Analisi delle prestazioni e ottimizzazione del modello PyTorch – Parte 6
Analisi prestazioni e ottimizzazione PyTorch - Parte 6
Come Identificare e Analizzare Problemi di Prestazioni nel Passaggio All’Indietro con PyTorch Profiler, PyTorch Hooks e TensorBoard
Questo è il sesto articolo della nostra serie di post sul tema dell’analisi e dell’ottimizzazione dei modelli PyTorch utilizzando PyTorch Profiler e TensorBoard. In questo post affronteremo uno dei tipi di problemi di prestazioni più complicati da analizzare – un collo di bottiglia nel passaggio della retropropagazione di un passo di addestramento. Spiegheremo cosa rende questo tipo di collo di bottiglia particolarmente sfidante e proporremo un modo di analizzarlo utilizzando il supporto integrato di PyTorch per l’attacco di hooks a diverse parti del passo di addestramento. Un grande ringraziamento a Yitzhak Levi per il suo contributo a questo post.
Modello Giocattolo
Per agevolare la nostra discussione, definiamo un semplice modello di classificazione basato su Vision Transformer (ViT) utilizzando il popolare modulo python timm (versione 0.9.7). Definiamo il modello con il flag patch_drop_rate impostato su 0.5, il che fa sì che il modello elimini casualmente la metà delle patch in ogni passo di addestramento. Lo script di addestramento è programmato per minimizzare la non determinismo, utilizzando la funzione torch.use_deterministic_algorithms e la variabile di ambiente cuBLAS, CUBLAS_WORKSPACE_CONFIG. Si prega di consultare il blocco di codice sottostante per la definizione completa del modello:
import torch, time, osimport torch.optimimport torch.profilerimport torch.utils.datafrom timm.models.vision_transformer import VisionTransformerfrom torch.utils.data import Dataset# usa la GPUdevice = torch.device("cuda:0")# configura PyTorch per l'utilizzo di algoritmi riproducibilitorch.manual_seed(0)os.environ[ "CUBLAS_WORKSPACE_CONFIG" ] = ":4096:8"torch.use_deterministic_algorithms(True)# definisci il modello di classificazione basato su ViTmodel = VisionTransformer(patch_drop_rate=0.5).cuda(device)# definisci la funzione di perditaloss_fn = torch.nn.CrossEntropyLoss()# definisci l'ottimizzatore di addestramentooptimizer = torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9)# usa dati casualiclass FakeDataset(Dataset): def __len__(self): return 1000000 def __getitem__(self, index): rand_image = torch.randn([3, 224, 224], dtype=torch.float32) label = torch.tensor(data=[index % 1000], dtype=torch.int64) return rand_image, labeltrain_set = FakeDataset()train_loader = torch.utils.data.DataLoader(train_set, batch_size=128, num_workers=8, pin_memory=True)t0 = time.perf_counter()summ = 0count = 0model.train()# ciclo di addestramento avvolto con un oggetto profilerwith torch.profiler.profile( schedule=torch.profiler.schedule(wait=1, warmup=4, active=3, repeat=1), on_trace_ready=torch.profiler.tensorboard_trace_handler('/tmp/perf')) as prof: for step, data in enumerate(train_loader): inputs = data[0].to(device=device, non_blocking=True) label = data[1].squeeze(-1).to(device=device, non_blocking=True) with torch.profiler.record_function('forward'): outputs = model(inputs) loss = loss_fn(outputs, label) optimizer.zero_grad(set_to_none=True) with torch.profiler.record_function('backward'): loss.backward() with torch.profiler.record_function('optimizer_step'): optimizer.step() prof.step() batch_time = time.perf_counter() - t0 if step > 1: # salta il primo passo summ += batch_time count += 1 t0 = time.perf_counter() if step > 500: break print(f'tempo medio del passo: {summ/count}')Eseguiremo i nostri esperimenti su un’istanza Amazon EC2 g5.2xlarge (contenente una GPU NVIDIA A10G e 8 vCPUs) utilizzando l’immagine Docker ufficiale di AWS PyTorch 2.0.
