Deep Learning per oggetti profondi ZoeDepth è un modello di intelligenza artificiale per la stima della profondità in multi-dominio.
ZoeDepth is an AI model for multi-domain depth estimation using Deep Learning.


Hai mai incontrato illusioni in cui un bambino nell’immagine sembra più alto e più grande di un adulto? L’illusione della stanza di Ames è famosa ed è basata su una stanza a forma di trapezio, con un angolo della stanza più vicino allo spettatore rispetto all’altro angolo. Quando la guardi da un certo punto di vista, gli oggetti nella stanza sembrano normali, ma quando ti sposti in una posizione diversa, tutto cambia in termini di dimensioni e forma, e può essere difficile capire cosa è vicino a te e cosa non lo è.
Tuttavia, questo è un problema per noi umani. Normalmente, quando guardiamo una scena, stimiamo abbastanza accuratamente la profondità degli oggetti se non ci sono trucchi di illusione. I computer, d’altra parte, non sono altrettanto bravi nella stima della profondità, poiché è ancora un problema fondamentale nella visione artificiale.
La stima della profondità è il processo di determinare la distanza tra la telecamera e gli oggetti nella scena. Gli algoritmi di stima della profondità prendono un’immagine o una sequenza di immagini in input e restituiscono una mappa di profondità corrispondente o una rappresentazione 3D della scena. Questa è un’attività importante poiché abbiamo bisogno di comprendere la profondità della scena in numerose applicazioni come la robotica, i veicoli autonomi, la realtà virtuale, la realtà aumentata, ecc. Ad esempio, se desideri avere un’auto a guida autonoma sicura, comprendere la distanza dalla macchina di fronte a te è fondamentale per regolare la velocità di guida.
- Utilizzare i grafici a raggi di sole di Plotly Express per esplorare i dati geologici
- FedML e Theta svelano il Supercluster AI decentralizzato Potenziamento dell’IA generativa e della raccomandazione di contenuti.
- Da SQL a Julia gli altri linguaggi di programmazione della Data Science
Ci sono due tipi di algoritmi di stima della profondità, la stima assoluta della profondità metrica (MDE), in cui l’obiettivo è stimare la distanza assoluta, e la stima relativa della profondità (RDE), in cui l’obiettivo è stimare la distanza relativa tra gli oggetti nella scena.

I modelli MDE sono utili per il mappaggio, la pianificazione, la navigazione, il riconoscimento degli oggetti, la ricostruzione 3D e l’editing delle immagini. Tuttavia, le prestazioni dei modelli MDE possono deteriorarsi quando si addestra un singolo modello su più dataset, specialmente se le immagini presentano grandi differenze nella scala di profondità (ad esempio, immagini al chiuso e all’aperto). Di conseguenza, i modelli MDE attuali spesso si adattano troppo specificamente a determinati dataset e non generalizzano bene su altri dataset.
I modelli RDE, d’altra parte, utilizzano la disparità come mezzo di supervisione. Le previsioni di profondità in RDE sono coerenti solo tra loro all’interno dei fotogrammi dell’immagine e il fattore di scala è sconosciuto. Ciò consente ai metodi RDE di essere addestrati su un insieme variegato di scene e dataset, inclusi anche i film 3D, il che può contribuire a migliorare la generalizzabilità del modello tra i domini. Tuttavia, il compromesso è che la profondità prevista in RDE non ha un significato metrico, il che limita le sue applicazioni.
Cosa succederebbe se combinassimo questi due approcci? Potremmo avere un modello di stima della profondità che si generalizza bene in diversi domini pur mantenendo una scala metrica accurata. Ecco esattamente ciò che ha realizzato ZoeDepth.
