Una guida completa alle Reti Neurali Convoluzionali
A complete guide to Convolutional Neural Networks.
L’Intelligenza Artificiale sta assistendo ad una crescita monumentale nel colmare il divario tra le capacità degli esseri umani e quelle delle macchine. Ricercatori ed appassionati lavorano su numerosi aspetti del campo per fare cose straordinarie. Uno di questi campi è il dominio della Visione Artificiale.
L’Intelligenza Artificiale sta assistendo ad una crescita monumentale nel colmare il divario tra le capacità umane e quelle delle macchine. Ricercatori ed appassionati lavorano su numerosi aspetti del campo per realizzare cose incredibili. Uno di questi ambiti è il dominio della Visione Artificiale.
L’obiettivo di questo campo è di consentire alle macchine di vedere il mondo come lo vedono gli esseri umani, percepirlo in modo simile, e persino utilizzare le conoscenze per una moltitudine di compiti come il riconoscimento di immagini e video, l’analisi e la classificazione di immagini, la ricreazione di media, i sistemi di raccomandazione, l’elaborazione del linguaggio naturale, ecc. I progressi nella Visione Artificiale con il Deep Learning sono stati costruiti e perfezionati nel tempo, principalmente su un particolare algoritmo – una Convolutional Neural Network.
Introduzione

- Inferenza Variazionale Le Basi
- Ricerca di Similarità, Parte 3 Combinazione dell’Indice di File Invertito e della Quantizzazione del Prodotto
- Questo articolo mette alla prova il senso dell’umorismo di ChatGPT oltre il 90% delle battute generate da ChatGPT sono le stesse 25 battute.
Una Convolutional Neural Network (ConvNet/CNN) è un algoritmo di Deep Learning che può prendere in input un’immagine, assegnare importanza (pesi e bias apprendibili) a vari aspetti/oggetti nell’immagine, e essere in grado di differenziare uno dall’altro. Il pre-processing richiesto in un ConvNet è molto inferiore rispetto ad altri algoritmi di classificazione. Mentre nei metodi primitivi i filtri sono creati a mano, con sufficiente allenamento, i ConvNets hanno la capacità di apprendere questi filtri/caratteristiche.
L’architettura di un ConvNet è analoga al modello di connettività dei neuroni nel cervello umano ed è stata ispirata dall’organizzazione della corteccia visiva. I singoli neuroni rispondono agli stimoli solo in una regione ristretta del campo visivo noto come Campo Recettivo. Una collezione di tali campi si sovrappone per coprire l’intera area visiva.
Perché ConvNets rispetto alle Reti Neurali Feed-Forward?
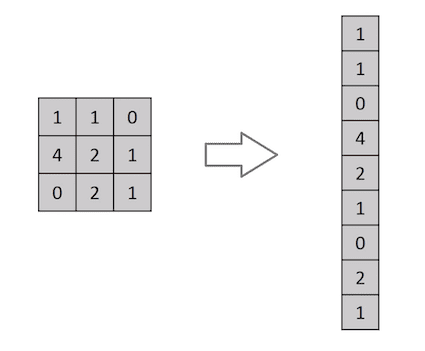
Un’immagine non è altro che una matrice di valori di pixel, giusto? Quindi perché non appiattire l’immagine (ad es. una matrice di immagine 3×3 in un vettore 9×1) e alimentarla ad un Perceptron Multilivello per scopi di classificazione? Uh.. non proprio.
In casi di immagini binarie estremamente semplici, il metodo potrebbe mostrare un punteggio di precisione medio durante la previsione delle classi, ma avrebbe poco o nessuna accuratezza quando si tratta di immagini complesse con dipendenze di pixel in tutto.
Un ConvNet è in grado di catturare con successo le dipendenze spaziali e temporali in un’immagine attraverso l’applicazione di filtri pertinenti. L’architettura esegue un fitting migliore al dataset dell’immagine grazie alla riduzione del numero di parametri coinvolti e alla riutilizzabilità dei pesi. In altre parole, la rete può essere addestrata per comprendere meglio la sofisticazione dell’immagine.
Immagine di Input
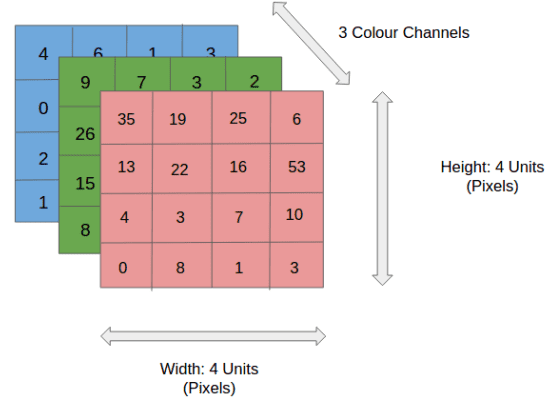
Nella figura, abbiamo un’immagine RGB che è stata separata dai suoi tre piani di colore – rosso, verde e blu. Ci sono diversi spazi di colore in cui le immagini esistono – scala di grigi, RGB, HSV, CMYK, ecc.
