo componente: il controllo delle traiettorie. DragNUWA utilizza un controllo delle traiettorie a dominio aperto. Mentre i modelli precedenti hanno avuto difficoltà con la complessità delle traiettorie, DragNUWA utilizza un campionatore di traiettorie (TS), una fusione multiscale (MF) e un addestramento adattivo (AT) per affrontare questa sfida in modo deciso. Questa innovazione consente la generazione di video con intricate traiettorie a dominio aperto, movimenti realistici della telecamera e interazioni complesse degli oggetti.
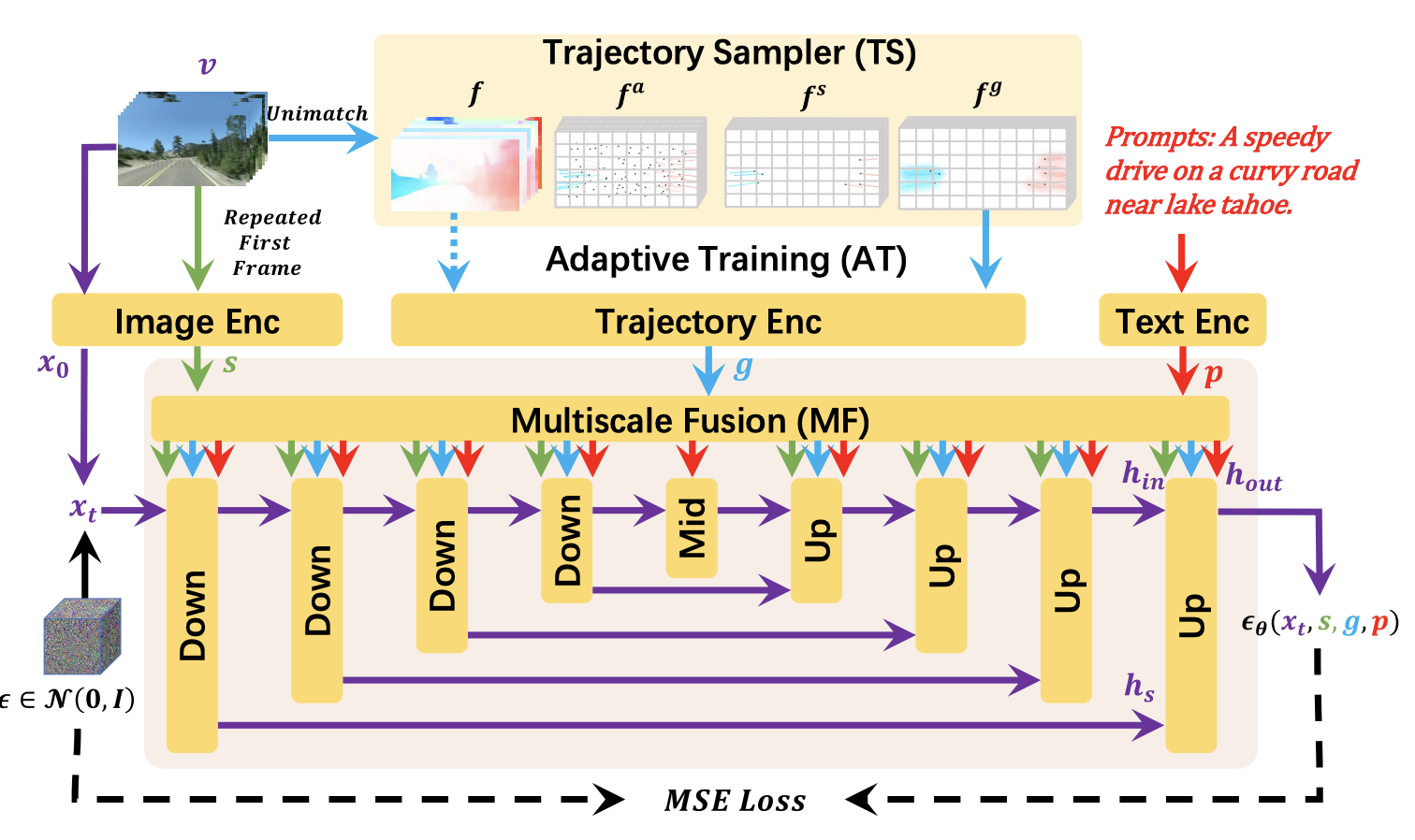
DragNUWA offre una soluzione completa che unifica tre meccanismi di controllo essenziali – testo, immagini e traiettoria. Questa integrazione offre agli utenti un controllo preciso e intuitivo sui contenuti video. Rivoluziona il controllo delle traiettorie nella generazione di video. Le sue strategie TS, MF e AT consentono il controllo a dominio aperto di traiettorie arbitrarie, rendendolo adatto a scenari video complessi e diversi.





