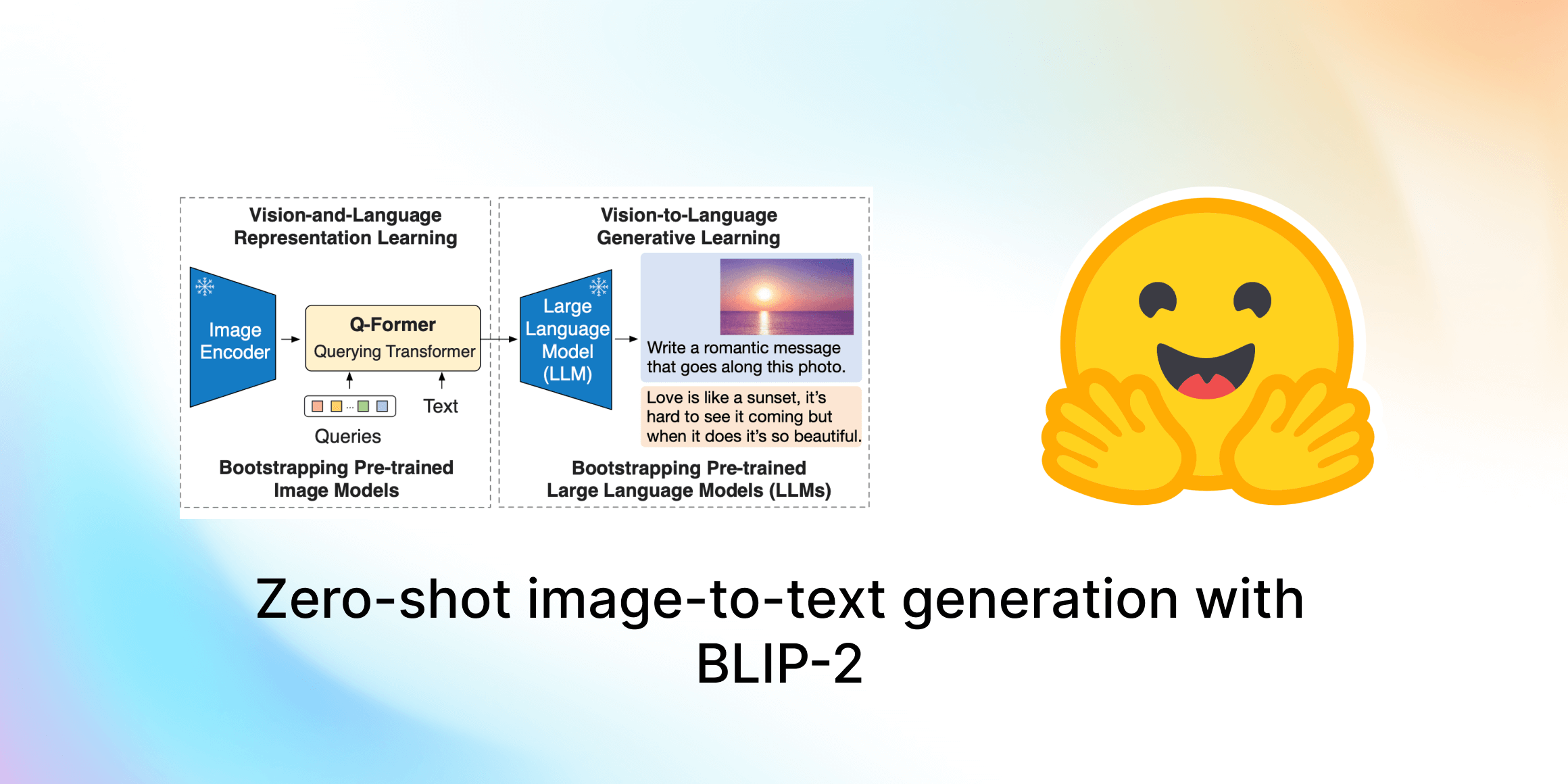
Un’immedesimazione nei modelli di visione-linguaggio
'Vision-language model immersion'
L’apprendimento umano è intrinsecamente multimodale poiché sfruttare congiuntamente più sensi ci aiuta a comprendere ed analizzare meglio le nuove informazioni. Non sorprende quindi che i recenti progressi nell’apprendimento multimodale si ispirino all’efficacia di questo processo per creare modelli in grado di elaborare e collegare informazioni utilizzando varie modalità come immagini, video, testo, audio, gesti del corpo, espressioni facciali e segnali fisiologici.
Dal 2021, abbiamo visto un crescente interesse per i modelli che combinano le modalità di visione e linguaggio (chiamati anche modelli di visione e linguaggio congiunti), come il CLIP di OpenAI. I modelli di visione e linguaggio congiunti hanno dimostrato capacità particolarmente impressionanti in compiti molto sfidanti come la descrizione delle immagini, la generazione e la manipolazione di immagini guidate dal testo e la risposta alle domande visive. Questo campo continua a evolversi, così come la sua efficacia nel migliorare la generalizzazione a zero-shot, portando a vari casi d’uso pratici.
In questo post del blog, presenteremo i modelli di visione e linguaggio congiunti concentrandoci su come vengono addestrati. Mostreremo anche come puoi sfruttare 🤗 Transformers per sperimentare gli ultimi progressi in questo ambito.
