Come adattare grandi modelli di linguaggio in memoria ridotta quantizzazione
Come adattare grandi modelli di linguaggio in memoria ridotta.
I Modelli di Lingua di grandi dimensioni possono essere utilizzati per la generazione di testo, la traduzione, le domande e risposte, ecc. Tuttavia, i MGL sono anche molto grandi (ovviamente, modelli di lingua di grandi dimensioni) e richiedono molta memoria. Ciò può renderli problematici per dispositivi di piccole dimensioni come telefoni cellulari e tablet.
Moltiplica i parametri per la dimensione di precisione scelta per determinare la dimensione del modello in byte. Supponiamo che la precisione scelta sia float16 (16 bit = 2 byte). Supponiamo che vogliamo utilizzare il modello BLOOM-176B. Abbiamo bisogno di 176 miliardi di parametri * 2 byte = 352 GB per caricare il modello!
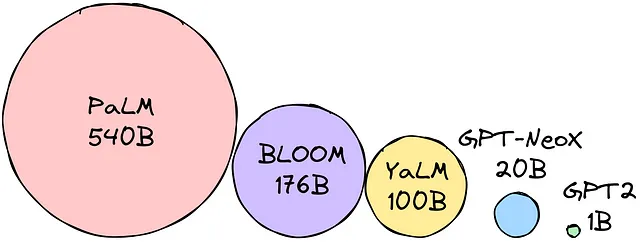
In altre parole, per caricare tutti i pesi dei parametri, abbiamo bisogno di 12(!) macchine da 32 GB! Questo è troppo se vogliamo rendere i MGL portatili. Sono state sviluppate tecniche per ridurre l’impronta di memoria dei MGL per superare questa difficoltà. Le tecniche più popolari sono:
- Quantizzazione consiste nella conversione dei pesi dei MGL in un formato a precisione inferiore, riducendo la memoria necessaria per memorizzarli.
- Knowledge distillation consiste nell’addestramento di un MGL più piccolo per imitare il comportamento di un MGL più grande. Ciò può essere fatto trasferendo le conoscenze dal MGL più grande a quello più piccolo.
Queste tecniche hanno reso possibile adattare i MGL in piccole dimensioni di memoria. Ciò ha aperto nuove possibilità per l’uso dei MGL su vari dispositivi. Oggi parleremo di quantizzazione (rimanete sintonizzati per la distillazione delle conoscenze).
- Sei passaggi verso la sicurezza dell’IA
- Utilizzare SQL per comprendere le tendenze della carriera della scienza dei dati
- Generazione di AI testo-musica Audio di stabilità, MusicLM di Google e altro
Quantizzazione
Iniziamo con un semplice esempio. Dovremo trasformare 2023 in binario:
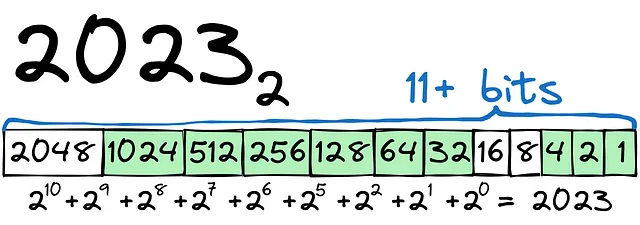
Come si può vedere, il processo è relativamente semplice. Per memorizzare il numero 2023, avremo bisogno di 12+ bit (1 bit per il segno + o -). Per il numero, potremmo usare il tipo int16.
C’è una grande differenza tra la memorizzazione di int come binario e float come tale. Proviamo a convertire 20.23 in binario:
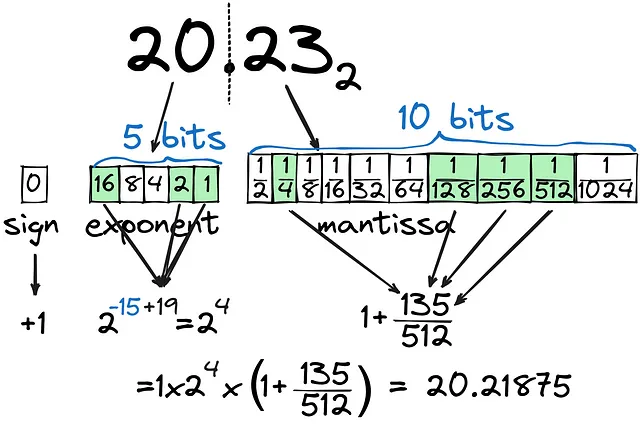
Come si può vedere, la parte decimale (mantissa) viene calcolata come la combinazione di 1/2^n e non può essere calcolata con molta precisione, anche con 10 bit dedicati alla parte decimale. La parte intera del numero (esponente) è impostata su 5 bit, coprendo tutti i numeri fino a 32. In totale, stiamo utilizzando 16 bit (FP16) per memorizzare il valore più vicino possibile a 20.23, ma è il modo più efficace per conservare i float? Cosa succede se la parte intera del numero è molto più grande, ad esempio 202.3?
