Allenare e distribuire modelli di apprendimento automatico in un ambiente multicloud utilizzando Amazon SageMaker
Allenare e distribuire modelli di apprendimento automatico su multicloud con Amazon SageMaker
Alla luce dell’accelerazione dei clienti nella migrazione verso il cloud e nella trasformazione delle loro attività, alcuni si trovano nella situazione di dover gestire le operazioni IT in un ambiente multicloud. Ad esempio, potresti aver acquisito un’azienda che era già in esecuzione su un provider cloud diverso, oppure potresti avere un carico di lavoro che genera valore dalle capacità uniche fornite da AWS. Un altro esempio sono i fornitori indipendenti di software (ISV) che rendono i loro prodotti e servizi disponibili su diverse piattaforme cloud per beneficiare dei loro clienti finali. Oppure un’organizzazione potrebbe operare in una regione in cui un provider cloud primario non è disponibile e, per soddisfare i requisiti di sovranità dei dati o di residenza dei dati, può utilizzare un provider cloud secondario.
In questi scenari, mentre inizi ad abbracciare l’IA generativa, i modelli di linguaggio di grandi dimensioni (LLM) e le tecnologie di machine learning (ML) come parte centrale della tua attività, potresti essere alla ricerca di opzioni per sfruttare le capacità di AI e ML di AWS al di fuori di AWS in un ambiente multicloud. Ad esempio, potresti voler utilizzare Amazon SageMaker per creare e allenare modelli di ML, oppure utilizzare Amazon SageMaker Jumpstart per distribuire modelli pre-costruiti di fondamentali o di terze parti, che puoi distribuire con pochi clic. Oppure potresti voler sfruttare Amazon Bedrock per costruire e scalare applicazioni di IA generativa, o puoi sfruttare i servizi AI pre-allenati di AWS, che non richiedono di imparare competenze di machine learning. AWS fornisce supporto per scenari in cui le organizzazioni desiderano portare il proprio modello in Amazon SageMaker o in Amazon SageMaker Canvas per le previsioni.
In questo post, dimostriamo una delle molte opzioni che hai per sfruttare le capacità di AI/ML più ampie e profonde di AWS in un ambiente multicloud. Mostriamo come puoi creare e allenare un modello di ML in AWS e distribuirlo su un’altra piattaforma. Alleniamo il modello utilizzando Amazon SageMaker, memorizziamo gli artefatti del modello in Amazon Simple Storage Service (Amazon S3) e distribuiamo ed eseguiamo il modello in Azure. Questo approccio è vantaggioso se utilizzi i servizi AWS per ML per la sua serie più completa di funzionalità, ma hai bisogno di eseguire il tuo modello su un altro provider cloud in una delle situazioni che abbiamo discusso.
Concetti chiave
Amazon SageMaker Studio è un ambiente di sviluppo integrato (IDE) basato sul web per il machine learning. SageMaker Studio consente ai data scientist, agli ingegneri di ML e agli ingegneri dei dati di preparare i dati, creare, allenare e distribuire modelli di ML su un’unica interfaccia web. Con SageMaker Studio, puoi accedere a strumenti specifici per ogni fase del ciclo di sviluppo di ML, dalla preparazione dei dati alla creazione, all’allenamento e alla distribuzione dei tuoi modelli di ML, migliorando la produttività del team di data science fino a dieci volte. I notebook di SageMaker Studio sono notebook di avvio rapido e collaborativi che si integrano con strumenti di ML specifici in SageMaker e altri servizi AWS.
- Incredibilmente virtuale Mercedes-Benz prepara il suo sistema di produzione digitale per la piattaforma di prossima generazione con NVIDIA Omniverse, MB.OS e l’IA generativa.
- Promemoria di metà viaggio di Kick Ass con Poe
- Compagnia di auto senza conducente utilizza chatbot per rendere i suoi veicoli più intelligenti
SageMaker è un servizio ML completo che consente agli analisti aziendali, ai data scientist e agli ingegneri MLOps di creare, allenare e distribuire modelli di ML per qualsiasi caso d’uso, indipendentemente dall’esperienza in ML.