Indice
- Introduzione
- Strategie di Apprendimento
- Apprendimento Contrastivo
- PrefixLM
- Fusione Multi-modale con Attenzione Incrociata
- MLM / ITM
- Nessun Addestramento
- Insiemi di dati
- Supporto ai Modelli di Visione e Linguaggio in 🤗 Transformers
- Aree Emergenti di Ricerca
- Conclusioni
Introduzione
Cosa significa chiamare un modello un “modello di visione e linguaggio”? Un modello che combina entrambe le modalità di visione e linguaggio? Ma cosa significa esattamente?
- Accelerazione dei trasformatori PyTorch con Intel Sapphire Rapids – parte 2
- Presentiamo ⚔️ AI vs. AI ⚔️ un sistema di competizione di apprendimento profondo di rinforzo multi-agente.
- Generazione di storie AI per lo sviluppo di giochi #5
Una caratteristica che aiuta a definire questi modelli è la loro capacità di elaborare sia immagini (visione) che testo linguistico naturale (linguaggio). Questo processo dipende dagli input, gli output e il compito che viene richiesto a questi modelli di eseguire.
Prendiamo ad esempio il compito della classificazione delle immagini a zero-shot. Passeremo un’immagine e alcuni prompt in questo modo per ottenere il prompt più probabile per l’immagine di input.
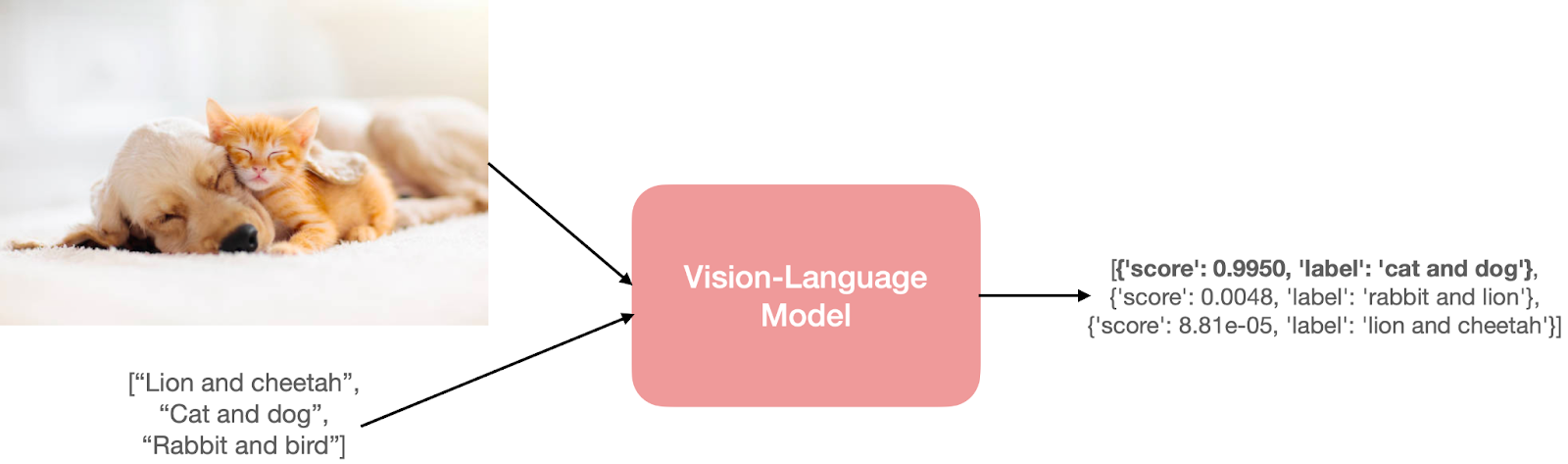 L’immagine del gatto e del cane è stata presa da qui.
L’immagine del gatto e del cane è stata presa da qui.
Per prevedere qualcosa del genere, il modello deve comprendere sia l’immagine di input che i prompt di testo. Il modello avrebbe codificatori separati o fusi per la visione e il linguaggio per raggiungere questa comprensione.
Ma questi input e output possono assumere diverse forme. Di seguito forniamo alcuni esempi:
- Ricerca di immagini a partire da testo linguistico naturale.
- Localizzazione di frasi, cioè rilevamento di oggetti da un’immagine di input e da una frase in linguaggio naturale (esempio: Una persona giovane fa altalena ).
- Risposta a domande visive, cioè trovare risposte da un’immagine di input e una domanda in linguaggio naturale.
- Generare una didascalia per un’immagine data. Questo può assumere anche la forma di generazione di testo condizionale, in cui si parte da un prompt di linguaggio naturale e un’immagine.
- Rilevamento di discorsi di odio da contenuti sui social media che coinvolgono entrambe le modalità di immagini e testo.
Strategie di Apprendimento
Un modello di visione e linguaggio è tipicamente composto da 3 elementi chiave: un codificatore di immagini, un codificatore di testo e una strategia per fondere le informazioni dei due codificatori. Questi elementi chiave sono strettamente legati tra loro poiché le funzioni di perdita sono progettate attorno all’architettura del modello e alla strategia di apprendimento. Sebbene la ricerca sui modelli di visione e linguaggio sia un’area di ricerca non nuova, la progettazione di tali modelli è cambiata enormemente nel corso degli anni. Mentre le ricerche precedenti adottavano descrittori di immagini realizzati a mano e vettori di parole pre-addestrati o le caratteristiche TF-IDF basate sulla frequenza, le ultime ricerche adottano principalmente codificatori di immagini e testo con architetture di trasformatori per apprendere separatamente o congiuntamente le caratteristiche delle immagini e del testo. Questi modelli vengono pre-addestrati con obiettivi di pre-addestramento strategici che consentono vari compiti successivi.
