Una mentalità MLOps sempre pronto per la produzione
MLOps mindset always production-ready
Il successo del machine learning (ML) in molti ambiti ha portato con sé una nuova serie di sfide, in particolare la necessità di addestrare ed valutare continuamente i modelli e di verificare continuamente lo scostamento dai dati di addestramento. L’integrazione e il rilascio continui (CI/CD) sono al centro di qualsiasi progetto di ingegneria del software di successo e sono spesso definiti come DevOps. DevOps aiuta a razionalizzare l’evoluzione del codice, consente vari framework di test e offre flessibilità per abilitare il rilascio selettivo su vari server di distribuzione (dev, staging, prod, ecc.).
Le nuove sfide legate al ML hanno ampliato il tradizionale ambito del CI/CD includendo anche ciò che oggi viene comunemente definito Continuous Training (CT), un termine introdotto per la prima volta da Google. Il continuous training richiede che i modelli di ML siano addestrati continuamente su nuovi set di dati e valutati per soddisfare le aspettative prima di essere distribuiti in produzione, oltre a consentire molte altre funzionalità specifiche del ML. Oggi, in un contesto di machine learning, DevOps sta diventando noto come MLOps e include CI, CT e CD.
Principi di MLOps
- Crescono le preoccupazioni sugli attacchi di bypass MFA
- Analisi geospaziale per la resilienza alle inondazioni
- Preparati e gioca ‘Remnant II’ di Gearbox in streaming su GeForce NOW
Tutto lo sviluppo di prodotti si basa su determinati principi e MLOps non fa eccezione. Ecco i tre principi più importanti di MLOps.
- Continuità: Il focus di MLOps dovrebbe essere sull’evoluzione, che si tratti di addestramento continuo, sviluppo continuo, integrazione continua o qualsiasi altra cosa che stia evolvendo/cambiando continuamente.
- Monitoraggio di tutto: Date le caratteristiche esplorative del ML, è necessario monitorare e raccogliere tutto ciò che accade, simile ai processi in un esperimento scientifico.
- Approccio a puzzle: Qualsiasi framework di MLOps dovrebbe supportare componenti plug-in. Tuttavia, è importante trovare il giusto equilibrio: troppa pluggabilità causa problemi di compatibilità, mentre troppa restrizione limita l’utilizzo.
Tenendo presenti questi principi, identifichiamo i requisiti chiave che governano un buon framework di MLOps.
Requisiti di MLOps
Come già accennato, il machine learning ha portato a nuovi e unici requisiti per le operazioni.
- Riproducibilità: Consentire agli esperimenti di ML di riprodurre gli stessi risultati in modo ripetuto per convalidare le prestazioni.
- Versionamento: Mantenere il versionamento da tutte le direzioni, inclusi: dati, codice, modelli e configurazioni. Un modo per eseguire il versionamento “data-model-code” è utilizzare strumenti di controllo versione come GitHub.
- Pipelining: Sebbene i flussi di lavoro basati su grafi aciclici diretti (DAG) siano spesso utilizzati in scenari non-ML (ad esempio, Airflow), il ML ha requisiti propri per il pipelining per consentire l’addestramento continuo. La riutilizzabilità dei componenti del flusso di lavoro per l’addestramento e la previsione garantisce coerenza nell’estrazione delle caratteristiche e riduce gli errori di elaborazione dei dati.
- Orchestrazione e distribuzione: L’addestramento dei modelli di ML richiede un framework distribuito di macchine che coinvolge le GPU e quindi l’esecuzione di un flusso di lavoro nel cloud è una parte intrinseca del ciclo di addestramento di ML. Il rilascio del modello in base a varie condizioni (metriche, ambiente, ecc.) comporta sfide uniche nel machine learning.
- Flessibilità: Consentire la flessibilità nella scelta delle fonti di dati, nella selezione di un provider di cloud e nella decisione su diversi strumenti (analisi dei dati, monitoraggio, framework di ML, ecc.). La flessibilità può essere ottenuta offrendo opzioni per plugin verso strumenti esterni e/o offrendo la capacità di definire componenti personalizzati. Un componente di orchestrazione e distribuzione flessibile garantisce l’esecuzione del flusso di lavoro indipendente dal cloud e il servizio di ML.
- Tracciamento degli esperimenti: Unico per il ML, l’esperimentazione è parte implicita di qualsiasi progetto. Dopo più round di sperimentazione (ad esempio, sperimentazione con l’architettura o gli iperparametri nell’architettura), un modello di ML diventa maturo. Mantenere un registro di ogni esperimento per future referenze è essenziale per il ML. Gli strumenti di tracciamento degli esperimenti possono essere utilizzati per garantire il versionamento del codice e del modello e strumenti come DVC garantiscono il versionamento del codice e dei dati.
Considerazioni pratiche
Nell’entusiasmo di creare modelli di ML, spesso si trascurano alcune specifiche di igiene del ML, come l’analisi iniziale dei dati o l’ottimizzazione degli iperparametri o il pre- / post-elaborazione. In molti casi, manca una mentalità di produzione ML fin dall’inizio del progetto, il che porta a sorprese (problemi di memoria, superamento del budget, ecc.) in fasi successive del progetto, soprattutto durante la produzione, con conseguente ri-modellazione e ritardo nel time-to-market. Ma utilizzando un framework di MLOps fin dall’inizio di un progetto ML si affrontano fin da subito le considerazioni di produzione e si impone un approccio sistematico alla risoluzione dei problemi di machine learning come l’analisi dei dati, il tracciamento degli esperimenti, ecc.