AWS fornisce contenitori di deep learning (DLC) per i framework di ML popolari come PyTorch, TensorFlow e Apache MXNet, che puoi utilizzare con SageMaker per l’allenamento e l’inferenza. I DLC sono disponibili come immagini Docker in Amazon Elastic Container Registry (Amazon ECR). Le immagini Docker sono preinstallate e testate con le ultime versioni dei popolari framework di deep learning, così come con altre dipendenze necessarie per l’allenamento e l’inferenza. Per un elenco completo delle immagini Docker pre-costruite gestite da SageMaker, consulta i Percorsi del Registro Docker e il Codice di Esempio. Amazon ECR supporta la scansione della sicurezza ed è integrato con il servizio di gestione delle vulnerabilità di Amazon Inspector per soddisfare i requisiti di conformità di sicurezza delle immagini della tua organizzazione e per automatizzare la scansione delle valutazioni delle vulnerabilità. Le organizzazioni possono anche utilizzare AWS Trainium e AWS Inferentia per una migliore prestazione-prezzo per l’esecuzione di lavori di allenamento o di inferenza di ML.
Panoramica della soluzione
In questa sezione, descriviamo come creare e allenare un modello utilizzando SageMaker e distribuire il modello su Azure Functions. Utilizziamo un notebook di SageMaker Studio per creare, allenare e distribuire il modello. Alleniamo il modello in SageMaker utilizzando un’immagine Docker pre-costruita per PyTorch. Anche se in questo caso stiamo distribuendo il modello allenato su Azure, potresti utilizzare lo stesso approccio per distribuire il modello su altre piattaforme come on-premises o altre piattaforme cloud.
Quando creiamo un lavoro di allenamento, SageMaker avvia le istanze di calcolo di ML e utilizza il nostro codice di allenamento e il dataset di allenamento per allenare il modello. Salva gli artefatti del modello risultante e altri output in un bucket S3 che specifichiamo come input per il lavoro di allenamento. Quando l’allenamento del modello è completo, utilizziamo la libreria di runtime Open Neural Network Exchange (ONNX) per esportare il modello PyTorch come modello ONNX.
Infine, distribuiamo il modello ONNX insieme a un codice di inferenza personalizzato scritto in Python su Azure Functions utilizzando Azure CLI. ONNX supporta la maggior parte dei framework e degli strumenti di ML comunemente utilizzati. Da notare è che la conversione di un modello di ML in ONNX è utile se si desidera utilizzare un diverso framework di distribuzione di destinazione, come PyTorch a TensorFlow. Se si utilizza lo stesso framework sia nella sorgente che nella destinazione, non è necessario convertire il modello nel formato ONNX.
Il seguente diagramma illustra l’architettura di questo approccio.
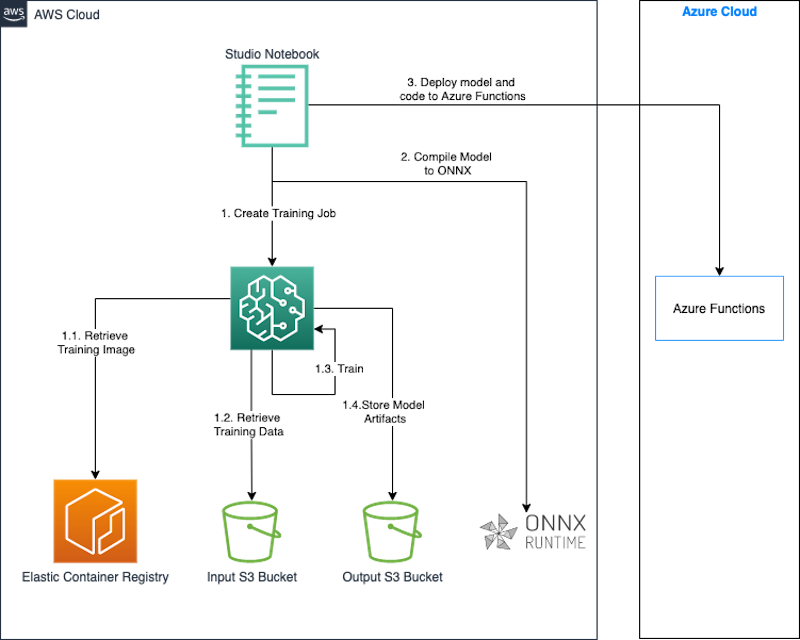
Utilizziamo un notebook SageMaker Studio insieme al SageMaker Python SDK per costruire e addestrare il nostro modello. Il SageMaker Python SDK è una libreria open-source per l’addestramento e il rilascio di modelli di machine learning su SageMaker. Per ulteriori dettagli, fare riferimento a Crea o apri un notebook di Amazon SageMaker Studio.