In questa sezione, discuteremo alcuni degli obiettivi e delle strategie tipiche di pre-addestramento per i modelli di visione e linguaggio che hanno dimostrato buone prestazioni nel trasferimento. Affronteremo anche altri aspetti interessanti che sono specifici di questi obiettivi o che possono essere utilizzati come componenti generali per il pre-addestramento.
Tratteremo i seguenti temi negli obiettivi di pre-addestramento:
- Apprendimento Contrastivo: Allineare immagini e testi in uno spazio di caratteristiche congiunto in modo contrastivo
- PrefixLM: Apprendere congiuntamente le incapsulazioni di immagini e testo utilizzando le immagini come prefisso per un modello di linguaggio
- Fusione Multi-modale con Attenzione Incrociata: Fondere le informazioni visive nei livelli di un modello di linguaggio con un meccanismo di attenzione incrociata
- MLM / ITM: Allineare parti delle immagini con il testo mediante modellazione del linguaggio mascherato e obiettivi di corrispondenza tra immagini e testo
- Nessun Addestramento: Utilizzo di modelli di visione e linguaggio autonomi tramite ottimizzazione iterativa
Si noti che questa sezione è un elenco non esaustivo e ci sono vari altri approcci, così come strategie ibride come Unified-IO. Per una revisione più completa dei modelli multimodali, fare riferimento a questo lavoro.
1) Apprendimento contrastivo
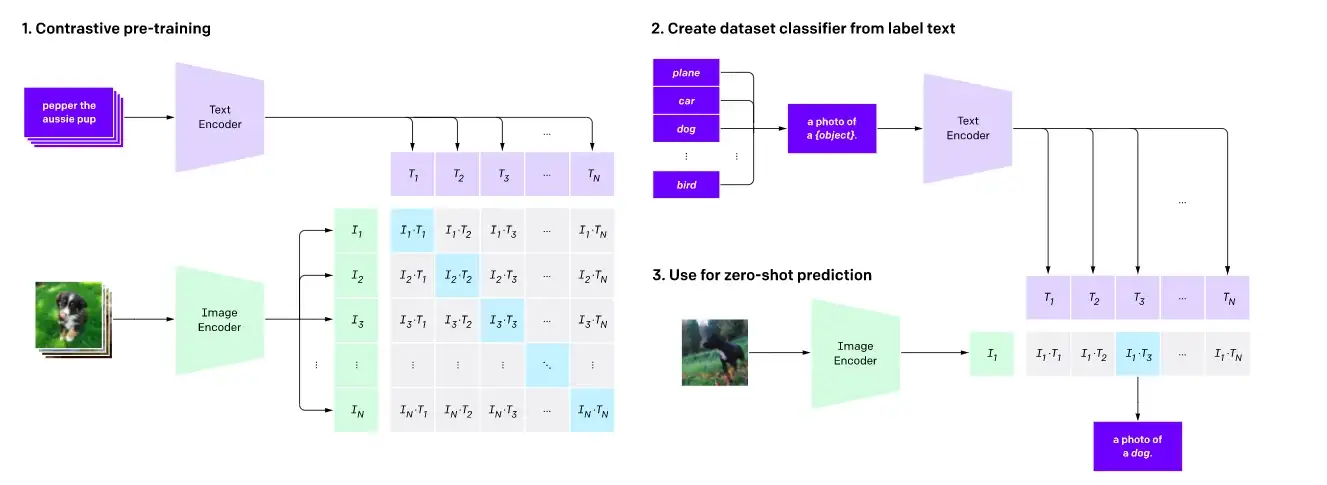 Pre-allenamento contrastivo e classificazione immagine zero-shot come mostrato qui .
Pre-allenamento contrastivo e classificazione immagine zero-shot come mostrato qui .
L’apprendimento contrastivo è un obiettivo di pre-allenamento comunemente utilizzato per i modelli di visione ed è risultato essere un obiettivo di pre-allenamento molto efficace anche per i modelli di visione-linguaggio. Lavori recenti come CLIP, CLOOB, ALIGN e DeCLIP collegano le modalità di visione e di linguaggio apprendendo un codificatore di testo e un codificatore di immagini congiuntamente con una perdita contrastiva, utilizzando grandi dataset composti da coppie {immagine, didascalia}. L’apprendimento contrastivo mira a mappare immagini e testi di input nello stesso spazio di funzionalità in modo che la distanza tra gli embedding delle coppie immagine-testo sia ridotta al minimo se corrispondono o massimizzata se non corrispondono.
Per CLIP, la distanza è semplicemente la distanza coseno tra i testi e gli embedding delle immagini, mentre modelli come ALIGN e DeCLIP progettano le proprie metriche di distanza per tenere conto dei dataset rumorosi.
Un altro lavoro, LiT, introduce un metodo semplice per il fine-tuning del codificatore di testo utilizzando l’obiettivo di pre-allenamento di CLIP mantenendo il codificatore di immagini congelato. Gli autori interpretano questa idea come un modo per insegnare al codificatore di testo a leggere meglio gli embedding delle immagini dal codificatore di immagini. Questo approccio si è dimostrato efficace ed è più efficiente in termini di campioni rispetto a CLIP. Altri lavori, come FLAVA, utilizzano una combinazione di apprendimento contrastivo e altre strategie di pre-allenamento per allineare gli embedding di visione e linguaggio.
