Un Approccio Pratico all’Ingegneria delle Feature nel Machine Learning
Approccio Pratico all'Ingegneria delle Feature nel Machine Learning

Il feature learning è una componente vitale del machine learning, ma spesso se ne parla poco, con molti guide e post di blog che si concentrano sulle fasi successive del ciclo di vita del ML. Questo passaggio di supporto può rendere i modelli di machine learning più precisi ed efficienti, trasformando i dati grezzi in qualcosa di più tangibile e pronto all’uso. Senza di esso, costruire un modello completamente ottimizzato è impossibile.
In questo articolo parleremo di come funziona il feature learning nel machine learning e di come può essere implementato in semplici, pratici passaggi. Inoltre, discuteremo anche alcuni svantaggi del ML, fornendo una panoramica completa di questo processo essenziale.
- 5 abitudini di ingegneria per prompt di AI per visualizzazioni dei dati Python perfette
- 50 suggerimenti per il knolling a metà del viaggio (fotografia flat lay)
- Top 10 utilizzi di Python nel mondo reale con esempi
Cos’è l’ingegneria delle feature?
L’ingegneria delle feature è una tecnica importante del machine learning (ML) che elabora i dataset e li trasforma in un insieme di cifre utilizzabili e rilevanti per compiti specifici.
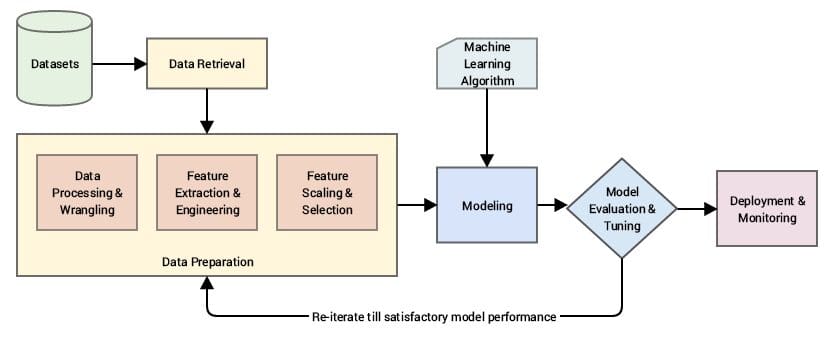
Le feature sono gli elementi di dati che vengono analizzati, apparendo come colonne all’interno di un dataset. Correggendo, ordinando e normalizzando questi elementi di dati, i modelli possono essere ottimizzati per una migliore performance. Il feature learning modifica questi elementi di dati per renderli rilevanti, rendendo così i modelli più accurati e con tempi di risposta più rapidi grazie all’uso di meno variabili.
Il processo di ingegneria delle feature può essere suddiviso come segue:
- Viene eseguita un’analisi per correggere eventuali problemi riscontrati nei dati, come campi incompleti, incongruenze e altre anomalie.
- Vengono eliminate tutte le variabili che non hanno alcuna rilevanza per il comportamento del modello.
- I dati duplicati vengono scartati.
- I record vengono correlati e normalizzati.
Perché l’ingegneria delle feature è così importante nel machine learning?
Senza l’ingegneria delle feature, non sarebbe possibile progettare modelli predittivi in grado di svolgere accuratamente la propria funzione. Il feature learning riduce anche il tempo e le risorse di calcolo necessarie, rendendo i modelli più efficienti.
Le feature dei dati determinano il funzionamento del modello predittivo, aiutando ad addestrare ciascun modello per ottenere i risultati desiderati. Ciò significa che anche i dati che non sono completamente applicabili a una specifica funzione possono essere modificati per ottenere un risultato adeguato. Il feature learning riduce anche significativamente il tempo trascorso in seguito nell’analisi dei dati.
Ingegneria delle feature: vantaggi e svantaggi
Anche se l’ingegneria delle feature è essenziale, presenta alcuni limiti, oltre ai vantaggi ovvi, elencati di seguito.
Ingegneria delle feature: Vantaggi
- I modelli con feature ingegnerizzate beneficiano di un’elaborazione dei dati più veloce.
- I modelli sono semplificati e, di conseguenza, più facili da mantenere.
- Le previsioni e le stime sono più accurate.
Ingegneria delle feature: Svantaggi
- L’ingegneria delle feature può richiedere molto tempo.
- È necessaria un’analisi approfondita per creare un elenco di feature efficace. Questo include una comprensione approfondita dei dataset, dei comportamenti di elaborazione del modello e del contesto aziendale.
Un approccio pratico all’ingegneria delle feature nel machine learning: sei passaggi
Ora che abbiamo una migliore comprensione di ciò che il feature learning può fare, così come dei suoi svantaggi, consideriamo un approccio pratico al processo in 6 passaggi chiave.