I frammenti di codice nelle sezioni seguenti sono stati testati nell’ambiente del notebook SageMaker Studio utilizzando l’immagine Data Science 3.0 e il kernel Python 3.0.
In questa soluzione, dimostriamo i seguenti passaggi:
- Addestrare un modello PyTorch.
- Esportare il modello PyTorch come modello ONNX.
- Confezionare il modello e il codice di inferenza.
- Effettuare il rilascio del modello su Azure Functions.
Prerequisiti
Dovresti avere i seguenti prerequisiti:
- Un account AWS.
- Un dominio SageMaker e un utente SageMaker Studio. Per istruzioni su come crearli, fare riferimento a Onboard to Amazon SageMaker Domain Using Quick setup.
- Azure CLI.
- Accesso ad Azure e credenziali per un service principal che abbia le autorizzazioni per creare e gestire Azure Functions.
Addestrare un modello con PyTorch
In questa sezione, illustriamo i passaggi per addestrare un modello PyTorch.
Installare le dipendenze
Installare le librerie necessarie per eseguire i passaggi richiesti per l’addestramento e il rilascio del modello:
pip install torchvision onnx onnxruntimeCompleta la configurazione iniziale
Iniziamo importando l’SDK AWS per Python (Boto3) e il SageMaker Python SDK. Come parte della configurazione, definiamo quanto segue:
- Un oggetto sessione che fornisce metodi di comodità all’interno del contesto di SageMaker e del nostro account.
- Un ARN del ruolo SageMaker utilizzato per delegare le autorizzazioni al servizio di addestramento e di hosting. Ne abbiamo bisogno affinché questi servizi possano accedere ai bucket S3 in cui sono archiviati i nostri dati e il modello. Per istruzioni su come creare un ruolo che soddisfi le esigenze aziendali, fare riferimento a SageMaker Roles. Per questo post, utilizziamo lo stesso ruolo di esecuzione della nostra istanza di notebook di Studio. Otteniamo questo ruolo chiamando
sagemaker.get_execution_role(). - La regione predefinita in cui verrà eseguito il nostro lavoro di addestramento.
- Il bucket predefinito e il prefisso che utilizziamo per archiviare l’output del modello.
Vedere il codice seguente:
import sagemaker
import boto3
import os
execution_role = sagemaker.get_execution_role()
region = boto3.Session().region_name
session = sagemaker.Session()
bucket = session.default_bucket()
prefix = "sagemaker/mnist-pytorch"Creare il dataset di addestramento
Utilizziamo il dataset disponibile nel bucket pubblico sagemaker-example-files-prod-{region}. Il dataset contiene i seguenti file:
- train-images-idx3-ubyte.gz – Contiene le immagini del set di addestramento
- train-labels-idx1-ubyte.gz – Contiene le etichette del set di addestramento
- t10k-images-idx3-ubyte.gz – Contiene le immagini del set di test
- t10k-labels-idx1-ubyte.gz – Contiene le etichette del set di test
Utilizziamo il modulotorchvision.datasets per scaricare i dati dal bucket pubblico localmente prima di caricarli nel nostro bucket dei dati di addestramento. Passiamo questa posizione del bucket come input al lavoro di addestramento di SageMaker. Lo script di addestramento utilizza questa posizione per scaricare e preparare i dati di addestramento, e quindi addestrare il modello. Vedere il codice seguente:
MNIST.mirrors = [
f"https://sagemaker-example-files-prod-{region}.s3.amazonaws.com/datasets/image/MNIST/"
]
MNIST(
"data",
download=True,
transform=transforms.Compose(
[transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))]
),
)Creare lo script di addestramento
Con SageMaker, è possibile utilizzare la modalità script per utilizzare un proprio modello. Con la modalità script, è possibile utilizzare i container predefiniti di SageMaker e fornire il proprio script di addestramento, che contiene la definizione del modello, insieme a eventuali librerie personalizzate e dipendenze. Il SDK Python di SageMaker passa il nostro script come entry_point al container, che carica ed esegue la funzione di addestramento dallo script fornito per addestrare il nostro modello.
Una volta completato l’addestramento, SageMaker salva l’output del modello nel bucket S3 che abbiamo fornito come parametro per il lavoro di addestramento.
