Un modello a due torri potenziato con doppia realtà per la raccomandazione online su larga scala
Un modello a doppia torre potenziato per la raccomandazione online su larga scala
Un’immersione profonda nel modello di recupero a due torri di Meituan
I sistemi di raccomandazione sono algoritmi progettati per fornire suggerimenti personalizzati agli utenti. Questi sistemi vengono utilizzati in vari settori per aiutare gli utenti a scoprire elementi rilevanti, come prodotti (e-commerce come Amazon), altri utenti (social media come X, LinkedIn), contenuti (social media come X, Instagram, Reddit) o informazioni (app di notizie o social media come X, Reddit o piattaforme come VoAGI e Quora), in base alle loro preferenze, comportamento o contesto. I sistemi di raccomandazione mirano a migliorare l’esperienza dell’utente offrendo suggerimenti personalizzati e mirati, facilitando in ultima analisi la presa di decisioni e l’interazione. In generale, un sistema di raccomandazione è composto dal recupero di entità (elementi, utenti, informazioni) seguito dalla classifica delle entità recuperate.

In questo articolo verrà discusso il “Dual Augmented Two-tower Model for Online Large-scale Recommendation”, un’architettura di modello di recupero proposta dai ricercatori di Meituan, un’azienda di e-commerce cinese. Si tratta di una versione migliorata del popolare modello a due torri utilizzato nei sistemi di raccomandazione.
Modello a due torri
Iniziamo con il modello a due torri. Il termine “due torri” deriva dalle due “torri” separate nell’architettura, una per ogni entità. Il modello a due torri è progettato per catturare e apprendere incorporamenti di due diverse entità separatamente. Queste entità potrebbero essere “utente-utente”, “utente-elemento” o “query di ricerca-elemento” in base al caso d’uso. Il modello è composto dalle due torri con strati di incorporamento, seguite da uno strato di interazione per catturare la loro relazione e uno strato di output per generare punteggi di raccomandazione.
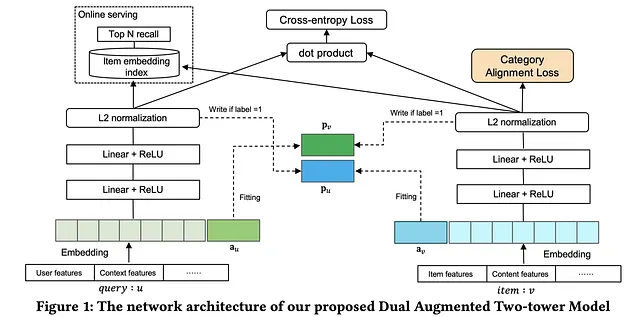
Uno svantaggio del modello a due torri originale è la mancanza di interazione tra le due entità. Non c’è interazione tra le due entità a parte lo strato di interazione finale, dove i loro incorporamenti rispettivi vengono utilizzati per calcolare una metrica di similarità come la similarità del coseno. Il documento risolve questa problematica introducendo un nuovo meccanismo adattivo-mimico. Il documento fornisce anche una soluzione per risolvere il problema dell’imbilanciamento delle categorie. In molti casi d’uso, come l’e-commerce, alcune categorie possono contenere un numero maggiore di elementi e quindi più interazione tra gli utenti, mentre altre categorie possono contenere un numero minore di elementi e meno interazione tra gli utenti. Il documento introduce una perdita di allineamento delle categorie per mitigare l’effetto dell’imbilanciamento delle categorie sulle raccomandazioni generate. Il seguente diagramma mostra l’architettura della rete.
- Mosaici fotografici con i vicini più prossimi Machine Learning per l’arte digitale
- UltraFastBERT Modello di linguaggio esponenzialmente più veloce
- Il futuro dei GPT di OpenAI – Analisi SWOT 2024
|  |
Problema dichiarato
Prendiamo ad esempio l’uso di “query di ricerca-elemento”. Ci sono stati dati un insieme di N query u_i (i = 1, 2, ..., N), un insieme di M elementi v_j (j = 1, 2, ..., M) e la matrice di feedback query-elemento R. R è una matrice binaria, R_ij = 1 indica un feedback positivo tra la query corrispondente u_i e l’elemento v_j, mentre R_ij = 0 indica il contrario. L’obiettivo è recuperare un dato numero di elementi candidati da un’enorme gamma di elementi in base alla query fornita dall’utente.
Dual Augmented Two-tower Model
Il modello Dual Augmented Two-tower (DAT) ha i seguenti componenti
- Strato di incorporamento – Simile al modello a due torri, ogni query o caratteristica dell’elemento viene convertita nella sua rappresentazione di incorporamento (di solito sparsa). Queste caratteristiche potrebbero essere caratteristiche dell’utente/elemento, caratteristiche del contesto/contenuto, ecc.
- Strato dual augmented – Per una determinata query e elemento candidato, i loro vettori aumentati
a_uea_vvengono creati e concatenati nei rispettivi incorporamenti delle caratteristiche. Quando allenati e appresi, ci aspettiamo che i vettori aumentati contengano informazioni non solo sulla query e l’elemento corrente, ma anche informazioni sulle loro interazioni positive storiche. L’immagine seguente mostra un esempio di incorporazioni di input concatenate.

