Utilizzare SQL per comprendere le tendenze della carriera della scienza dei dati
Usare SQL per capire le tendenze nella carriera della scienza dei dati

In un mondo in cui i dati sono il nuovo petrolio, capire le sfumature di una carriera in data science è più importante che mai. Che tu sia un appassionato di dati in cerca di opportunità o un veterano che esplora le possibilità, l’utilizzo di SQL può offrire un’analisi del mercato del lavoro in data science.
Spero che tu sia desideroso di sapere quali sono i titoli di lavoro in data science più attraenti, o quali offrono i salari più alti. O forse ti chiedi come i livelli di esperienza si legano ai salari medi in data science?
In questo articolo, abbiamo coperto tutte queste domande (e altre) mentre approfondiamo il mercato del lavoro in data science. Cominciamo!
- Generazione di AI testo-musica Audio di stabilità, MusicLM di Google e altro
- Una guida passo passo per rilevare in modo accurato picchi e valli.
- Pettegolezzi sulla crittografia Parte 1 e 2
Tendenza salariale del dataset
Il dataset che utilizzeremo in questo articolo è progettato per chiarire i modelli salariali nel campo della data science dal 2021 al 2023. Mettendo in luce elementi come la storia professionale, le posizioni lavorative e le sedi aziendali, offre informazioni cruciali sulla dispersione dei salari nel settore.
In questo articolo troverai una risposta alle seguenti domande:
- Come appare il salario medio in base ai diversi livelli di esperienza?
- Quali sono i titoli di lavoro più comuni in data science?
- Come varia la distribuzione dei salari in base alle dimensioni dell’azienda?
- Dove si trovano principalmente i lavori in data science dal punto di vista geografico?
- Quali titoli di lavoro offrono i salari più alti in data science?
Puoi scaricare questi dati da Kaggle.
1. Come appare il salario medio in base ai diversi livelli di esperienza?
In questa query SQL, stiamo cercando il salario medio per diversi livelli di esperienza. La clausola GROUP BY raggruppa i dati per livello di esperienza e la funzione AVG calcola il salario medio per ogni gruppo.
Questo aiuta a comprendere come l’esperienza nel campo influisce sul potenziale di guadagno, che è essenziale per pianificare il tuo percorso di carriera in data science. Vediamo il codice.
SELECT experience_level, AVG(salary_in_usd) AS avg_salary
FROM salary_data
GROUP BY experience_level;
Ora visualizziamo questo risultato utilizzando Python.
Ecco il codice.
# Importa le librerie necessarie per il tracciamento dei grafici
import matplotlib.pyplot as plt
import seaborn as sns
# Imposta lo stile per i grafici
sns.set(style="whitegrid")
# Inizializza la lista per memorizzare i grafici
graphs = []
plt.figure(figsize=(10, 6))
sns.barplot(x='experience_level', y='salary_in_usd', data=df, estimator=lambda x: sum(x) / len(x))
plt.title('Salario medio per livello di esperienza')
plt.xlabel('Livello di esperienza')
plt.ylabel('Salario medio (USD)')
plt.xticks(rotation=45)
graphs.append(plt.gcf())
plt.show()
Ora confrontiamo i salari per i livelli di ingresso ed esperti e per i livelli intermedi e senior.
Cominciamo con i livelli di ingresso ed esperti. Ecco il codice.
# Filtra i dati per i livelli di ingresso ed esperti
entry_experienced = df[df['experience_level'].isin(['Entry_Level', 'Experienced'])]
# Filtra i dati per i livelli intermedi e senior
mid_senior = df[df['experience_level'].isin(['Mid-Level', 'Senior'])]
# Tracciamento del grafico Entry_Level vs Experienced
plt.figure(figsize=(10, 6))
sns.barplot(x='experience_level', y='salary_in_usd', data=entry_experienced, estimator=lambda x: sum(x) / len(x) if len(x) != 0 else 0)
plt.title('Salario medio: Entry_Level vs Experienced')
plt.xlabel('Livello di esperienza')
plt.ylabel('Salario medio (USD)')
plt.xticks(rotation=45)
graphs.append(plt.gcf())
plt.show()
Ecco il grafico.