Il nostro codice di addestramento è adattato dal seguente script di esempio PyTorch. Il seguente estratto di codice mostra la definizione del modello e la funzione di addestramento:
# definizione della rete
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 32, 3, 1)
self.conv2 = nn.Conv2d(32, 64, 3, 1)
self.dropout1 = nn.Dropout(0.25)
self.dropout2 = nn.Dropout(0.5)
self.fc1 = nn.Linear(9216, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = self.conv2(x)
x = F.relu(x)
x = F.max_pool2d(x, 2)
x = self.dropout1(x)
x = torch.flatten(x, 1)
x = self.fc1(x)
x = F.relu(x)
x = self.dropout2(x)
x = self.fc2(x)
output = F.log_softmax(x, dim=1)
return output
# addestramento
def train(args, model, device, train_loader, optimizer, epoch):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
if batch_idx % args.log_interval == 0:
print('Epoca di addestramento: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
if args.dry_run:
breakAddestrare il modello
Ora che abbiamo impostato il nostro ambiente e creato il nostro set di dati di input e lo script di addestramento personalizzato, possiamo avviare l’addestramento del modello utilizzando SageMaker. Utilizziamo il costruttore PyTorch nel SDK Python di SageMaker per avviare un lavoro di addestramento su SageMaker. Passiamo i parametri richiesti al costruttore e chiamiamo il metodo fit. Quando chiamiamo fit sul costruttore PyTorch, SageMaker avvia un lavoro di addestramento utilizzando il nostro script come codice di addestramento:
from sagemaker.pytorch import PyTorch
output_location = f"s3://{bucket}/{prefix}/output"
print(f"gli artefatti di addestramento verranno caricati in: {output_location}")
hyperparameters={
"batch-size": 100,
"epochs": 1,
"lr": 0.1,
"gamma": 0.9,
"log-interval": 100
}
instance_type = "ml.c4.xlarge"
estimator = PyTorch(
entry_point="train.py",
source_dir="code", # directory del tuo script di addestramento
role=execution_role,
framework_version="1.13",
py_version="py39",
instance_type=instance_type,
instance_count=1,
volume_size=250,
output_path=output_location,
hyperparameters=hyperparameters
)
estimator.fit(inputs = {
'training': f"{inputs}",
'testing': f"{inputs}"
})Esportare il modello addestrato come modello ONNX
Dopo che l’addestramento è completo e il nostro modello è salvato nella posizione predefinita in Amazon S3, esportiamo il modello come modello ONNX utilizzando l’ONNX runtime.
Includiamo il codice per esportare il nostro modello in ONNX nel nostro script di addestramento da eseguire dopo che l’addestramento è completo.
PyTorch esporta il modello in ONNX eseguendo il modello utilizzando l’input e registrando una traccia degli operatori utilizzati per calcolare l’output. Utilizziamo un input casuale del tipo corretto con la funzione torch.onnx.export di PyTorch per esportare il modello in ONNX. Specifichiamo anche la prima dimensione del nostro input come dinamica in modo che il nostro modello accetti un batch_size variabile di input durante l’inferenza.
def export_to_onnx(model, model_dir, device):
logger.info("Esportazione del modello in formato ONNX.")
dummy_input = torch.randn(1, 1, 28, 28).to(device)
input_names = [ "input_0" ]
output_names = [ "output_0" ]
path = os.path.join(model_dir, 'mnist-pytorch.onnx')
torch.onnx.export(model, dummy_input, path, verbose=True, input_names=input_names, output_names=output_names,
dynamic_axes={'input_0' : {0 : 'batch_size'}, # assi di lunghezza variabile
'output_0' : {0 : 'batch_size'}})ONNX è un formato standard aperto per i modelli di deep learning che consente l’interoperabilità tra framework di deep learning come PyTorch, Microsoft Cognitive Toolkit (CNTK) e altri. Ciò significa che è possibile utilizzare uno di questi framework per addestrare il modello e successivamente esportare i modelli pre-addestrati in formato ONNX. Esportando il modello in ONNX, si ottiene il vantaggio di una selezione più ampia di dispositivi e piattaforme di distribuzione.