Un MLOps rende anche possibile essere pronti per la produzione in qualsiasi momento. Questo è spesso cruciale per le startup quando c’è la necessità di ridurre il time-to-market. Con MLOps che offre flessibilità in termini di orchestrazione e deployment, la prontezza per la produzione può essere raggiunta predefinendo orchestratori (ad esempio, azioni di GitHub) o deployer (ad esempio, MLflow, KServe, ecc.) che fanno parte della pipeline MLOps.
Framework esistenti per MLOps
I fornitori di servizi cloud come Google, Amazon, Azure forniscono i propri framework MLOps che possono essere utilizzati sulla propria piattaforma o come parte dei framework di machine learning esistenti (ad esempio, TFX pipelining come parte del framework Tensorflow). Questi framework MLOps sono facili da usare ed esaustivi nelle loro funzionalità.
L’utilizzo di un framework MLOps da parte di un fornitore di servizi cloud limita un’organizzazione nell’utilizzo di MLOps nel proprio ambiente. Per molte organizzazioni questo diventa una grande limitazione poiché l’uso dei servizi cloud dipende da ciò che desidera il cliente. In molti casi, è necessario un framework MLOps che fornisca flessibilità nella scelta di un provider cloud e al contempo offra la maggior parte delle funzionalità di MLOps.
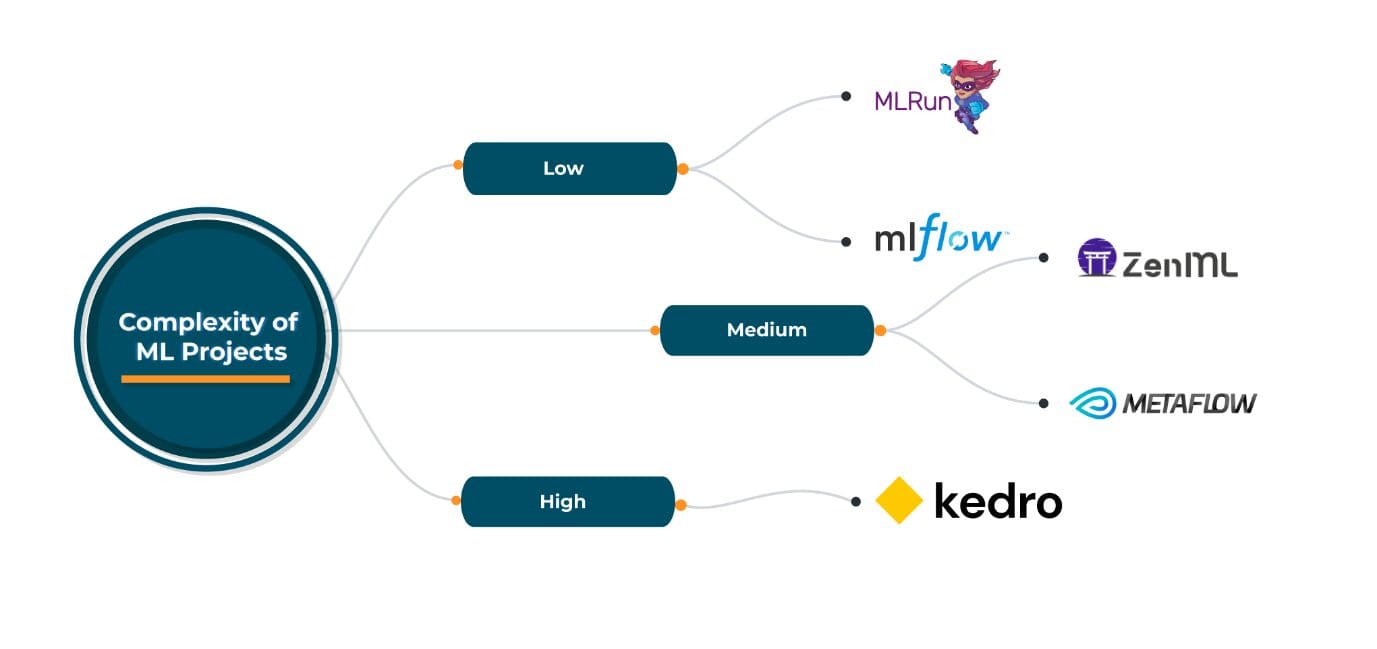
I framework MLOps open-source sono molto utili per questo tipo di scenario. ZenML, MLRun, Kedro, Metaflow sono alcuni dei framework MLOps open-source più conosciuti e ampiamente utilizzati, ognuno con i propri vantaggi e svantaggi. Tutti offrono una buona flessibilità nella scelta dei fornitori di servizi cloud, nell’orchestrazione/deployment e negli strumenti di machine learning come parte della loro pipeline. La scelta di uno di questi framework open-source dipende dalle specifiche esigenze di MLOps. Tuttavia, tutti questi framework sono sufficientemente generici da soddisfare una vasta gamma di requisiti.
In base all’esperienza con questi framework MLOps open-source nel loro stato attuale, raccomando quanto segue:
Adotta MLOps in Anticipo
MLOps è la prossima evoluzione di DevOps e sta unendo persone provenienti da diversi ambiti: data engineer, machine learning engineer, infrastructure engineer e altri ancora. In futuro possiamo aspettarci che MLOps diventi low-code, simile a quanto abbiamo visto in DevOps oggi. Le startup in particolare dovrebbero adottare MLOps nelle prime fasi di sviluppo per garantire un time-to-market più veloce oltre ai vantaggi che porta con sé. Abhishek Gupta è il Principal Data Scientist presso Talentica Software. Nel suo attuale ruolo, lavora a stretto contatto con diverse aziende per aiutarle con l’IA/ML per le loro linee di prodotti. Abhishek è un alunno dell’IISc Bangalore che lavora nell’ambito dell’IA/ML e dei big data da più di 7 anni. Ha numerosi brevetti e articoli in vari settori come reti di comunicazione e machine learning.






