I ricercatori di Microsoft presentano SpeechX un modello di generazione del linguaggio versatile in grado di eseguire TTS a zero-shot e vari compiti di trasformazione del linguaggio parlato.
I ricercatori di Microsoft presentano SpeechX, un modello versatile che può eseguire TTS a zero-shot e vari compiti di trasformazione del linguaggio parlato.


Le applicazioni di machine learning multiple, tra cui testo, visione e audio, hanno visto sviluppi rapidi e significativi nella tecnologia dei modelli generativi. L’industria e la società hanno subito effetti significativi di questi sviluppi. In particolare, i modelli generativi con input multimodale sono diventati un vero e proprio sviluppo innovativo. Il text-to-speech (TTS) zero-shot è un noto problema di generazione della voce nel dominio della voce che utilizza l’input audio-testo. Utilizzando solo un piccolo frammento audio del parlante desiderato, il TTS zero-shot include la trasformazione di una fonte di testo in una voce con le caratteristiche vocali e il modo di parlare di quel parlante. Nelle prime ricerche sul TTS zero-shot sono stati utilizzati embedding di speaker dimensionalmente fissi. Questo metodo non supportava in modo efficace le capacità di clonazione degli speaker e limitava il suo utilizzo solo al TTS.
Tuttavia, le recenti strategie hanno incluso concetti più ampi come la previsione di discorsi mascherati e la modellazione del linguaggio codec neurale. Questi metodi all’avanguardia utilizzano l’audio del parlante di destinazione senza compressarlo in una rappresentazione unidimensionale. Di conseguenza, questi modelli hanno mostrato nuove caratteristiche, come la conversione vocale e la modifica del discorso, oltre alle loro eccezionali prestazioni nel TTS zero-shot. Questa maggiore adattabilità può espandere notevolmente il potenziale dei modelli di generazione della voce. Nonostante i loro incredibili risultati, questi modelli generativi attuali hanno comunque alcuni limiti, soprattutto nel trattamento di compiti di generazione della voce basati su audio e testo che includono la conversione del discorso di input.
Ad esempio, gli algoritmi attuali di modifica della voce sono limitati a elaborare solo segnali puliti e non possono modificare il contenuto parlato mantenendo il rumore di fondo. Inoltre, l’approccio discusso impone importanti limitazioni alla sua applicabilità pratica, richiedendo che il segnale rumoroso sia circondato da segmenti di discorsi puliti per completare la denoising. L’estrazione del parlante di destinazione è un compito particolarmente utile nel contesto della modifica del discorso non pulito. L’estrazione del parlante di destinazione è il processo di rimozione della voce di un parlante di destinazione da una miscela di discorsi che contiene diversi parlanti. È possibile specificare il parlante desiderato riproducendo un breve frammento di discorso di lui/lei. Come accennato, la generazione corrente di modelli di discorso generativi non può gestire questo compito nonostante la sua importanza potenziale.
- Intelligenza Artificiale Responsabile Modo per Evitare il Lato Oscuro dell’Uso dell’IA
- Machine Learning vs. AI vs. Deep Learning vs. Neural Networks Qual è la differenza?
- Esplorazione dell’interprete di codice di ChatGPT di OpenAI un’analisi approfondita delle sue capacità
I modelli di regressione sono stati storicamente utilizzati per il recupero affidabile del segnale in metodi classici per compiti di miglioramento del discorso come la denoising e l’estrazione del parlante di destinazione. Tuttavia, queste tecniche precedenti a volte richiedono modelli esperti diversi per ogni compito, il che non è ottimale data la varietà di disturbi acustici che possono verificarsi. Oltre a piccoli studi concentrati principalmente su determinati compiti di miglioramento del discorso, molto resta ancora da fare nella ricerca su modelli completi di miglioramento del discorso basati su audio e testo che utilizzano trascrizioni di riferimento per produrre un discorso comprensibile. Lo sviluppo di modelli di discorso generativi basati su audio e testo che integrano capacità di generazione e trasformazione assume una rilevanza critica nella ricerca alla luce dei fattori sopra citati e dei precedenti di successo in altre discipline.