- Strati di feedforward – Gli incorporamenti concatenati
z_uez_vvengono inviati attraverso gli strati di feedforward; l’output di ciascuna torre è una rappresentazione a bassa dimensione di una queryp_ue di un elementop_v. Viene eseguita una normalizzazione L2, seguita dal loro prodotto interno. L’output del modello ès(u, v) = <p_u, p_v>. L’output ottenuto viene considerato come il punteggio della coppia query-elemento data. - Mechanismo adattivo di mimesi (AMM) – I vettori aumentati,
a_uea_v, vengono appresi utilizzando le perdite di mimesi. Le perdite di mimesi mirano a utilizzare i vettori aumentati per adattarsi a tutte le interazioni positive nell’altra torre che appartiene alla query o all’elemento corrispondente. Se l’etichettay = 1,a_vsi avvicina ap_uea_usi avvicina ap_v. In questo caso, le funzioni di perdita mirano a ridurre la distanza traa_vep_ue traa_uep_vrispettivamente. Se l’etichettay = 0, i termini di perdita sono nulli. I vettori aumentati vengono utilizzati in una torre e gli incorporamenti della query/elemento vengono generati dall’altra. Vale a dire, i vettori aumentati riassumono le informazioni di alto livello su ciò che una query o un elemento corrisponde eventualmente nell’altra torre. Poiché la perdita di mimesi serve ad aggiornarea_uea_v, dovremmo bloccare i valori dip_uep_v.

- Allineamento delle categorie – Secondo gli autori, il modello a due torri si comporta in modo diverso a seconda delle categorie. Si comporta molto peggio nelle categorie con un numero relativamente minore di elementi. Per affrontare il problema, hanno introdotto la perdita di allineamento delle categorie (CAL), che trasferisce le conoscenze apprese nelle categorie con una grande quantità di dati ad altre categorie. Per ogni batch, CAL è definita come la somma della norma di Frobenius tra la matrice di covarianza dell’elemento della categoria maggioritaria in quel batch
C(S^major)e le matrici di covarianza degli altri elementi della categoria in quel batchC(S^i). Questa perdita garantisce che le covarianze (che sono statistiche di secondo ordine) rimangano consistenti in tutte le categorie. Si noti che gli incorporamenti dell’elemento,p_v, vengono utilizzati per calcolare le matrici di covarianza.

Allenamento del modello
Il problema viene modellato come un compito di classificazione binaria, ovvero se l’elemento recuperato è rilevante o meno. La tupla {u_i, v_j, R_ij=y} viene alimentata al modello durante l’allenamento. Viene utilizzato un framework di campionamento casuale negativo per creare batch di allenamento. Durante l’allenamento, un batch di input consiste in una coppia positiva di query-elemento (etichetta y = 1) e S coppie di query-elemento campionate casualmente negative (etichetta y = 0). Qui viene utilizzata una perdita di cross-entropia.

La funzione di perdita finale è mostrata di seguito —

Dettagli di implementazione
Le incorporazioni sono state ridotte a una dimensione di 32 utilizzando tre layer di rete totalmente connessi di dimensioni 256, 128 e 32. La dimensione dei vettori aumentati è stata anch’essa impostata su 32. Gli autori hanno condotto i loro esperimenti sul proprio dataset Meituan e sul dataset pubblicamente disponibile di Amazon Books.

Risultati ed valutazione
Per la valutazione, sono stati utilizzati HitRate@K e Mean Reciprocal Rank (MRR). K è stato impostato su 50 e 100. A causa della grande quantità di istanze di test, gli autori hanno ridimensionato l’MRR di un fattore di 10.
- HitRate@K — Una metrica che misura la proporzione di istanze in cui la raccomandazione vera positiva viene trovata tra le prime K raccomandazioni.
- Mean Reciprocal Rank (MRR) — Una metrica ottenuta calcolando la media del reciproco del rango della prima raccomandazione corretta.
La seguente tabella riassume i risultati e confronta i risultati del modello DAT con altri modelli come il modello di fattorizzazione della matrice, il modello two-tower e YouTubeDNN ecc. DAT si è comportato meglio dimostrando l’efficacia sia di AMM che di CAL.

Gli autori hanno modificato la dimensione dei vettori aumentati e osservato il cambiamento delle prestazioni. È possibile osservare i risultati nei seguenti grafici.

I due risultati sopra riportati si basavano su studi offline. Gli autori hanno osservato le prestazioni del modello sulle seguenti metriche implementandolo per gestire il traffico reale coinvolgendo 60 milioni di utenti per una settimana.
- Click-Through Rate (CTR) — Una metrica che misura la percentuale di utenti che fanno clic su un elemento, indicando l’efficacia del contenuto coinvolgente.
- Gross Merchandise Value (GMV) — Una metrica che rappresenta il valore totale di beni o servizi venduti attraverso una piattaforma.
In questo caso, il modello two-tower originale è stato considerato il punto di riferimento. Entrambi i modelli hanno recuperato 100 elementi candidati. Il recupero dei candidati viene effettuato utilizzando una ricerca di nearest neighbor approssimativa. Gli elementi recuperati sono stati alimentati allo stesso algoritmo di ranking per un confronto equo. Il modello DAT ha superato il punto di riferimento di molto, con un miglioramento medio complessivo del 4,17% e del 3,46% in termini di CTR e GMV, rispettivamente.

Per concludere, il modello two-tower with Dual Augmentation si propone di facilitare le interazioni profonde tra le torri e produrre migliori rappresentazioni per i dati di categoria squilibrata, migliorando così le metriche di recupero come HitRate@K e MRR e le metriche di ranking come CTR e GMV.
Spero che tu trovi l’articolo illuminante. Ecco il link all’articolo originale – Un modello a due torri rafforzate per raccomandazioni su larga scala online (dlp-kdd.github.io).
Grazie per la lettura!