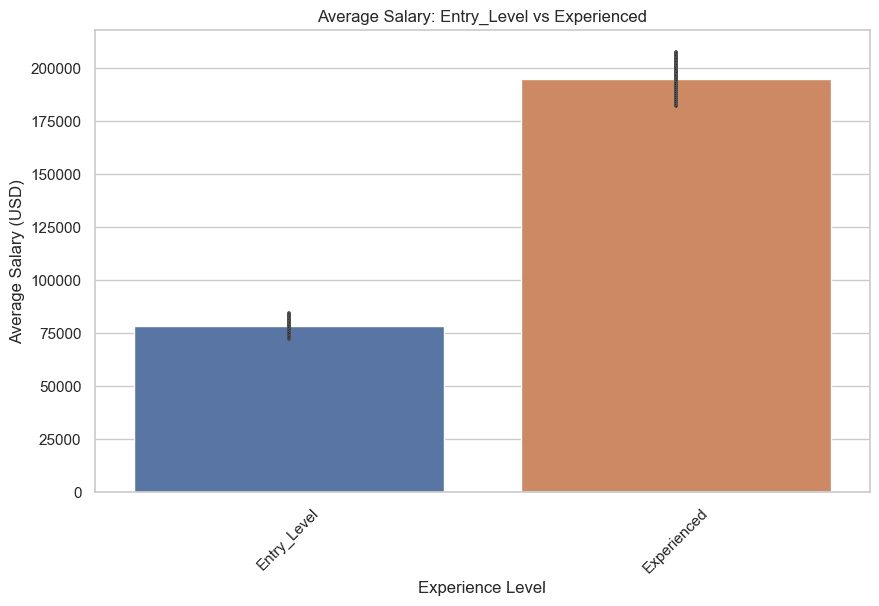
Ora disegniamo i salari per i livelli intermedi e senior. Ecco il codice.
# Tracciamento del grafico Mid-Level vs Senior
plt.figure(figsize=(10, 6))
sns.barplot(x='experience_level', y='salary_in_usd', data=mid_senior, estimator=lambda x: sum(x) / len(x) if len(x) != 0 else 0)
plt.title('Salario medio: Mid-Level vs Senior')
plt.xlabel('Livello di esperienza')
plt.ylabel('Salario medio (USD)')
plt.xticks(rotation=45)
graphs.append(plt.gcf())
plt.show() 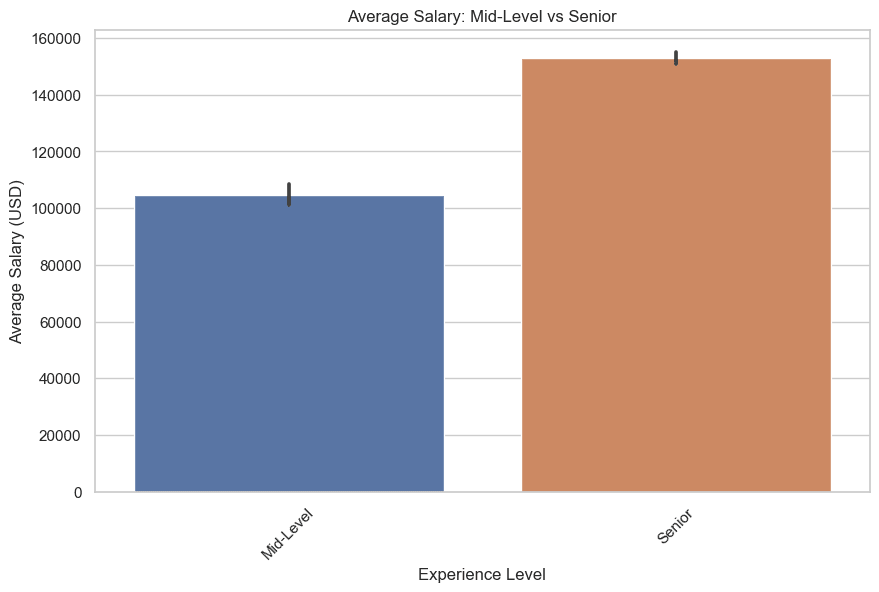
2. Quali sono i Titoli di Lavoro più Comuni nel Data Science?
Qui, estraiamo i primi 10 titoli di lavoro più comuni nel data science. La funzione COUNT conta il numero di occorrenze di ogni titolo di lavoro e i risultati sono ordinati in ordine decrescente per ottenere i titoli più comuni in cima.