Potete immaginare quanto intensivo dal punto di vista computazionale diventerebbe una volta che le immagini raggiungono dimensioni, diciamo 8K (7680×4320). Il ruolo di ConvNet è quello di ridurre le immagini in una forma più facile da elaborare, senza perdere le caratteristiche che sono cruciali per ottenere una buona previsione. Questo è importante quando si progetta un’architettura che non solo è buona nell’apprendimento delle caratteristiche, ma anche scalabile per dataset massivi.
Livello di Convoluzione – Il Kernel

Dimensioni dell’immagine = 5 (Altezza) x 5 (Larghezza) x 1 (Numero di canali, ad es. RGB)
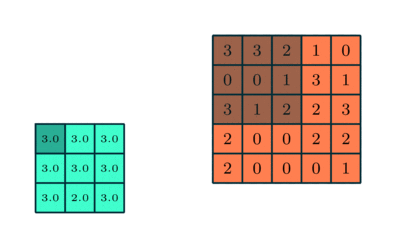
Nella dimostrazione precedente, la sezione verde assomiglia alla nostra immagine di input 5x5x1, I. L’elemento coinvolto nell’operazione di convoluzione nella prima parte di un livello di convoluzione è chiamato Kernel/Filtro, K, rappresentato in giallo. Abbiamo selezionato K come una matrice 3x3x1.
Kernel/Filtro, K =
1 0 1
0 1 0
1 0 1Il Kernel si sposta 9 volte a causa della Lunghezza di Passo = 1 (Non-Strided), ogni volta eseguendo un’operazione di moltiplicazione elemento per elemento (Prodotto di Hadamard) tra K e la porzione P dell’immagine su cui il kernel si sta soffermando.
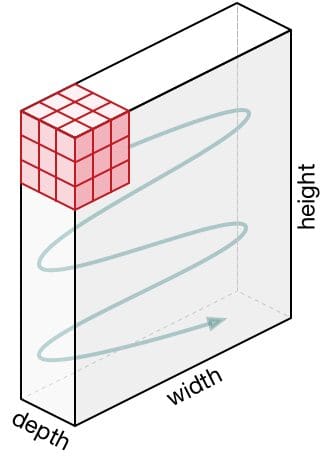
Il filtro si sposta verso destra con un certo valore di passo fino a quando analizza l’intera larghezza. Successivamente, salta all’inizio (a sinistra) dell’immagine con lo stesso valore di passo e ripete il processo fino a quando l’intera immagine viene attraversata.
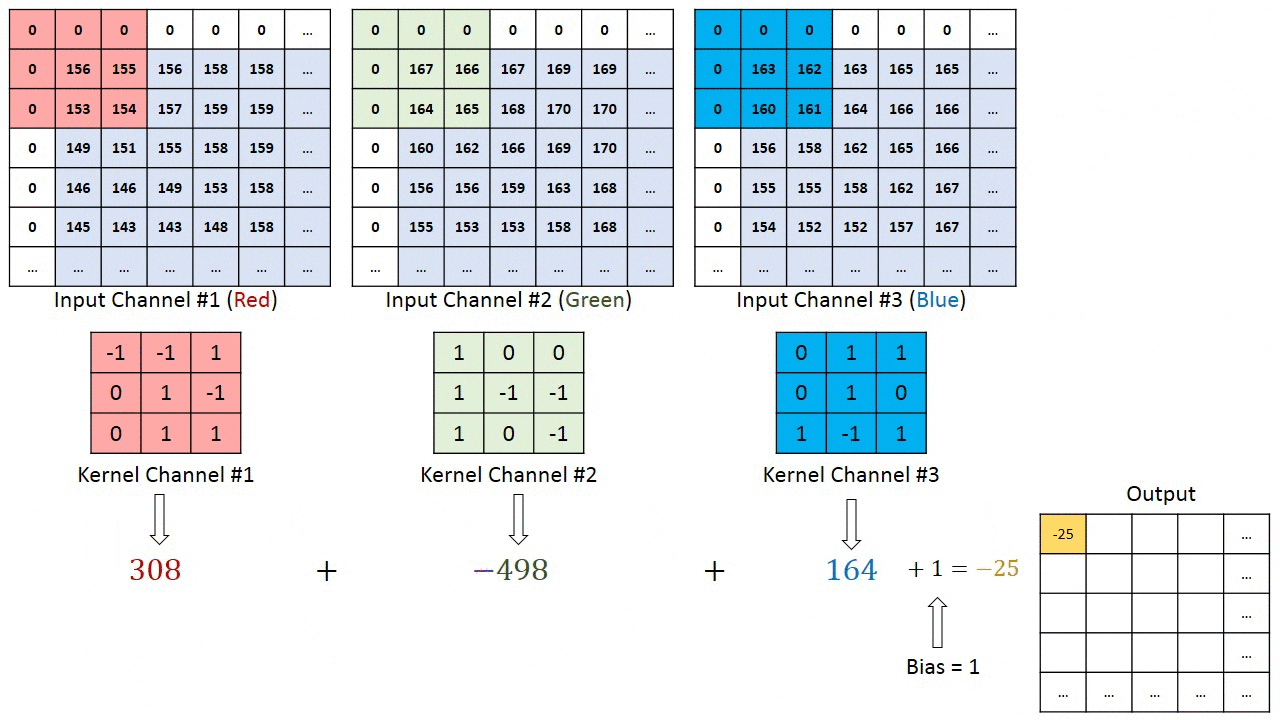
Nel caso di immagini con più canali (ad es. RGB), il Kernel ha la stessa profondità dell’immagine di input. Viene eseguita una moltiplicazione matriciale tra lo stack di Kn e In ([K1, I1]; [K2, I2]; [K3, I3]) e tutti i risultati vengono sommati al bias per darci un’uscita di funzionalità convoluta con un solo canale schiacciato.