Se guardiamo i tipi di float standard, noteremo che per memorizzare 202.3 dovremo usare FP32, che, dal punto di vista computazionale, è tutto tranne che ragionevole. Invece, possiamo utilizzare un bfloat16 per salvare l’intervallo (esponente) come 8 bit e 7 bit per la precisione (mantissa). Ciò ci consente di ampliare la gamma di decimali possibili senza perdere molta precisione.
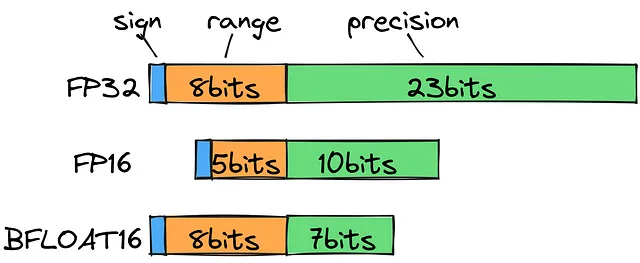
Per essere chiari, durante l’addestramento è necessaria tutta la precisione che possiamo ottenere. Ma dare priorità alla velocità e alla dimensione oltre alla sesta cifra decimale ha senso per l’elaborazione.
Possiamo ridurre l’utilizzo di memoria da bfloat16 a, ad esempio, int8?
Punto zero e quantizzazione abs-max
In realtà possiamo farlo, e ci sono diversi approcci per tale quantizzazione:
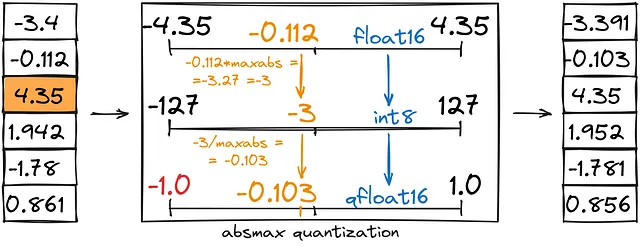
- La quantizzazione del punto zero salva la metà della memoria convertendo un intervallo fisso (-1, 1) in int8 (-127, 127), seguito dalla conversione di int8 in bfloat16.
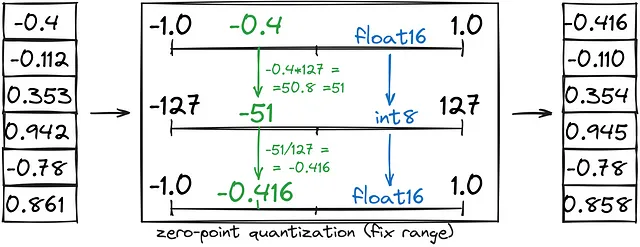
- La quantizzazione di abs-max è simile a quella del punto zero, ma invece di impostare un intervallo personalizzato (-1,1), lo impostiamo come (-abs(max), abs(max)).
Diamo un’occhiata a come queste pratiche vengono utilizzate in un esempio di moltiplicazione di matrici:
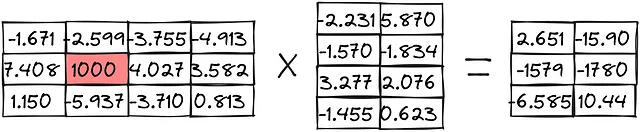
Quantizzazione del punto zero:

Quantizzazione di abs-max:
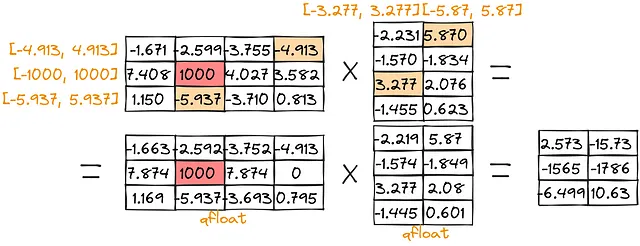
Come si può notare, il punteggio per valori grandi [-1579, -1780] è piuttosto basso ([-1579, -1752] per il punto zero e [-1565,-1786] per abs-max). Per superare tali problemi, possiamo separare la moltiplicazione degli outlier:

Come puoi vedere, i risultati sono molto più vicini ai valori reali.