Questa informazione ti dà un’idea della domanda del mercato del lavoro, guidandoti nell’individuazione dei ruoli potenziali che puoi puntare. Vediamo il codice.
SELECT job_title, COUNT(*) AS job_count
FROM salary_data
GROUP BY job_title
ORDER BY job_count DESC
LIMIT 10;
Ok, è ora di visualizzare questa query utilizzando Python.
Ecco il codice.
plt.figure(figsize=(12, 8))
sns.countplot(y='job_title', data=df, order=df['job_title'].value_counts().index[:10])
plt.title('Titoli di Lavoro più Comuni nel Data Science')
plt.xlabel('Conteggio Lavori')
plt.ylabel('Titolo di Lavoro')
graphs.append(plt.gcf())
plt.show()
Vediamo il grafico.
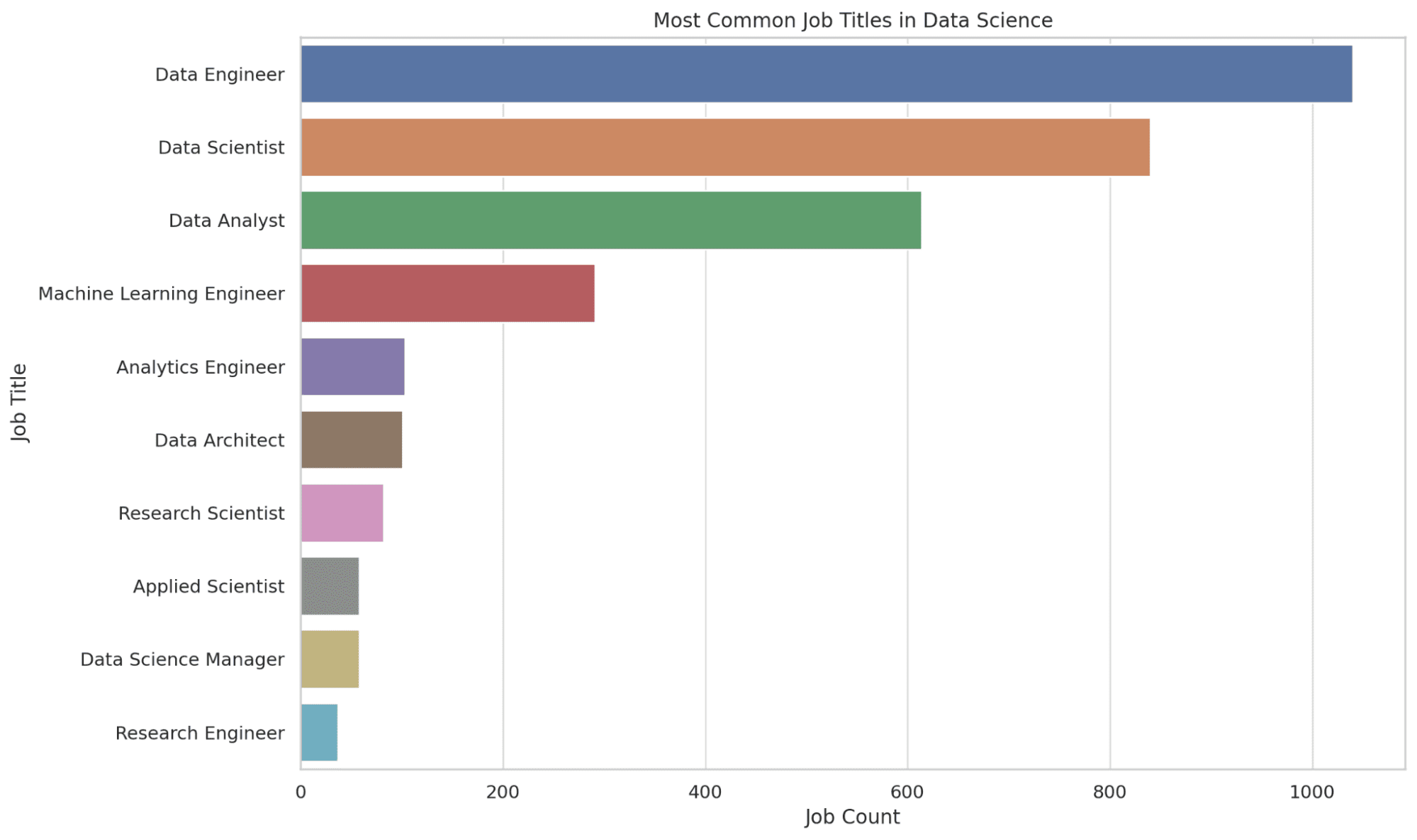
3. Come Varia la Distribuzione degli Stipendi in Base alla Dimensione dell’Azienda?
In questa query, estraiamo la media, il minimo e il massimo degli stipendi per ogni dimensione dell’azienda. Utilizzare funzioni di aggregazione come AVG, MIN e MAX aiuta a fornire una visione completa del panorama degli stipendi in relazione alla dimensione di un’azienda.
Questi dati sono essenziali perché ti aiutano a capire le potenziali entrate che puoi aspettarti a seconda della dimensione dell’azienda a cui stai cercando di unirti, vediamo il codice.
SELECT company_size, AVG(salary_in_usd) AS avg_salary, MIN(salary_in_usd) AS min_salary, MAX(salary_in_usd) AS max_salary
FROM salary_data
GROUP BY company_size;
Ora visualizziamo questa query utilizzando Python.
Ecco il codice.
plt.figure(figsize=(12, 8))
sns.barplot(x='company_size', y='salary_in_usd', data=df, estimator=lambda x: sum(x) / len(x) if len(x) != 0 else 0, order=['Piccola', 'Media', 'Grande'])
plt.title('Distribuzione degli Stipendi per Dimensione dell'Azienda')
plt.xlabel('Dimensione dell'Azienda')
plt.ylabel('Stipendio Medio (USD)')
plt.xticks(rotation=45)
graphs.append(plt.gcf())
plt.show()
Ecco l’output.