#1 Preparazione dei dati
Il primo passaggio nel processo di ingegneria delle feature è convertire i dati grezzi raccolti da una serie di fonti in un formato utilizzabile. I formati ML utilizzabili includono: .csc; .tfrecords; .json; .xml; e .avro. Per preparare i dati, devono essere sottoposti a una serie di processi come pulizia, fusione, ingestione e caricamento.
#2 Analisi dei dati
La fase di analisi, talvolta indicata come fase esplorativa, è quando vengono estratti insight e statistiche descrittive dai dataset, che vengono poi presentati in visualizzazioni per comprendere meglio i dati. Ciò è seguito dall’identificazione delle variabili correlate e delle loro proprietà in modo da poterle pulire.
#3 Miglioramento
Una volta che i dati sono stati analizzati e puliti, è il momento di migliorarli aggiungendo eventuali valori mancanti, normalizzandoli, trasformandoli e ridimensionandoli. I dati possono anche essere ulteriormente modificati aggiungendo valori dummy, che sono variabili qualitative/discrete che rappresentano dati categorici.
#4 Costruzione
Le caratteristiche possono essere costruite sia manualmente che automaticamente utilizzando algoritmi (come tSNE o Principal Component Analysis (PCA), ad esempio). Ci sono un numero quasi inesauribile di opzioni quando si tratta di costruzione delle caratteristiche. Tuttavia, la soluzione dipenderà sempre dal problema.
#5 Selezione
La selezione delle caratteristiche/variabili/attributi riduce il numero di variabili di input (colonne delle caratteristiche) scegliendo solo quelle più rilevanti per la variabile che il modello è stato costruito per prevedere. Ciò aiuta a ottenere migliori tempi di elaborazione e ridurre l’uso delle risorse computazionali.
Le tecniche di selezione delle caratteristiche includono:
- Filtri per rimuovere eventuali caratteristiche non rilevanti.
- Wrapper per addestrare modelli di machine learning a utilizzare più caratteristiche
- Modelli ibridi che combinano filtri e wrapper
Ad esempio, le tecniche basate su filtri si basano su test statistici per determinare se la caratteristica correla in modo sufficiente con la variabile target.
#6 Valutazione e Verifica
Il processo di valutazione determina l’accuratezza del modello in termini di dati di addestramento utilizzando le caratteristiche selezionate. Se il livello di accuratezza soddisfa lo standard richiesto, allora il modello può essere verificato. In caso contrario, sarà necessario ripetere la fase di selezione delle caratteristiche.
Casi d’uso dell’Ingegneria delle Caratteristiche
Ora diamo un’occhiata a tre casi d’uso comuni dell’ingegneria delle caratteristiche nell’apprendimento automatico.
Ulteriori Informazioni dallo Stesso Dataset
Molti dataset contengono valori arbitrari, come ad esempio data, età, ecc., che potrebbero essere modificati in diversi formati che forniscono informazioni specifiche riguardanti una query. Ad esempio, i dettagli sulla data e sulla durata possono essere incrociati per determinare i comportamenti degli utenti, come ad esempio con quale frequenza visitano un sito web e quanto tempo vi passano.
Modelli Predittivi
La selezione delle caratteristiche corrette può contribuire a costruire modelli predittivi per una serie di settori, come ad esempio il trasporto pubblico, aiutando a valutare quanti passeggeri potrebbero utilizzare un servizio in un determinato giorno.
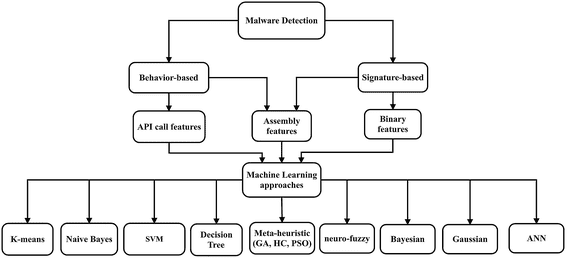
Rilevamento del Malware
Il rilevamento manuale del malware è estremamente difficile e la maggior parte delle reti neurali ha anche problemi in questo senso. Tuttavia, l’ingegneria delle caratteristiche può combinare tecniche manuali e reti neurali per evidenziare comportamenti insoliti.
Conclusioni sull’Ingegneria delle Caratteristiche nell’Apprendimento Automatico
L’ingegneria delle caratteristiche è una fase importante nella costruzione di modelli di apprendimento automatico e ottenere questa fase correttamente può garantire che i modelli di apprendimento automatico siano più accurati, utilizzino meno risorse computazionali ed elaborino a velocità superiori.
Il processo di ingegneria delle caratteristiche può essere suddiviso in sei fasi, dalla preparazione iniziale dei dati alla verifica, scegliendo solo gli elementi dati più rilevanti per un compito specifico. Nahla Davies è una sviluppatrice di software e scrittrice tecnica. Prima di dedicarsi a tempo pieno alla scrittura tecnica, ha lavorato come programmatrice principale presso un’organizzazione di branding esperienziale Inc. 5,000 i cui clienti includono Samsung, Time Warner, Netflix e Sony.