Scaricare ed estrarre i file del modello
Il modello ONNX che il nostro script di addestramento ha salvato è stato copiato da SageMaker su Amazon S3 nella posizione di output che abbiamo specificato quando abbiamo avviato il lavoro di addestramento. I file del modello sono archiviati come un file di archivio compresso chiamato model.tar.gz. Scarichiamo questo file di archivio in una directory locale nel nostro ambiente di lavoro di Studio e estraiamo i file del modello, ovvero il modello ONNX.
import tarfile
local_model_file = 'model.tar.gz'
model_bucket,model_key = estimator.model_data.split('/',2)[-1].split('/',1)
s3 = boto3.client("s3")
s3.download_file(model_bucket,model_key,local_model_file)
model_tar = tarfile.open(local_model_file)
model_file_name = model_tar.next().name
model_tar.extractall('.')
model_tar.close()Validare il modello ONNX
Il modello ONNX viene esportato in un file chiamato mnist-pytorch.onnx dal nostro script di addestramento. Dopo aver scaricato ed estratto questo file, possiamo opzionalmente validare il modello ONNX utilizzando il modulo onnx.checker. La funzione check_model in questo modulo verifica la coerenza di un modello. Viene generata un’eccezione se il test non riesce.
import onnx
onnx_model = onnx.load("mnist-pytorch.onnx")
onnx.checker.check_model(onnx_model)Raggruppare il modello e il codice di inferenza
In questo post, utilizziamo il deployment .zip per Azure Functions. In questo metodo, raggruppiamo il nostro modello, il codice di supporto e le impostazioni di Azure Functions in un file .zip e lo pubblichiamo su Azure Functions. Il codice seguente mostra la struttura delle directory del nostro pacchetto di deploy:
mnist-onnx ├── function_app.py ├── model │ └── mnist-pytorch.onnx └── requirements.txt
Elencare le dipendenze
Elenchiamo le dipendenze per il nostro codice di inferenza nel file requirements.txt nella radice del nostro pacchetto. Questo file viene utilizzato per creare l’ambiente di Azure Functions quando pubblichiamo il pacchetto.
azure-functions numpy onnxruntime
Scrivere il codice di inferenza
Utilizziamo Python per scrivere il seguente codice di inferenza, utilizzando la libreria ONNX Runtime per caricare il nostro modello ed eseguire l’inferenza. Questo istruisce l’app di Azure Functions a rendere l’endpoint disponibile nel percorso relativo /classify.
import logging
import azure.functions as func
import numpy as np
import os
import onnxruntime as ort
import json
app = func.FunctionApp()
def preprocess(input_data_json):
# convertire i dati JSON nel tensore di input
return np.array(input_data_json['data']).astype('float32')
def run_model(model_path, req_body):
session = ort.InferenceSession(model_path)
input_data = preprocess(req_body)
logging.info(f"La forma dei dati di input è {input_data.shape}.")
input_name = session.get_inputs()[0].name # ottenere l'id del primo input del modello
try:
result = session.run([], {input_name: input_data})
except (RuntimeError) as e:
print("Forma={0} e errore={1}".format(input_data.shape, e))
return result[0]
def get_model_path():
d=os.path.dirname(os.path.abspath(__file__))
return os.path.join(d , './model/mnist-pytorch.onnx')
@app.function_name(name="mnist_classify")
@app.route(route="classify", auth_level=func.AuthLevel.ANONYMOUS)
def main(req: func.HttpRequest) -> func.HttpResponse:
logging.info('La funzione Python HTTP trigger ha elaborato una richiesta.')
# Ottenere il valore dell'immagine dal post.
try:
req_body = req.get_json()
except ValueError:
pass
if req_body:
# eseguire il modello
result = run_model(get_model_path(), req_body)