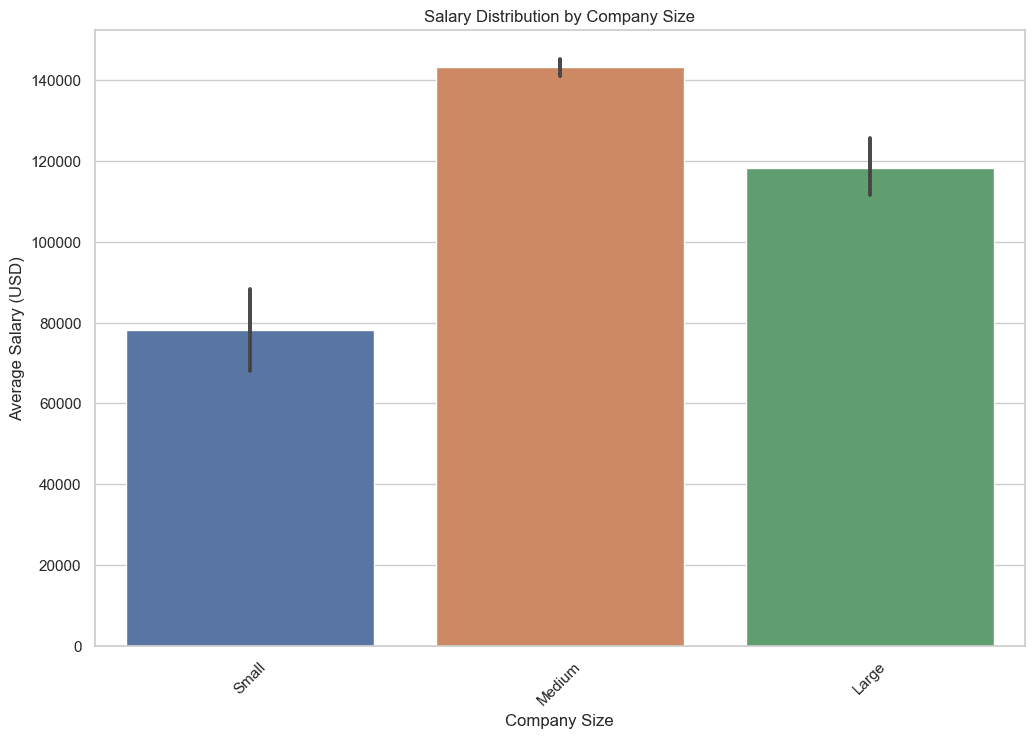
4. Dove si Trovano Principalmente i Lavori nel Data Science dal Punto di Vista Geografico?
Qui, individuiamo le prime 10 posizioni che offrono il maggior numero di opportunità di lavoro nel data science. Utilizziamo la funzione COUNT per determinare il numero di offerte di lavoro in ogni posizione, ordinandole in ordine decrescente per mettere in evidenza le aree con più opportunità.
Avere queste informazioni fornisce ai lettori la conoscenza delle aree geografiche che sono centri per i ruoli nel data science, aiutando nelle decisioni di potenziale trasferimento. Vediamo il codice.
SELECT company_location, COUNT(*) AS job_count
FROM salary_data
GROUP BY company_location
ORDER BY job_count DESC
LIMIT 10;
Ora creiamo grafici del codice sopra, utilizzando Python.
plt.figure(figsize=(12, 8))
sns.countplot(y='company_location', data=df, order=df['company_location'].value_counts().index[:10])
plt.title('Distribuzione Geografica dei Lavori nel Data Science')
plt.xlabel('Conteggio Lavori')
plt.ylabel('Posizione della Compagnia')
graphs.append(plt.gcf())
plt.show()
Vediamo il grafico qui sotto.
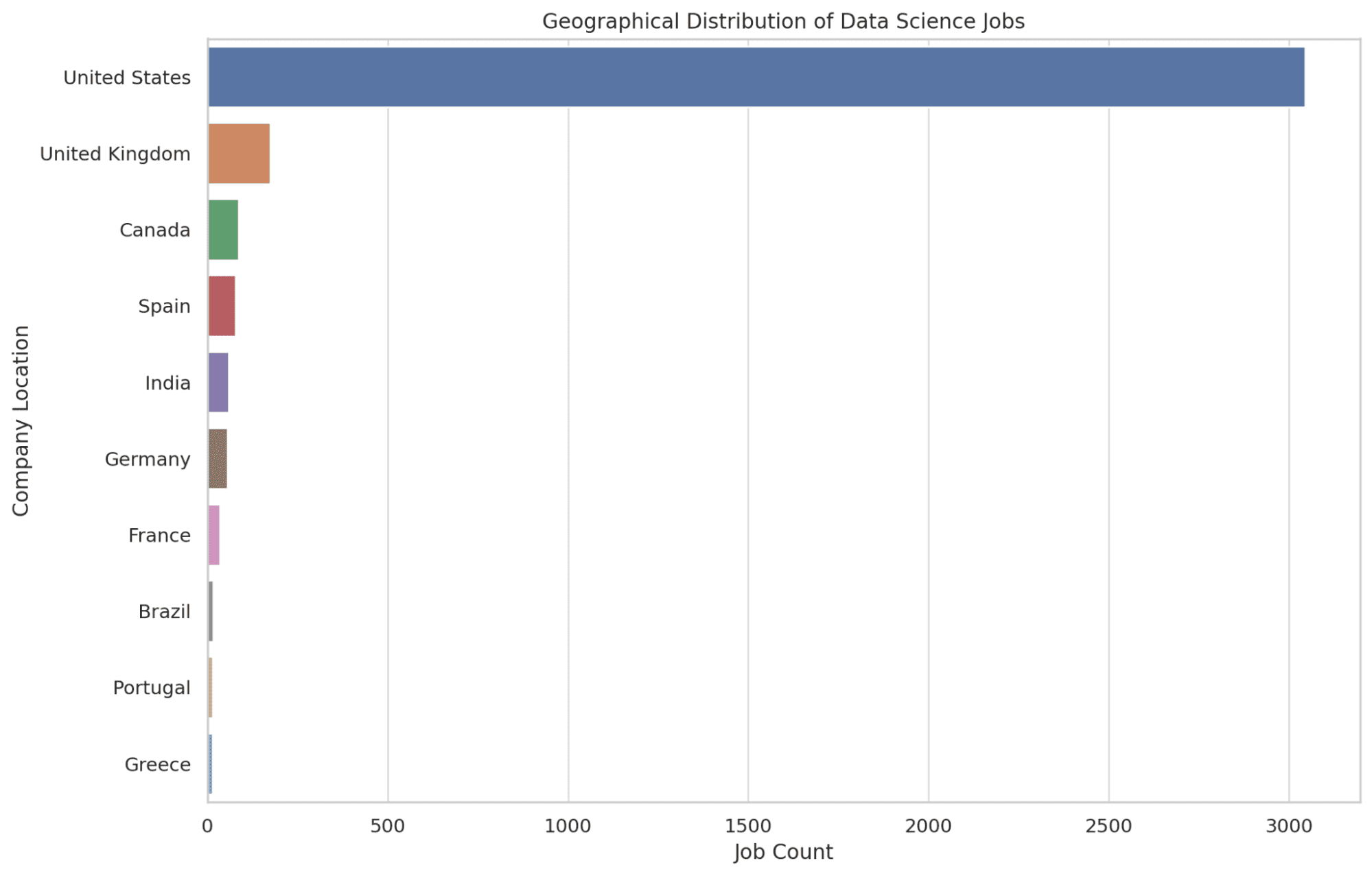
5. Quali sono i titoli di lavoro che offrono i salari più alti nel settore della Data Science?