L’obiettivo dell’Operazione di Convoluzione è quello di estrarre le caratteristiche di alto livello come i bordi, dall’immagine di input. Le ConvNets non devono essere limitate a un solo strato convoluzionale. Convenzionalmente, il primo strato convoluzionale è responsabile della cattura delle caratteristiche a basso livello come i margini, il colore, l’orientamento del gradiente, ecc. Con l’aggiunta di altri strati, l’architettura si adatta anche alle caratteristiche ad alto livello, dando come risultato una rete che ha una comprensione completa delle immagini nel dataset, simile alla nostra.
Ci sono due tipi di risultati dell’operazione: uno in cui la funzionalità convoluta è ridotta in dimensionalità rispetto all’input e l’altro in cui la dimensionalità è aumentata o rimane la stessa. Ciò avviene applicando Padding Valido nel primo caso o Padding Same nel secondo caso.
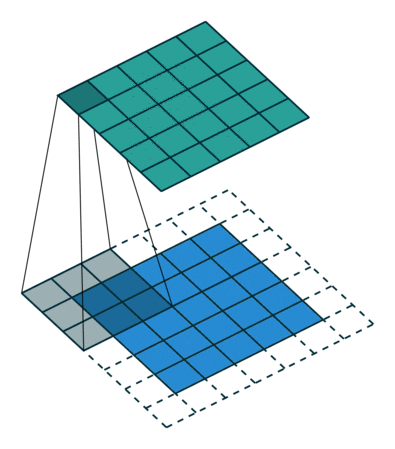
Quando aumentiamo l’immagine 5x5x1 in un’immagine 6x6x1 e poi applichiamo il kernel 3x3x1 su di essa, scopriamo che la matrice convoluta ha dimensioni 5x5x1. Da qui il nome: Padding Same.
D’altra parte, se eseguiamo la stessa operazione senza padding, ci viene presentata una matrice che ha le dimensioni del Kernel stesso (3x3x1) – Padding Valido.
Il seguente repository contiene molti GIF che ti aiuteranno a comprendere meglio come Padding e Lunghezza di Passo lavorano insieme per ottenere risultati pertinenti alle nostre esigenze.
[vdumoulin/conv_arithmetic
Un rapporto tecnico sull’aritmetica di convoluzione nel contesto dell’apprendimento profondo – vdumoulin/conv_arithmetic github.com]( https://github.com/vdumoulin/conv_arithmetic )
Livello di Pooling
Come per lo strato convoluzionale, il livello di Pooling è responsabile per la riduzione della dimensione spaziale della funzionalità convoluta. Questo è per ridurre la potenza di calcolo richiesta per elaborare i dati attraverso la riduzione della dimensionalità. Inoltre, è utile per estrarre le caratteristiche dominanti che sono invarianti alla rotazione e alla posizione, mantenendo così l’efficacia del processo di addestramento del modello.
Ci sono due tipi di Pooling: Max Pooling e Average Pooling. Max Pooling restituisce il valore massimo dalla porzione dell’immagine coperta dal kernel. D’altra parte, Average Pooling restituisce la media di tutti i valori dalla porzione dell’immagine coperta dal kernel.