# mappare l'output a un intero e restituire una stringa di risultato.
digits = np.argmax(result, axis=1)
logging.info(type(digits))
return func.HttpResponse(json.dumps({"digits": np.array(digits).tolist()}))
else:
return func.HttpResponse(
"Questa funzione attivata da HTTP è stata eseguita correttamente.",
status_code=200
)Deployare il modello su Azure Functions
Ora che abbiamo il codice confezionato nel formato .zip richiesto, siamo pronti per pubblicarlo su Azure Functions. Lo faremo utilizzando Azure CLI, un’utilità a riga di comando per creare e gestire le risorse di Azure. Installa Azure CLI con il seguente codice:
!pip install -q azure-cliSuccessivamente, segui i seguenti passaggi:
-
Esegui l’accesso ad Azure:
!az login -
Configura i parametri di creazione delle risorse:
import random random_suffix = str(random.randint(10000,99999)) resource_group_name = f"multicloud-{random_suffix}-rg" storage_account_name = f"multicloud{random_suffix}" location = "ukwest" sku_storage = "Standard_LRS" functions_version = "4" python_version = "3.9" function_app = f"multicloud-mnist-{random_suffix}" -
Utilizza i seguenti comandi per creare l’app Azure Functions insieme alle risorse necessarie:
!az group create --name {resource_group_name} --location {location} !az storage account create --name {storage_account_name} --resource-group {resource_group_name} --location {location} --sku {sku_storage} !az functionapp create --name {function_app} --resource-group {resource_group_name} --storage-account {storage_account_name} --consumption-plan-location "{location}" --os-type Linux --runtime python --runtime-version {python_version} --functions-version {functions_version} -
Configura Azure Functions in modo che, durante la distribuzione del pacchetto delle funzioni, il file
requirements.txtvenga utilizzato per creare le dipendenze dell’applicazione:!az functionapp config appsettings set --name {function_app} --resource-group {resource_group_name} --settings @./functionapp/settings.json -
Configura l’app Functions per eseguire il modello Python v2 e eseguire una build sul codice ricevuto dopo la distribuzione .zip:
{ "AzureWebJobsFeatureFlags": "EnableWorkerIndexing", "SCM_DO_BUILD_DURING_DEPLOYMENT": true } -
Dopo aver configurato il gruppo di risorse, il contenitore di archiviazione e l’app Functions con la configurazione corretta, pubblica il codice nell’app Functions:
!az functionapp deployment source config-zip -g {resource_group_name} -n {function_app} --src {function_archive} --build-remote true
Testare il modello
Abbiamo distribuito il modello di machine learning su Azure Functions come trigger HTTP, il che significa che possiamo utilizzare l’URL dell’app Functions per inviare una richiesta HTTP alla funzione per invocarla ed eseguire il modello.
Per preparare l’input, scarica i file delle immagini di test dal bucket degli esempi di SageMaker e prepara un set di campioni nel formato richiesto dal modello:
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
import matplotlib.pyplot as plt
transform=transforms.Compose(
[transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))]
)
test_dataset = datasets.MNIST(root='../data', download=True, train=False, transform=transform)
test_loader = DataLoader(test_dataset, batch_size=16, shuffle=True)
test_features, test_labels = next(iter(test_loader))Utilizza la libreria requests per inviare una richiesta post all’endpoint di inferenza con gli input di esempio. L’endpoint di inferenza ha il formato mostrato nel seguente codice:
import requests, json
def to_numpy(tensor):
return tensor.detach().cpu().numpy() if tensor.requires_grad else tensor.cpu().numpy()
url = f"https://{function_app}.azurewebsites.net/api/classify"
response = requests.post(url,
json.dumps({"data":to_numpy(test_features).tolist()})
)
predictions = json.loads(response.text)['digits']Pulizia
Quando hai finito di testare il modello, elimina il gruppo di risorse insieme alle risorse contenute, inclusi il contenitore di archiviazione e l’app Functions:
!az group delete --name {resource_group_name} --yesInoltre, è consigliabile spegnere le risorse inutilizzate all’interno di SageMaker Studio per ridurre i costi. Per ulteriori informazioni, consulta Riduci i costi spegnendo automaticamente le risorse inutilizzate all’interno di Amazon SageMaker Studio.
Conclusion
In questo post, abbiamo mostrato come è possibile costruire e addestrare un modello di Machine Learning con SageMaker e distribuirlo su un altro provider cloud. Nella soluzione, abbiamo utilizzato un notebook di SageMaker Studio, ma per carichi di lavoro di produzione, consigliamo di utilizzare MLOps per creare flussi di lavoro di addestramento ripetibili al fine di accelerare lo sviluppo e la distribuzione del modello.
Questo post non ha mostrato tutte le possibili modalità per distribuire ed eseguire un modello in un ambiente multicloud. Ad esempio, è possibile anche confezionare il modello in un’immagine di container insieme al codice di inferenza e alle librerie di dipendenza per eseguire il modello come un’applicazione containerizzata su qualsiasi piattaforma. Per ulteriori informazioni su questo approccio, fare riferimento a Deploy delle applicazioni container in un ambiente multicloud utilizzando Amazon CodeCatalyst. L’intento del post è mostrare come le organizzazioni possano utilizzare le capacità di AI/ML di AWS in un ambiente multicloud.