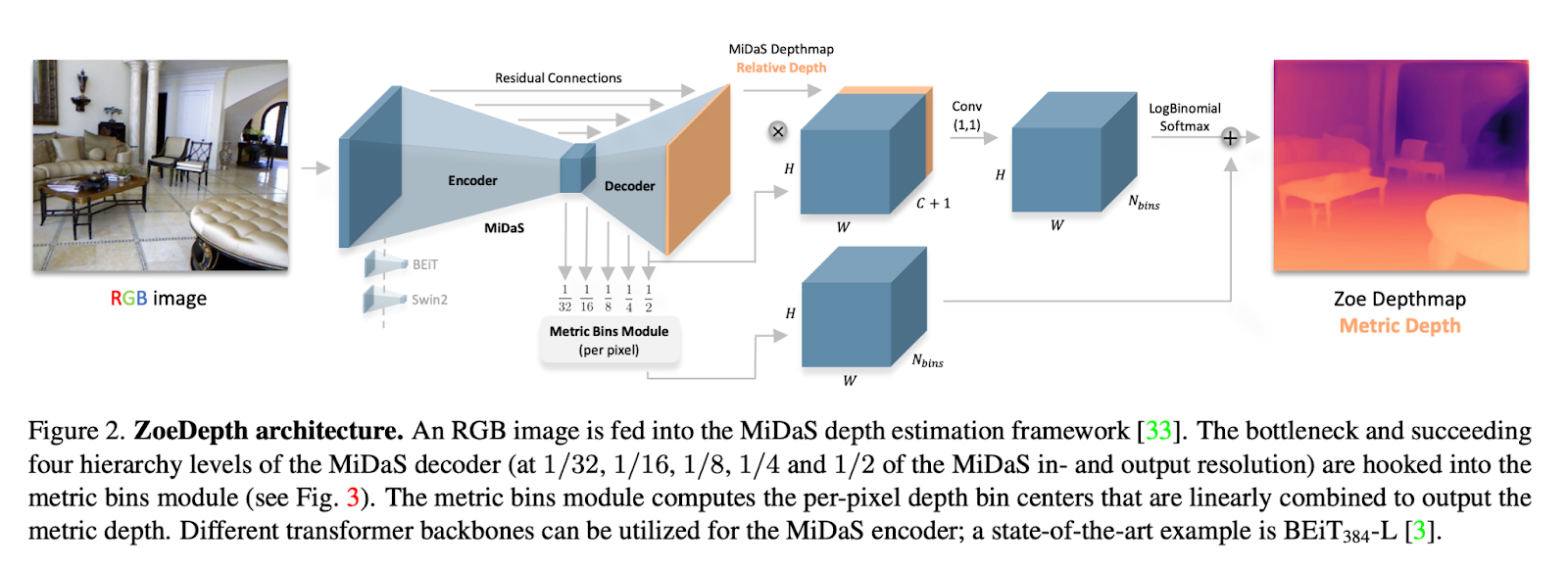
ZoeDepth è una struttura a due fasi che combina approcci MDE e RDE. La prima fase consiste in una struttura encoder-decoder che viene addestrata a stimare le profondità relative. Questo modello viene addestrato su una grande varietà di dataset che migliora la generalizzazione. La seconda fase aggiunge componenti responsabili della stima della profondità metrica come una testa aggiuntiva.
Il design della testa metrica utilizzato in questo approccio si basa su un metodo chiamato modulo metrico a bin, che stima un insieme di valori di profondità per ogni pixel anziché un singolo valore di profondità. Ciò consente al modello di catturare una gamma di possibili valori di profondità per ogni pixel, il che può contribuire a migliorare la sua precisione e robustezza. Ciò consente una misurazione accurata della profondità che tiene conto della distanza fisica tra gli oggetti nella scena. Queste teste vengono addestrate su dataset di profondità metrica e sono leggere rispetto alla prima fase.
Per quanto riguarda l’elaborazione, un modello di classificazione seleziona la testa appropriata per ogni immagine utilizzando le caratteristiche dell’encoder. Ciò consente al modello di specializzarsi nella stima della profondità per domini specifici o tipi di scene pur beneficiando del pre-addestramento sulla profondità relativa. Alla fine, otteniamo un modello flessibile che può essere utilizzato in molteplici configurazioni.