Ma c’è un modo per utilizzare ancora meno spazio senza perdere molta qualità?
Molto sorprendentemente, c’è un modo! E se invece di convertire indipendentemente ogni numero in un tipo inferiore, tenessimo conto dell’errore e lo usassimo per gli aggiustamenti? Questa tecnica si chiama GPTQ.
Come per la quantizzazione precedente, troviamo la corrispondenza più vicina per le cifre decimali, mantenendo l’errore di conversione totale il più vicino possibile allo zero.
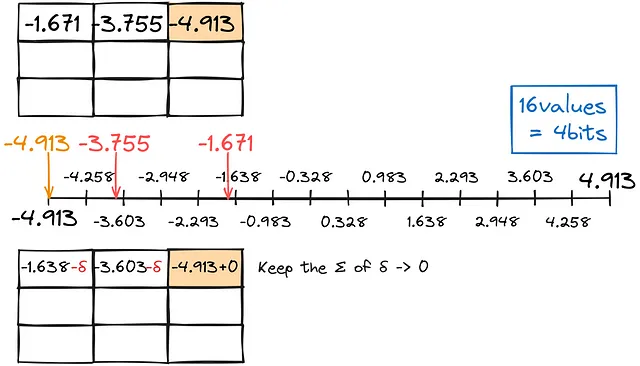
Riempiremo la matrice per righe in questo modo.
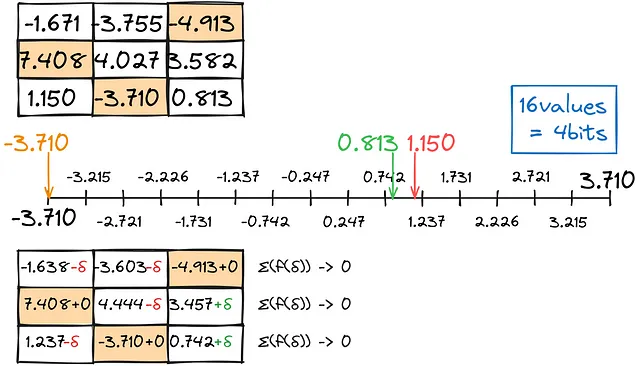
Il risultato, combinato con calcoli separati per le anomalie, fornisce risultati abbastanza buoni:
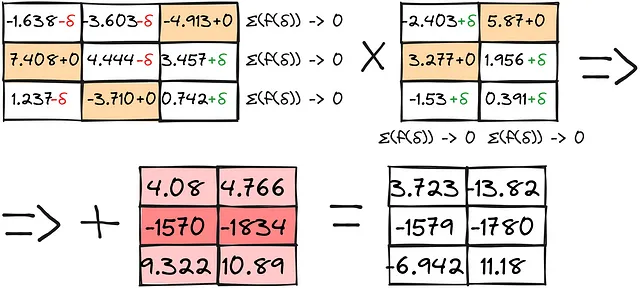
Ora possiamo confrontare tutti i metodi:

I metodi LLM.int8() funzionano molto bene! L’approccio GPTQ perde qualità ma consente di utilizzare il doppio della memoria GPU rispetto al metodo int8.
Nel codice, potresti trovare qualcosa di simile a quanto segue:
from transformers import BitsAndBytesConfig# Configura BitsAndBytesConfig per una quantizzazione a 4 bitbnb_config = BitsAndBytesConfig( load_in_4bit=True, bnb_4bit_use_double_quant=True, bnb_4bit_quant_type="nf4", bnb_4bit_compute_dtype=torch.bfloat16,)# Carica il modello nella configurazione predefinitapretrained_model = AutoModelForCausalLM.from_pretrained( model_id, quantization_config=bnb_config,)Il flag load_in_4bit specifica che il modello deve essere caricato con una precisione a 4 bit. Il flag bnb_4bit_use_double_quant specifica che deve essere utilizzata la doppia quantizzazione. Il flag bnb_4bit_quant_type specifica il tipo di quantizzazione. Il flag bnb_4bit_compute_dtype specifica il dtype di calcolo.
In sintesi, abbiamo imparato come vengono memorizzati i decimali in memoria, come ridurre l’occupazione di memoria con una certa perdita di precisione e come eseguire modelli selezionati con una quantizzazione a 4 bit.

L’articolo originale è stato pubblicato sulla mia pagina LinkedIn.