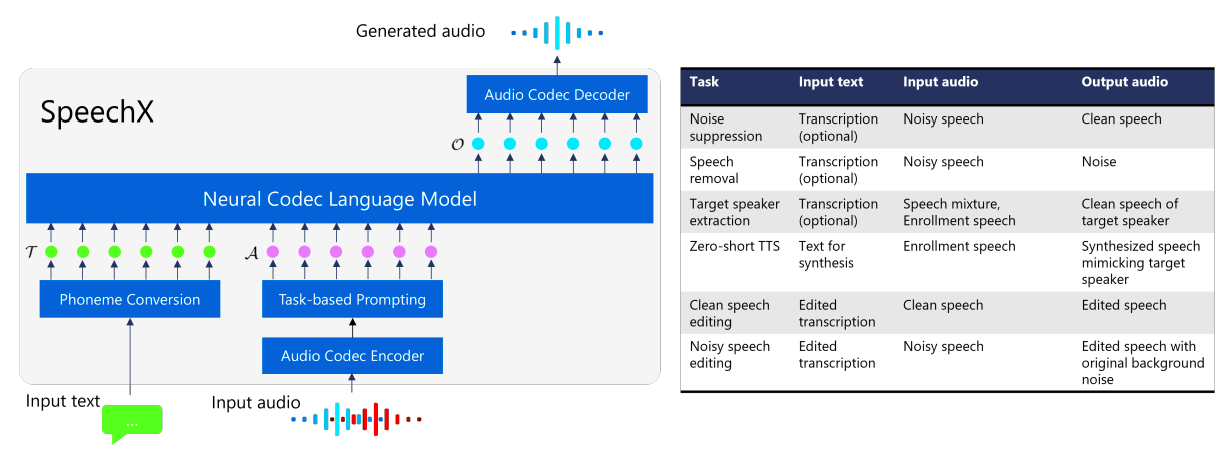
Questi modelli hanno la capacità di gestire vari compiti di generazione della voce. Suggeriscono che tali modelli dovrebbero includere le seguenti caratteristiche cruciali:
• Versatilità: I modelli unificati di generazione del discorso basati su audio e testo devono essere in grado di eseguire vari compiti che richiedono la generazione della voce da input audio e testo, simili ai modelli unificati o fondamentali prodotti in altri domini dell’apprendimento automatico. Queste attività dovrebbero includere non solo il TTS zero-shot, ma anche molti tipi di alterazione del discorso, tra cui, ad esempio, l’aumento del discorso e la modifica del discorso.
• Tolleranza: Poiché è probabile che i modelli unificati vengano utilizzati in contesti acusticamente difficili, devono dimostrare tolleranza a diverse distorsioni acustiche. Questi modelli possono essere utili in situazioni reali in cui il rumore di fondo è comune poiché forniscono prestazioni affidabili.
• Estendibilità: I modelli unificati devono utilizzare architetture flessibili per consentire l’espansione del supporto alle attività in modo fluido. Un modo per fare ciò è fornire spazio per nuovi componenti, come moduli aggiuntivi o token di input. I modelli saranno in grado di adattarsi meglio a nuovi compiti di generazione del parlato grazie a questa flessibilità efficiente. In questo articolo, i ricercatori di Microsoft Corporation introducono un modello flessibile di generazione del parlato per raggiungere questo obiettivo. È in grado di svolgere molteplici compiti, come la sintesi del parlato “zero-shot”, la soppressione del rumore utilizzando un input opzionale di trascrizione, la rimozione del parlato, l’estrazione del parlante di destinazione utilizzando un input opzionale di trascrizione e la modifica del parlato per ambienti acustici tranquilli e rumorosi (Fig. 1). Essi designano SpeechX1 come il loro modello consigliato.
Come per VALL-E, SpeechX adotta un approccio di modellazione del linguaggio che genera codici di un modello di codifica neurale, o token acustici, in base a input testuali e acustici. Per consentire la gestione di compiti diversi, incorporano token aggiuntivi in un ambiente di apprendimento multi-task, in cui i token specificano collettivamente il compito da eseguire. I risultati sperimentali, utilizzando 60.000 ore di dati vocali da LibriLight come set di addestramento, dimostrano l’efficacia di SpeechX, mostrando prestazioni comparabili o superiori rispetto ai modelli esperti in tutti i compiti sopra elencati. In particolare, SpeechX mostra capacità innovative o ampliate, come la conservazione dei suoni di fondo durante la modifica del parlato e l’utilizzo di trascrizioni di riferimento per la soppressione del rumore e l’estrazione del parlante di destinazione. Campioni audio che mostrano le capacità del loro modello SpeechX proposto sono disponibili su https://aka.ms/speechx.






