Guida alla Graph Attention Network (GAT) con Implementazione Visualizzata
Guida GAT con Implementazione Visualizzata
Comprendere le Reti Neurali Grafiche (GNN) è sempre più rilevante mentre i transformer continuano a affrontare problemi di grafo come quelli presenti nell’Open Graph Benchmark. Anche se il linguaggio naturale è tutto ciò di cui un grafo ha bisogno, le GNN rimangono una fonte ricca di ispirazione per i futuri metodi.
In questo post, seguirò l’implementazione di un layer GNN di base e mostrerò le modifiche per un layer di attenzione grafica di base come descritto nel paper ICLR intitolato Graph Attention Networks.

Inizialmente, immaginiamo di avere un grafo di documenti di testo rappresentato come un grafo aciclico diretto (DAG). Il documento 0 ha un collegamento ai documenti 1, 2 e 3, quindi ci sono 1 nella riga 0 per quelle colonne.
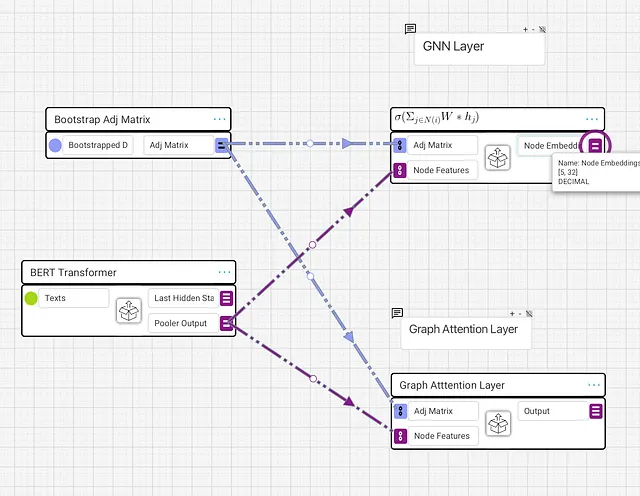
Per realizzare l’implementazione visualizzata, userò Graphbook, uno strumento di modellazione AI visuale. Consulta il mio altro post per ulteriori informazioni su come comprendere le rappresentazioni visive in Graphbook.
- L’vantaggio del LLM Trasformare la Ricerca nell’E-commerce
- Demistificazione dell’Apprendimento Automatico
- Addestrare un Variational Autoencoder per la Rilevazione di Anomalie Utilizzando TensorFlow

Abbiamo anche alcune caratteristiche dei nodi per ogni documento. Ho inserito ciascun documento in BERT come un singolo array unidimensionale [5] di testi per produrre una forma di embedding [5, 768] nell’output del Pooler.

A scopo didattico, prenderò solo le prime 8 dimensioni dell’output di BERT come le caratteristiche dei nodi in modo da poter seguire più facilmente le forme dei dati. Ora, abbiamo la nostra matrice di adiacenza e le nostre caratteristiche dei nodi.

Layer GNN
La formula generale per un layer GNN è che per ogni nodo, prendiamo tutti i vicini di ogni nodo e sommiamo le caratteristiche moltiplicate per una matrice di pesi, quindi passiamo attraverso una funzione di attivazione. Ho creato un blocco vuoto con questa formula come titolo e ho passato la matrice di adiacenza e le caratteristiche dei nodi, e implementerò quella formula all’interno del blocco.

Quando implementiamo questa formula, non vogliamo effettivamente eseguire un loop. Se possiamo completamente vettorizzare questo, allora addestramento e inferenza con le GPU saranno molto più veloci perché la moltiplicazione può essere un singolo passaggio di calcolo. Quindi, invece, ripetiamo (cioè diffondiamo) le caratteristiche dei nodi in una forma tridimensionale, quindi avevamo una forma [5, 8] delle caratteristiche dei nodi, ora avremo una forma [5, 5, 8] in cui ogni cella nella dimensione 0 è una ripetizione delle caratteristiche dei nodi. Possiamo pensare all’ultima dimensione come caratteristiche dei “vicini” ora. Ogni nodo ha un insieme di 5 possibili vicini.

Non possiamo diffondere direttamente le caratteristiche dei nodi da [5, 8] a una forma [5, 5, 8]. Invece, dobbiamo prima diffondere a [25, 8] perché durante la diffusione, ogni dimensione nella forma deve essere maggiore o uguale alla dimensione originale. Quindi è per questo che otteniamo le parti 5 e 8 della forma (get_sub_arrays) e quindi moltiplichiamo la prima per ottenere 25, poi le concateniamo tutte insieme. Infine, ridimensioniamo il risultato [25, 8] ottenuto a [5, 5, 8], e possiamo verificare in Graphbook che ogni insieme di caratteristiche dei nodi nelle ultime 2 dimensioni è identico.

In seguito, vogliamo anche trasmettere la matrice di adiacenza alla stessa forma. Ciò significa che per ogni 1 nella matrice di adiacenza nella riga i e colonna j, c’è una riga di 1.0 di num_feats alla dimensione [i, j]. Quindi in questa adiacenza, la riga 0 ha un 1 nella 1a, 2a e 3a colonne, quindi c’è una riga di num_feats 1.0 nelle righe 1, 2 e 3 nella cella 0 (cioè [0, 1:3, :]).