Risultati Iniziali delle Prestazioni
Nell’immagine sottostante riportiamo i risultati delle prestazioni visualizzati nella vista Traccia del plugin TensorBoard:
- Valutazione dell’impatto totale dell’esperimento
- Ripensare l’Assicurazione della Qualità nell’era dell’AI Generativa
- Allenare e distribuire modelli di apprendimento automatico in un ambiente multicloud utilizzando Amazon SageMaker
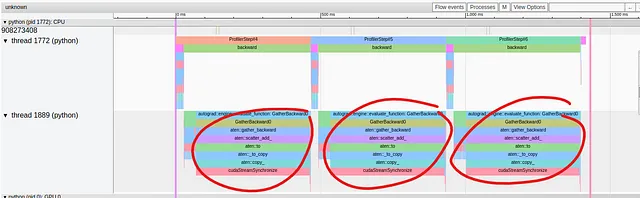
Mentre le operazioni nel passaggio in avanti della fase di addestramento sono raggruppate nel thread superiore, sembra che si presenti un problema di prestazioni nel passaggio all’indietro nel thread inferiore. Lì vediamo che una singola operazione, GatherBackward, occupa una parte significativa della traccia. Osservando più da vicino, possiamo vedere che le operazioni sottostanti includono “to”, “copy_” e “cudaStreamSynchronize”. Come abbiamo visto nella parte 2 della nostra serie, queste operazioni indicano tipicamente che i dati vengono copiati dall’host al dispositivo, qualcosa che vorremmo evitare durante il passaggio dell’addestramento.
A questo punto ti starai naturalmente chiedendo: perché succede questo? E quale parte della nostra definizione del modello lo sta causando? La traccia GatherBackward suggerisce che potrebbe essere coinvolta un’operazione torch.gather, ma da dove viene e perché causa un evento di sincronizzazione?
Nei nostri post precedenti (ad esempio qui), abbiamo sostenuto l’uso dei gestori di contesto labeled torch.profiler.record_function per individuare la fonte di un problema di prestazioni. Il problema qui è che il problema di prestazioni si verifica nel passaggio all’indietro su cui non abbiamo controllo! In particolare, non abbiamo la possibilità di avvolgere singole operazioni nel passaggio all’indietro con gestori di contesto. In teoria, si potrebbe identificare l’operazione del modello problematica attraverso un’analisi approfondita della vista della traccia e abbinando ogni segmento nel passaggio all’indietro con la sua operazione corrispondente nel passaggio in avanti. Tuttavia, questo non solo può essere piuttosto tedioso, ma richiede anche una conoscenza approfondita di tutte le operazioni a basso livello del passaggio dell’addestramento del modello. Il vantaggio nell’utilizzare le etichette torch.profiler.record_function era che ci ha permesso di concentrarci facilmente sulle porzioni problematiche del nostro modello. Idealmente, vorremmo essere in grado di mantenere la stessa capacità anche nel caso di problemi di prestazioni nel passaggio all’indietro. Nella prossima sezione descriveremo come ciò può essere realizzato utilizzando gli hook di PyTorch.
Analisi delle prestazioni con gli hook all’indietro di PyTorch
Anche se PyTorch non consente di avvolgere singole operazioni nel passaggio all’indietro, consente di aggiungere funzionalità personalizzate tramite il supporto degli hook. PyTorch supporta la registrazione degli hook sia su torch.Tensor che su torch.nn.Module. Sebbene la tecnica che proporremo in questo post si basi sulla registrazione degli hook all’indietro ai moduli, la registrazione degli hook sui tensori può essere utilizzata in modo simile per sostituire o ampliare il metodo basato sui moduli.
Nel blocco di codice sottostante definiamo una funzione wrapper che prende un modulo e registra sia un full_backward_hook che un full_backward_pre_hook (anche se nella pratica uno dovrebbe essere sufficiente). Ogni hook è programmato per aggiungere semplicemente un messaggio alla traccia di profiling catturata utilizzando la funzione torch.profiler.record_function. Il backward_pre_hook è programmato per stampare un messaggio “before” e il backward_hook un messaggio “after”. Viene aggiunta una stringa opzionale dei dettagli per distinguere tra più istanze dello stesso tipo di modulo.