2) PrefixLM
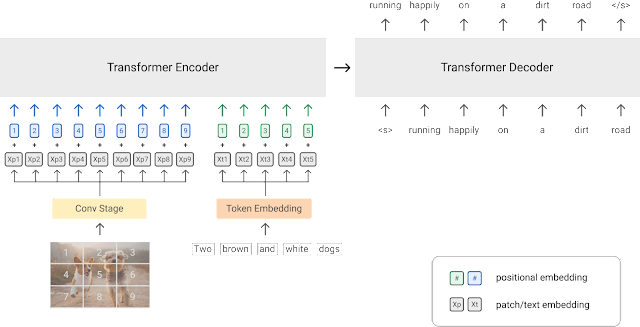 Un diagramma della strategia di pre-allenamento PrefixLM (fonte dell’immagine)
Un diagramma della strategia di pre-allenamento PrefixLM (fonte dell’immagine)
Un altro approccio per allenare modelli di visione-linguaggio è utilizzare un obiettivo di pre-allenamento PrefixLM. Modelli come SimVLM e VirTex utilizzano questo obiettivo di pre-allenamento e presentano un’architettura multimodale unificata composta da un codificatore transformer e un decodificatore transformer, simile a quello di un modello linguistico autoregressivo.
Analizziamo questo e vediamo come funziona. I modelli linguistici con un obiettivo di prefisso prevedono il token successivo dato un testo di input come prefisso. Ad esempio, dato la sequenza “Un uomo sta in piedi all’angolo”, possiamo usare “Un uomo sta in piedi all'” come prefisso e addestrare il modello con l’obiettivo di prevedere il token successivo – “angolo” o un’altra continuazione plausibile del prefisso.
I trasformatori visivi (ViT) applicano lo stesso concetto del prefisso alle immagini suddividendo ciascuna immagine in una serie di patch e alimentando sequenzialmente queste patch al modello come input. Sfruttando questa idea, SimVLM presenta un’architettura in cui il codificatore riceve una sequenza concatenata di patch di immagini e una sequenza di testo come input del prefisso, e il decodificatore prevede quindi la continuazione della sequenza di testo. Il diagramma sopra rappresenta questa idea. Il modello SimVLM viene prima pre-allenato su un dataset di testo senza patch di immagini presenti nel prefisso e poi su un dataset di immagini e testo allineati. Questi modelli vengono utilizzati per la generazione di testo/captioning condizionata dall’immagine e per compiti di VQA.
I modelli che sfruttano un’architettura multimodale unificata per fondere informazioni visive in un modello linguistico (LM) per compiti guidati dall’immagine mostrano capacità impressionanti. Tuttavia, i modelli che utilizzano esclusivamente la strategia PrefixLM possono essere limitati in termini di aree di applicazione in quanto sono principalmente progettati per la creazione di didascalie delle immagini o compiti di risposta alle domande visive. Ad esempio, data un’immagine di un gruppo di persone, possiamo interrogare l’immagine per scrivere una descrizione dell’immagine (ad esempio, “Un gruppo di persone sta insieme davanti a un edificio e sorride”) o interrogarla con domande che richiedono ragionamento visivo: “Quante persone indossano magliette rosse?”. D’altra parte, i modelli che apprendono rappresentazioni multimodali o adottano approcci ibridi possono essere adattati per vari altri compiti successivi, come la rilevazione di oggetti e la segmentazione delle immagini.
PrefixLM congelato
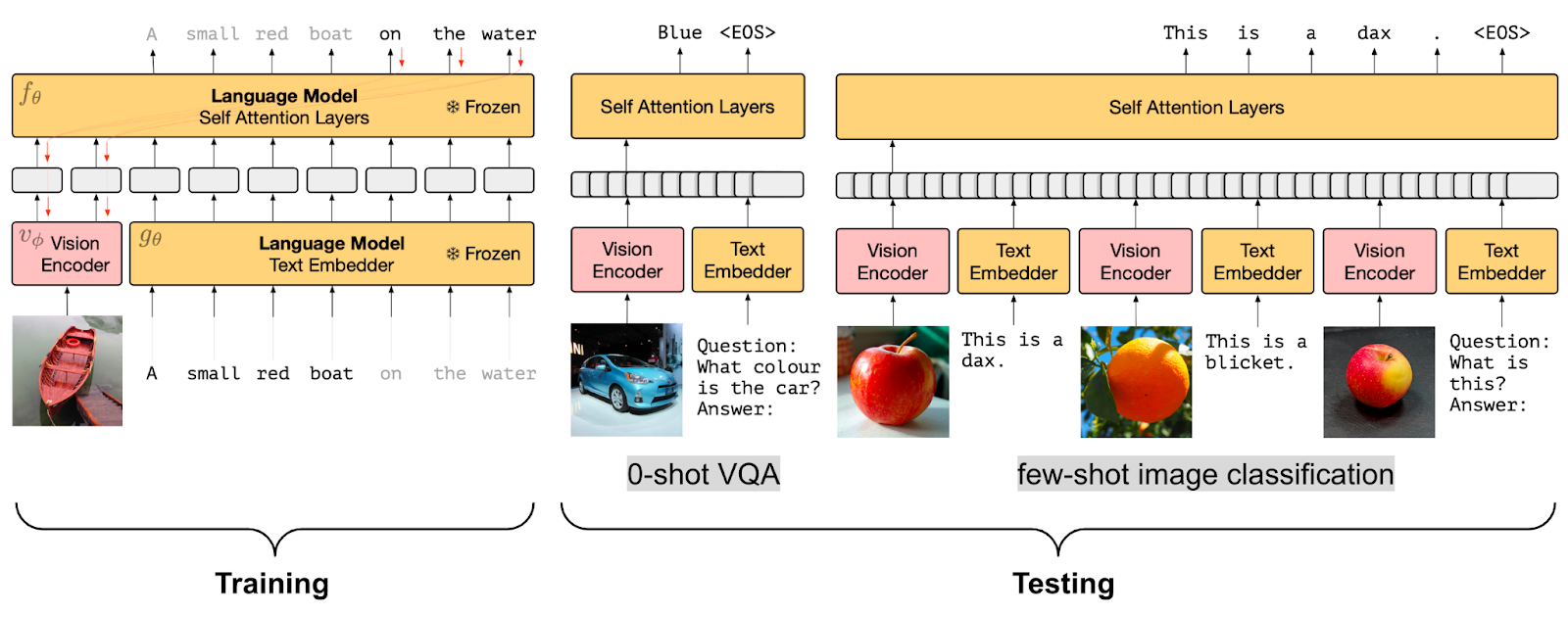 Strategia di pre-allenamento PrefixLM congelato (fonte dell’immagine)
Strategia di pre-allenamento PrefixLM congelato (fonte dell’immagine)