Max Pooling funge anche da Soppressore di Rumore. Scarta completamente le attivazioni rumorose e svolge anche una funzione di denoising insieme alla riduzione della dimensionalità. D’altra parte, Average Pooling esegue semplicemente la riduzione della dimensionalità come meccanismo di soppressione del rumore. Possiamo quindi dire che Max Pooling funziona molto meglio di Average Pooling.
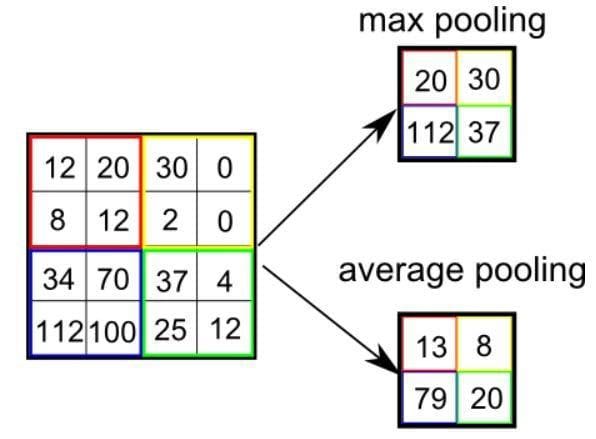 Tipi di Pooling
Tipi di Pooling
Il layer di Convoluzione e il layer di Pooling, insieme formano l’i-esimo layer di una Rete Neurale Convoluzionale. A seconda delle complessità delle immagini, il numero di questi layer può essere aumentato per catturare ulteriormente dettagli a basso livello, ma a discapito di una maggiore potenza di calcolo.
Dopo aver completato il processo sopra descritto, abbiamo reso possibile per il modello di comprendere le caratteristiche. Procediamo, quindi, schiacciando l’output finale e alimentando una normale Rete Neurale per scopi di classificazione.
Classificazione – Layer Completamente Connesso (FC Layer)
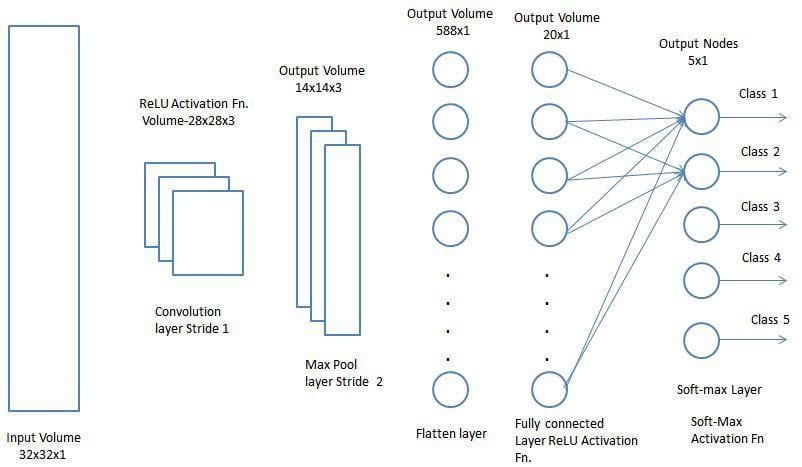
Aggiungere un layer completamente connesso è un modo (di solito) economico per apprendere combinazioni non lineari delle caratteristiche a livello elevato rappresentate dall’output del layer di convoluzione. Il layer completamente connesso sta apprendendo una funzione possibilmente non lineare in quello spazio.
Ora che abbiamo convertito la nostra immagine di input in una forma adatta per il nostro Percettrone Multilivello, schiacciamo l’immagine in un vettore di colonne. L’output schiacciato viene alimentato a una rete neurale feed-forward e il backpropagation viene applicato ad ogni iterazione di addestramento. Nel corso di una serie di epoche, il modello è in grado di distinguere tra le caratteristiche a basso livello dominanti e alcune altre caratteristiche nelle immagini e di classificarle utilizzando la tecnica di Classificazione Softmax.
Ci sono varie architetture di CNN disponibili che sono state fondamentali nella costruzione di algoritmi che alimentano e alimenteanno l’AI nel futuro prevedibile. Alcuni di essi sono elencati di seguito:
- LeNet
- AlexNet
- VGGNet
- GoogLeNet
- ResNet
- ZFNet
Sumit Saha è un data scientist e ingegnere di machine learning che attualmente lavora alla creazione di prodotti basati sull’AI. È appassionato dell’applicazione dell’AI per il bene sociale, in particolare nel campo della medicina e della sanità. Ogni tanto scrive anche dei post tecnici.
Originale. Ripubblicato con il permesso.