def backward_hook_wrapper(module, details=None): # definire la funzione register_full_backward_pre_hook def bwd_pre_hook_print(self, output): message = f'before backward of {module.__class__.__qualname__}' if details: message = f'{message}: {details}' with torch.profiler.record_function(message): return output # definire la funzione register_full_backward_hook def bwd_hook_print(self, input, output): message = f'after backward of {module.__class__.__qualname__}' if details: message = f'{message}: {details}' with torch.profiler.record_function(message): return input # registrare gli hook module.register_full_backward_pre_hook(bwd_pre_hook_print) module.register_full_backward_hook(bwd_hook_print) return moduleUtilizzando la funzione backward_hook_wrapper, possiamo iniziare il lavoro di individuazione della fonte del nostro problema di prestazioni. Iniziamo avvolgendo solo il modello e la funzione di perdita come nel blocco di codice seguente:
model = backward_hook_wrapper(model)loss_fn = backward_hook_wrapper(loss_fn)Utilizzando la casella di ricerca della vista traccia del plugin TensorBoard, possiamo identificare le posizioni dei nostri messaggi “before” e “after” e dedurre dove inizia e finisce la propagazione all’indietro del modello e della perdita. Questo ci consente di concludere che il problema di prestazioni si verifica nel passaggio all’indietro del modello. Il passo successivo è avvolgere i moduli interni di Vision Tranformer con la nostra funzione backward_hook_wrapper:
model.patch_embed = backward_hook_wrapper(model.patch_embed)model.pos_drop = backward_hook_wrapper(model.pos_drop)model.patch_drop = backward_hook_wrapper(model.patch_drop)model.norm_pre = backward_hook_wrapper(model.norm_pre)model.blocks = backward_hook_wrapper(model.blocks)model.norm = backward_hook_wrapper(model.norm)model.fc_norm = backward_hook_wrapper(model.fc_norm)model.head_drop = backward_hook_wrapper(model.head_drop)Nel blocco di codice sopra, abbiamo specificato ciascuno dei moduli interni. Un modo alternativo per incapsulare tutti i moduli di primo livello del modello è iterare su di essi utilizzando named_children:
for submodule in model.named_children(): submodule = backward_hook_wrapper(submodule)L’immagine di cattura sottostante mostra la presenza del messaggio “before backward di PatchDropout” proprio prima dell’operazione GatherBackward problematica:

La nostra analisi di profilazione ha indicato che la fonte del problema di prestazioni è il modulo PathDropout. Esaminando la funzione forward del modulo, possiamo effettivamente vedere una chiamata a torch.gather.
Nel caso del nostro modello di esempio, abbiamo avuto bisogno di soli due cicli di analisi per individuare la fonte del problema di prestazioni. In pratica, è probabile che siano necessarie ulteriori iterazioni di questo metodo.
Si noti che PyTorch include la funzione torch.nn.modules.module.register_module_full_backward_hook che, in una singola chiamata, appende un hook a tutti i moduli nella fase di addestramento. Sebbene ciò possa essere sufficiente nei casi semplici (come nel nostro esempio di esempio), non consente di distinguere tra diverse istanze dello stesso tipo di modulo.
Ora che conosciamo la fonte del problema di prestazioni, possiamo lavorare per cercare di risolverlo.
Proposta di ottimizzazione: Usa l’Indicizzazione al Posto di Gather Ovunque Possibile
Ora che sappiamo che la fonte del problema è nell’operazione torch.gather del modulo DropPatches, possiamo cercare quale potrebbe essere il trigger dell’evento di sincronizzazione lungo tra host e dispositivo. La nostra indagine ci riporta alla documentazione della funzione torch.use_deterministic_algorithms che ci informa che, quando chiamata su un tensore CUDA che richiede gradiente, torch.gather presenta un comportamento non deterministico, a meno che torch.use_deterministic_algorithms non venga chiamato con modalità impostata su True. In altre parole, configurando il nostro script per utilizzare algoritmi deterministici, abbiamo modificato il comportamento predefinito del passaggio backward di torch.gather. Come si scopre, è proprio questa modifica che causa la necessità di un evento di sincronizzazione. Infatti, se rimuoviamo questa configurazione, il problema di prestazioni scompare! La domanda è: possiamo mantenere la determinismo dell’algoritmo senza dover pagare una penalità sulle prestazioni.