Anche se la fusione delle informazioni visive in un modello linguistico è molto efficace, poter utilizzare un modello linguistico pre-allenato (LM) senza la necessità di un fine-tuning sarebbe molto più efficiente. Pertanto, un altro obiettivo di pre-allenamento nei modelli di visione-linguaggio è apprendere embedding delle immagini che siano allineati con un modello linguistico congelato.
I modelli come Frozen e ClipCap utilizzano questo obiettivo di pre-training Frozen PrefixLM. Durante l’addestramento, vengono aggiornati solo i parametri dell’encoder dell’immagine per generare incorporamenti dell’immagine che possono essere utilizzati come prefisso per il modello linguistico pre-addestrato e congelato in modo simile all’obiettivo PrefixLM discusso in precedenza. Sia Frozen che ClipCap vengono addestrati su dataset di immagini-testo (didascalie) allineati con l’obiettivo di generare il token successivo nella didascalia, dati gli incorporamenti dell’immagine e il testo prefisso.
Infine, modelli come MAPL e Flamingo mantengono sia l’encoder di visione pre-addestrato che il modello linguistico congelati. Flamingo stabilisce un nuovo state-of-the-art nell’apprendimento few-shot su una vasta gamma di compiti di visione e linguaggio aperti, aggiungendo moduli Perceiver Resampler sopra il modello di visione pre-addestrato e congelato e inserendo nuovi strati di cross-attention tra i livelli esistenti del modello linguistico pre-addestrato e congelato per condizionare il modello linguistico sui dati visivi.
Un vantaggio interessante dell’obiettivo di pre-training Frozen PrefixLM è che consente l’addestramento con dati limitati di immagini e testo allineati, il che è particolarmente utile per i domini in cui non sono disponibili dataset multi-modali allineati.
3) Fusione multi-modale con Cross Attention
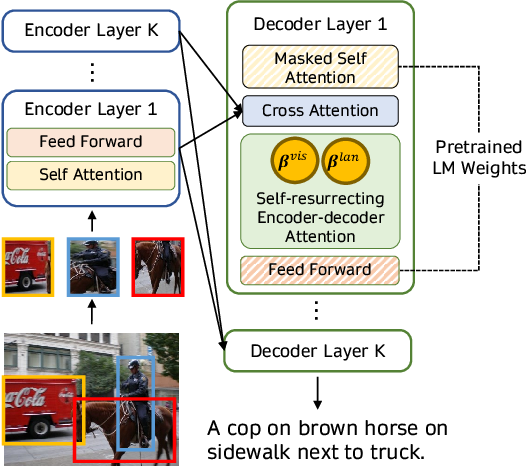 Fusione delle informazioni visive con un meccanismo di cross-attention come mostrato (fonte immagine)
Fusione delle informazioni visive con un meccanismo di cross-attention come mostrato (fonte immagine)
Un altro approccio per sfruttare i modelli linguistici pre-addestrati per compiti multi-modali consiste nel fondere direttamente le informazioni visive nei livelli di un decoder del modello linguistico utilizzando un meccanismo di cross-attention invece di utilizzare le immagini come prefissi aggiuntivi per il modello linguistico. Modelli come VisualGPT, VC-GPT e Flamingo utilizzano questa strategia di pre-training e vengono addestrati su compiti di didascalie di immagini e domande-risposte visive. L’obiettivo principale di tali modelli è bilanciare in modo efficiente la miscela di capacità di generazione di testo e informazioni visive, il che è molto importante in assenza di grandi dataset multi-modali.
I modelli come VisualGPT utilizzano un encoder visivo per incorporare le immagini e alimentano gli incorporamenti visivi ai livelli di cross-attention di un modulo decoder linguistico pre-addestrato per generare didascalie plausibili. Un lavoro più recente, FIBER, inserisce livelli di cross-attention con un meccanismo di gating sia nelle strutture di visione che di linguaggio, per una fusione multi-modale più efficiente e consente vari altri compiti successivi, come il recupero immagine-testo e la rilevazione di oggetti in un vocabolario aperto.