L’implementazione è piuttosto semplice qui, basta convertire la matrice di adiacenza in decimale e trasmetterla da una forma [5, 5] a una forma [5, 5, 8]. Ora possiamo moltiplicare elemento per elemento questa maschera di adiacenza con le nostre caratteristiche vicine del nodo ripetute.

Vogliamo anche includere un auto-loop nella nostra matrice di adiacenza, in modo che quando sommiamo le caratteristiche dei vicini, includiamo anche le caratteristiche del nodo stesso.

Dopo aver effettuato una moltiplicazione elemento per elemento (e aver incluso l’auto-loop), otteniamo le caratteristiche dei vicini per ogni nodo e zeri per i nodi che non sono collegati da un arco (non sono vicini). Per il nodo 0, ciò include le caratteristiche per i nodi da 0 a 3. Per il nodo 3, ciò include i nodi 3 e 4.

In seguito, ridimensioneremo a [25, 8] in modo che ogni caratteristica del vicino sia la propria riga e passeremo attraverso uno strato lineare parametrizzato con la dimensione nascosta desiderata. Qui ho scelto 32 e salvato come costante globale in modo che possa essere riutilizzato. L’output dello strato lineare sarà [25, hidden_size]. Basta ridimensionare quell’output, creare una forma [5, 5, hidden_size] e ora siamo finalmente pronti per la parte di somma della formula!

Sommeremo sulla dimensione centrale (indice di dimensione 1) in modo da sommare le caratteristiche dei vicini per ogni nodo. Il risultato è un insieme [5, hidden_size] di embedding dei nodi che hanno attraversato 1 strato. Basta concatenare questi strati insieme e avrai una rete GNN e seguire le guide su https://www.youtube.com/@Graphbook per sapere come allenare.
Strato di attenzione del grafo

Dal paper, il segreto dell’attività di attenzione del grafo è il coefficiente di attenzione, dato nella formula sopra. In sostanza, stiamo concatenando gli embedding dei nodi che sono in un arco e li stiamo facendo passare attraverso un altro strato lineare, prima di applicare softmax.

Questi coefficienti di attenzione vengono quindi utilizzati per calcolare una combinazione lineare delle caratteristiche corrispondenti alle feature originali del nodo.

Ciò che dobbiamo fare è replicare le caratteristiche di ciascun nodo per ogni vicino e quindi concatenarle con le caratteristiche dei vicini del nodo.

Il segreto consiste nel ottenere le caratteristiche del nodo ripetute per ogni vicino. Per fare ciò, scambiamo le dimensioni 0 e 1 delle caratteristiche del nodo ripetute prima di mascherarle.

Il risultato è ancora un array di forma [5, 5, 8], ma ora ogni riga in [i, :, :] è la stessa e corrisponde alla caratteristica del nodo i. Ora possiamo usare la moltiplicazione elemento per elemento per creare le caratteristiche del nodo ripetute solo quando contengono un vicino. Infine, concateniamo ciò con le caratteristiche del vicino come le abbiamo create per GNN e produciamo le caratteristiche concatenate.

Ci siamo quasi! Ora che abbiamo le caratteristiche concatenate, possiamo passarle attraverso uno strato lineare. Dobbiamo ridimensionarle nuovamente in [5, 5, hidden_size] in modo da poter calcolare la softmax sulla dimensione centrale e produrre i nostri coefficienti di attenzione.

Ora che abbiamo i nostri coefficienti di attenzione con forma [5, 5, hidden_size], che essenzialmente rappresentano una rappresentazione per ogni arco del grafo con n nodi. Il paper afferma che dovrebbero essere trasposti (scambiati di dimensione), quindi ho fatto questo prima di ReLU e ora calcolo la softmax sull’ultima dimensione in modo che siano normalizzati per indice di dimensione lungo la dimensione hidden_size. Moltiplicheremo questi coefficienti con le rappresentazioni originali dei nodi. Ricorda, le rappresentazioni originali dei nodi avevano forma [5, 5, 8], dove 8 è stato scelto arbitrariamente tagliando le prime 8 caratteristiche delle codifiche di BERT dei nostri documenti di testo.
Moltiplicare una forma di [5, hidden_size, 5] per una forma di [5, 5, 8] produce una forma di [5, hidden_size, 8]. Poi sommiamo sulla dimensione hidden_size per produrre infine una forma di [5, 8], corrispondente alla nostra forma di input. Possiamo anche passare questo attraverso una non linearità come un’altra ReLU, e poi concatenare questo strato diverse volte.
Conclusioni
Fino ad ora, abbiamo esaminato un’implementazione visuale di singoli strati GNN e strati GAT. Puoi trovare il progetto in questo repository di GitHub. Nel paper, spiegano anche come estendere il metodo per l’attenzione a più testate. Fammi sapere nei commenti se desideri che tratti anche questa parte, o se c’è qualcos’altro che vorresti che trattassi usando Graphbook.