Qui stiamo identificando i primi 10 titoli di lavoro con il salario più alto nel settore della Data Science. Utilizzando la funzione AVG, calcoliamo il salario medio per ogni titolo di lavoro, ordinandoli in ordine decrescente in base al salario medio per evidenziare le posizioni più lucrative.
Puoi aspirare alla tua carriera, guardando questi dati. Procediamo per capire come i lettori possono creare una visualizzazione in Python per questi dati.
SELECT job_title, AVG(salary_in_usd) AS avg_salary
FROM salary_data
GROUP BY job_title
ORDER BY avg_salary DESC
LIMIT 10;
Ecco l’output.
(Qui non possiamo utilizzare foto, perché abbiamo aggiunto 4 foto sopra e ne è rimasta una per una miniatura. Abbiamo la possibilità di utilizzare una tabella come quella qui sotto per mostrare l’output?)
| Posizione | Titolo di lavoro | Salario medio (USD) |
| 1 | Responsabile Tecnico della Data Science | 375,000.00 |
| 2 | Architetto dei Dati Cloud | 250,000.00 |
| 3 | Responsabile dei Dati | 212,500.00 |
| 4 | Responsabile dell’Analisi dei Dati | 211,254.50 |
| 5 | Data Scientist Principale | 198,171.13 |
| 6 | Direttore della Data Science | 195,140.73 |
| 7 | Ingegnere dei Dati Principale | 192,500.00 |
| 8 | Ingegnere del Software di Machine Learning | 192,420.00 |
| 9 | Responsabile della Data Science | 191,278.78 |