4) Masked-Language Modeling / Image-Text Matching
Un’altra linea di modelli di visione-linguaggio utilizza una combinazione di obiettivi di Masked-Language Modeling (MLM) e Image-Text Matching (ITM) per allineare parti specifiche delle immagini con il testo e consentire vari compiti successivi come la risposta a domande visive, il ragionamento visivo del buon senso, il recupero di immagini basato su testo e la rilevazione di oggetti guidata dal testo. I modelli che seguono questa configurazione di pre-training includono VisualBERT, FLAVA, ViLBERT, LXMERT e BridgeTower.
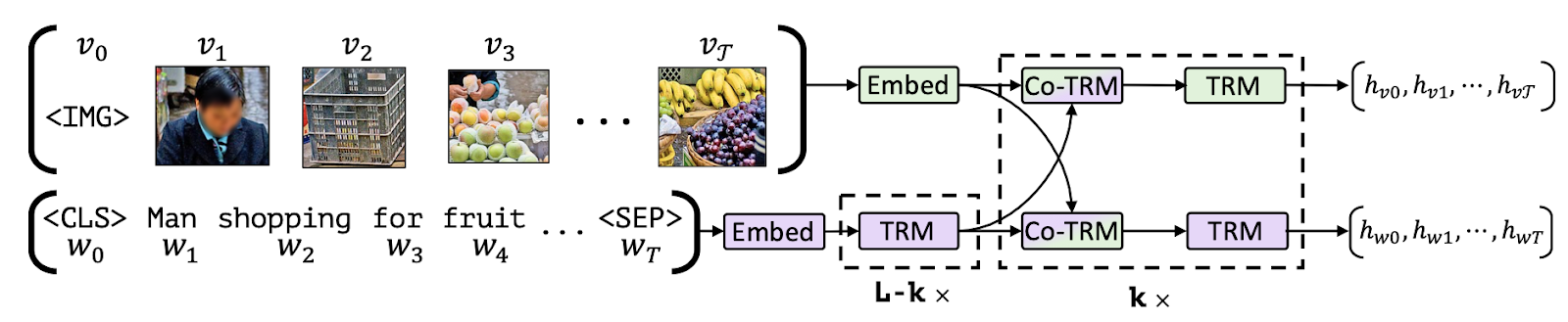 Allineamento di parti delle immagini con il testo (fonte immagine)
Allineamento di parti delle immagini con il testo (fonte immagine)
Suddividiamo cosa significano gli obiettivi MLM e ITM. Dato un’annotazione parzialmente mascherata, l’obiettivo MLM è quello di predire le parole mascherate in base all’immagine corrispondente. Si noti che l’obiettivo MLM richiede l’utilizzo di un dataset multi-modale con bounding box riccamente annotato o l’utilizzo di un modello di rilevamento degli oggetti per generare proposte di regioni oggetto per le parti del testo di input.
Per l’obiettivo ITM, dato una coppia di immagine e didascalia, il compito è quello di prevedere se la didascalia corrisponde o meno all’immagine. I campioni negativi sono solitamente estratti casualmente dal dataset stesso. Gli obiettivi MLM e ITM sono spesso combinati durante il pre-training di modelli multi-modali. Ad esempio, VisualBERT propone un’architettura simile a BERT che utilizza un modello di rilevamento degli oggetti pre-addestrato, Faster-RCNN, per rilevare gli oggetti. Questo modello utilizza una combinazione degli obiettivi MLM e ITM durante il pre-training per allineare implicitamente elementi di un testo di input e regioni in un’immagine di input associate con auto-attenzione.
Un altro lavoro, FLAVA, è composto da un encoder di immagini, un encoder di testo e un encoder multi-modale per fondere e allineare le rappresentazioni di immagini e testo per il ragionamento multi-modale, tutti basati su transformers. Per raggiungere questo obiettivo, FLAVA utilizza una varietà di obiettivi di pre-training: MLM, ITM, nonché Masked-Image Modeling (MIM) e contrastive learning.
5) Nessun Addestramento
Infine, diverse strategie di ottimizzazione mirano a collegare le rappresentazioni di immagini e testo utilizzando i modelli di immagini e testo pre-addestrati o adattare modelli multi-modali pre-addestrati a nuovi compiti successivi senza ulteriore addestramento.
Ad esempio, MaGiC propone un’ottimizzazione iterativa attraverso un modello di linguaggio autoregressivo pre-addestrato per generare una didascalia per l’immagine di input. Per fare ciò, MaGiC calcola un “punteggio Magic” basato su CLIP utilizzando gli embedding CLIP dei token generati e dell’immagine di input.