Nel blocco di codice sottostante proponiamo una implementazione alternativa della funzione forward del modulo PathDropout che produce lo stesso output utilizzando l’indicizzazione dei tensori di torch.Tensor anziché torch.gather. Le linee di codice modificate sono state evidenziate.
from timm.layers import PatchDropoutclass MyPatchDropout(PatchDropout): def forward(self, x): prefix_tokens = x[:, :self.num_prefix_tokens] x = x[:, self.num_prefix_tokens:] B = x.shape[0] L = x.shape[1] num_keep = max(1, int(L * (1. - self.prob))) keep_indices = torch.argsort(torch.randn(B, L, device=x.device), dim=-1)[:, :num_keep] # Le seguenti tre linee sono state modificate rispetto all'originale # per utilizzare l'indicizzazione di PyTorch anziché torch.gather stride = L * torch.unsqueeze(torch.arange(B, device=x.device), 1) keep_indices = (stride + keep_indices).flatten() x = x.reshape(B * L, -1)[keep_indices].view(B, num_keep, -1) x = torch.cat((prefix_tokens, x), dim=1) return xmodel.patch_drop = MyPatchDropout( prob = model.patch_drop.prob, num_prefix_tokens = model.patch_drop.num_prefix_tokens)Nell’immagine sottostante catturiamo la vista traccia seguendo il cambio sopra:
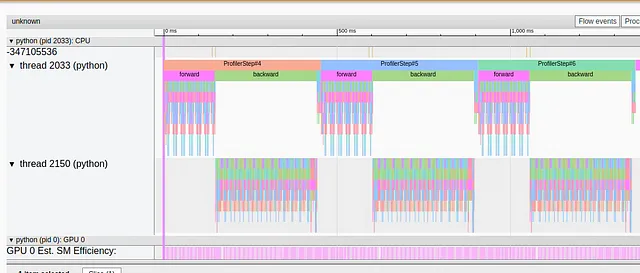
Possiamo chiaramente vedere che l’evento di sincronizzazione lungo non è più presente.
Nel caso del nostro modello di esempio, abbiamo avuto la fortuna che il modo in cui l’operazione torch.gather è stata utilizzata ha permesso di sostituirla con l’indicizzazione di PyTorch. Naturalmente, questo non è sempre il caso; altri utilizzi di torch.gather potrebbero non avere un’implementazione equivalente basata sull’indicizzazione.
Risultati
Nella tabella sottostante confrontiamo i risultati delle prestazioni ottenute allenando il nostro modello di prova in diversi scenari:
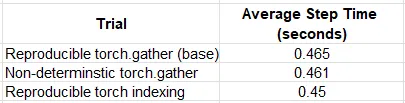
Nel caso del nostro esempio di prova, l’ottimizzazione ha avuto un impatto modesto, sebbene misurabile, con un aumento delle prestazioni del ~2%. Curiosamente, l’indicizzazione di torch in modalità riproducibile ha funzionato meglio rispetto alla funzione predefinita (non deterministica) torch.gather. Sulla base di questi risultati, potrebbe essere una buona idea valutare l’opzione di utilizzare l’indicizzazione anziché torch.gather, quando possibile.
Sommario
Nonostante la (giustificata) reputazione di PyTorch per essere facile da debuggare e tracciare, torch.autograd rimane un po’ un enigma e analizzare il passaggio di retropropagazione di un passaggio di allenamento può essere piuttosto difficile. Per affrontare questa sfida, PyTorch include il supporto per l’inserimento di hook in diverse fasi della propagazione all’indietro. In questo post, abbiamo mostrato come gli hook all’indietro di PyTorch, insieme a torch.profiler.record_function, possano essere utilizzati in un processo iterativo per identificare la fonte dei problemi di prestazioni nel passaggio all’indietro. Abbiamo applicato questa tecnica a un semplice modello ViT e abbiamo imparato alcune delle sfumature dell’operazione torch.gather.
In questo post abbiamo affrontato un tipo molto specifico di collo di bottiglia delle prestazioni. Assicurati di controllare i nostri altri post su VoAGI che coprono una vasta gamma di argomenti relativi all’analisi delle prestazioni e all’ottimizzazione delle prestazioni dei carichi di lavoro di apprendimento automatico.