| 10 | Scienziato Applicato | 190,264.48 |
Questa volta, proviamo a creare un grafico da soli.
Suggerimenti: Puoi usare il seguente prompt in ChatGPT per generare un codice Pythonico di questo grafico:
<SQL Query qui>
Crea un grafico in Python per visualizzare i primi 10 titoli di lavoro con il salario più alto nella Data Science, simile alle informazioni raccolte dalla query SQL sopra.
Considerazioni finali
Mentre concludiamo il nostro viaggio attraverso i diversi terreni del mondo della carriera della Data Science, speriamo che SQL si dimostri una guida affidabile, aiutandoti a scoprire gemme di conoscenza per supportare le tue decisioni di carriera.
Spero che ora ti senti più preparato, non solo nel tracciare il tuo percorso di carriera, ma anche nell’utilizzare SQL per trasformare i dati grezzi in narrazioni potenti. Quindi, ecco a te che ti addentri in un futuro pieno di opportunità, con i dati come tua bussola e SQL come tua forza guida!
Grazie per aver letto! Nate Rosidi è un data scientist e stratega del prodotto. È anche un professore aggiunto che insegna analisi e fondatore di StrataScratch, una piattaforma che aiuta i data scientist a prepararsi per i colloqui con vere domande di intervista delle migliori aziende. Puoi connetterti con lui su Twitter: StrataScratch o LinkedIn.