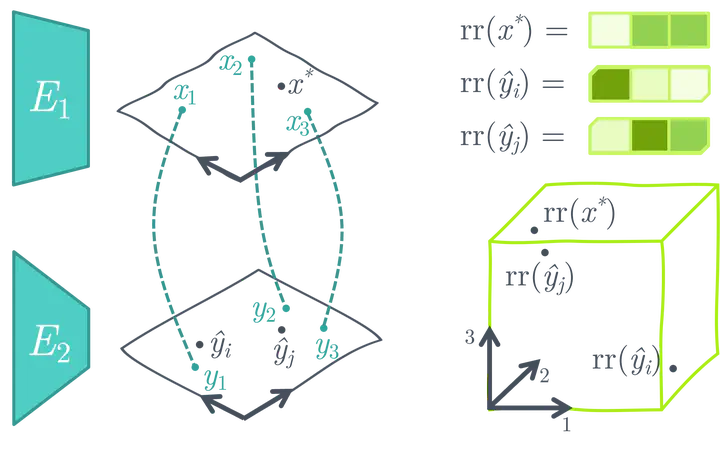 Creazione di uno spazio di ricerca di similarità utilizzando encoder di immagini e testo unimodali pre-addestrati e congelati (fonte immagine)
Creazione di uno spazio di ricerca di similarità utilizzando encoder di immagini e testo unimodali pre-addestrati e congelati (fonte immagine)
ASIF propone un metodo semplice per trasformare modelli unimodali pre-addestrati di immagini e testo in un modello multimodale per la descrizione delle immagini utilizzando un dataset multimodale relativamente piccolo senza ulteriore addestramento. L’intuizione chiave dietro ASIF è che le didascalie di immagini simili sono anche simili tra loro. Pertanto, possiamo effettuare una ricerca basata sulla similarità creando uno spazio di rappresentazione relativa utilizzando un piccolo dataset di coppie multimodali di verità di terreno.
Dataset
I modelli vision-language sono tipicamente addestrati su grandi dataset di immagini e testo con diverse strutture basate sull’obiettivo di pre-addestramento. Dopo essere stati pre-addestrati, vengono ulteriormente raffinati su vari task di downstream utilizzando dataset specifici del task. Questa sezione fornisce una panoramica di alcuni dataset di pre-addestramento e di downstream popolari utilizzati per addestrare e valutare i modelli vision-language.
Dataset di pre-addestramento
I modelli vision-language sono tipicamente pre-addestrati su grandi dataset multimodali raccolti dal web sotto forma di coppie di immagini/video e testo corrispondenti. I dati testuali in questi dataset possono essere didascalie generate dall’uomo, didascalie generate automaticamente, metadati delle immagini o semplici etichette degli oggetti. Alcuni esempi di tali grandi dataset sono PMD e LAION-5B. Il dataset PMD combina più dataset più piccoli come Flickr30K, COCO e Conceptual Captions. Il dataset COCO detection e image captioning (>330K immagini) consiste di istanze di immagini accoppiate con le etichette testuali degli oggetti contenuti in ciascuna immagine e descritti da frasi naturali, rispettivamente. I dataset Conceptual Captions (>3,3M immagini) e Flickr30K (>31K immagini) sono stati raccolti dal web insieme alle loro didascalie, frasi in forma libera che descrivono l’immagine.
Anche i dataset immagine-testo che consistono esclusivamente di didascalie generate dall’uomo, come Flickr30K, sono intrinsecamente rumorosi in quanto gli utenti scrivono solo occasionalmente didascalie descrittive o riflessive per le loro immagini. Per superare questo problema, dataset come il dataset LAION-5B utilizzano CLIP o altri modelli multimodali pre-addestrati per filtrare i dati rumorosi e creare dataset multimodali di alta qualità. Inoltre, alcuni modelli vision-language, come ALIGN, propongono ulteriori passaggi di pre-elaborazione e creano i propri dataset di alta qualità. Altri dataset vision-language, come LSVTD e WebVid, consistono di modalità video e testo, anche se su scala più ridotta.
Dataset di downstream
I modelli vision-language pre-addestrati vengono spesso addestrati su vari task di downstream come domande-risposte visive, rilevamento di oggetti guidato dal testo, completamento di immagini guidate dal testo, classificazione multimodale e vari task autonomi di NLP e computer vision.
I modelli raffinati sul task di downstream di domande-risposte, come ViLT e GLIP, comunemente utilizzano i dataset VQA (domande-risposte visive), VQA v2, NLVR2, OKVQA, TextVQA, TextCaps e VizWiz. Questi dataset contengono tipicamente immagini accoppiate a molteplici domande aperte e risposte. Inoltre, dataset come VizWiz e TextCaps possono essere utilizzati anche per il rilevamento di oggetti e le task di localizzazione. Alcuni altri interessanti dataset multimodali di downstream sono Hateful Memes per la classificazione multimodale, SNLI-VE per la previsione dell’inferenza visiva e Winoground per il ragionamento compositivo visio-linguistico.
Si noti che i modelli vision-language vengono utilizzati per vari task classici di NLP e computer vision come la classificazione di testo o immagini e utilizzano tipicamente dataset unimodali (SST2, ImageNet-1k, ad esempio) per tali task di downstream. Inoltre, dataset come COCO e Conceptual Captions vengono comunemente utilizzati sia nel pre-addestramento dei modelli che per il task di generazione di didascalie.
Supporto ai modelli vision-language in 🤗 Transformers
Utilizzando Hugging Face Transformers, è possibile scaricare, eseguire e raffinare facilmente vari modelli vision-language pre-addestrati o combinare modelli visione e linguaggio pre-addestrati per creare la propria ricetta. Alcuni dei modelli vision-language supportati da 🤗 Transformers sono:
- CLIP
- FLAVA
- GIT
- BridgeTower
- GroupViT
- BLIP
- OWL-ViT
- CLIPSeg
- X-CLIP
- VisualBERT
- ViLT
- LiT (un’istanza di
VisionTextDualEncoder) - TrOCR (un’istanza di
VisionEncoderDecoderModel) VisionTextDualEncoderVisionEncoderDecoderModel
Mentre modelli come CLIP, FLAVA, BridgeTower, BLIP, LiT e modelli VisionEncoderDecoder forniscono incorporamenti congiunti immagine-testo che possono essere utilizzati per compiti successivi come la classificazione di immagini senza campioni, altri modelli sono addestrati su compiti interessanti successivi. Inoltre, FLAVA è addestrato con obiettivi di pre-allenamento unimodali e multimodali e può essere utilizzato sia per compiti di visione o linguaggio unimodali che per compiti multimodali.
Ad esempio, OWL-ViT consente la rilevazione oggetti senza campioni / guidata dal testo e la rilevazione oggetti con un solo colpo / guidata dall’immagine, CLIPSeg e GroupViT consentono la segmentazione di immagini guidate da testo e immagini, e VisualBERT, GIT e ViLT consentono la risposta a domande visive oltre a vari altri compiti. X-CLIP è un modello multimodale addestrato con modalità video e testo e consente la classificazione di video senza campioni simile alle capacità di classificazione di immagini senza campioni di CLIP.
A differenza di altri modelli, il VisionEncoderDecoderModel è un modello standardizzato che può essere utilizzato per inizializzare un modello immagine-testo con qualsiasi modello di visione basato su Transformer pre-addestrato come codificatore (ad esempio ViT, BEiT, DeiT, Swin) e qualsiasi modello di linguaggio pre-addestrato come decodificatore (ad esempio RoBERTa, GPT2, BERT, DistilBERT). Infatti, TrOCR è un’istanza di questa classe standardizzata.
Andiamo avanti e sperimentiamo alcuni di questi modelli. Useremo ViLT per la risposta a domande visive e CLIPSeg per la segmentazione di immagini senza campioni. Prima, installiamo 🤗Transformers: pip install transformers.
ViLT per VQA
Iniziamo con ViLT e scarichiamo un modello pre-addestrato sul dataset VQA. Possiamo farlo semplicemente inizializzando la classe di modello corrispondente e chiamando il metodo from_pretrained() per scaricare il checkpoint desiderato.
from transformers import ViltProcessor, ViltForQuestionAnswering
model = ViltForQuestionAnswering.from_pretrained("dandelin/vilt-b32-finetuned-vqa")Successivamente, scaricheremo un’immagine casuale di due gatti e preelaboreremo sia l’immagine che la nostra domanda di query per trasformarle nel formato di input previsto dal modello. Per fare ciò, possiamo utilizzare comodamente la classe di preelaborazione corrispondente (ViltProcessor) e inizializzarla con la configurazione di preelaborazione del checkpoint corrispondente.
import requests
from PIL import Image
processor = ViltProcessor.from_pretrained("dandelin/vilt-b32-finetuned-vqa")
# scarica un'immagine di input
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
text = "Quanti gatti ci sono?"
# prepara gli input
inputs = processor(image, text, return_tensors="pt")Infine, possiamo eseguire l’inferenza utilizzando l’immagine preelaborata e la domanda come input e stampare la risposta prevista. Tuttavia, un punto importante da tenere presente è assicurarsi che l’input di testo assomigli ai modelli di domanda utilizzati nella configurazione di allenamento. Puoi fare riferimento all’articolo e al dataset per capire come vengono formulate le domande.
import torch
# passaggio in avanti
with torch.no_grad():
outputs = model(**inputs)
logits = outputs.logits
idx = logits.argmax(-1).item()
print("Risposta prevista:", model.config.id2label[idx])Semplice, vero? Facciamo un’altra dimostrazione con CLIPSeg e vediamo come possiamo eseguire la segmentazione di immagini senza campioni con poche righe di codice.
CLIPSeg per la segmentazione di immagini senza campioni
Inizieremo inizializzando CLIPSegForImageSegmentation e la sua classe di preelaborazione corrispondente e caricheremo il nostro modello pre-addestrato.
from transformers import CLIPSegProcessor, CLIPSegForImageSegmentation
processor = CLIPSegProcessor.from_pretrained("CIDAS/clipseg-rd64-refined")
model = CLIPSegForImageSegmentation.from_pretrained("CIDAS/clipseg-rd64-refined")Successivamente, useremo la stessa immagine di input e interrogheremo il modello con le descrizioni di testo di tutti gli oggetti che vogliamo segmentare. Come per gli altri preprocessor, CLIPSegProcessor trasforma gli input nel formato previsto dal modello. Poiché vogliamo segmentare più oggetti, inseriamo la stessa immagine per ogni descrizione di testo separatamente.
from PIL import Image
import requests
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
texts = ["un gatto", "un telecomando", "una coperta"]
inputs = processor(text=texts, images=[image] * len(texts), padding=True, return_tensors="pt")Similarmente a ViLT, è importante fare riferimento al lavoro originale per vedere che tipo di prompt di testo vengono utilizzati per addestrare il modello al fine di ottenere le migliori prestazioni durante l’elaborazione. Mentre CLIPSeg è addestrato su semplici descrizioni di oggetti (ad esempio, “una macchina”), il suo backbone CLIP è pre-addestrato su modelli di testo progettati (ad esempio, “un’immagine di una macchina”, “una foto di una macchina”) e rimane congelato durante l’addestramento. Una volta che gli input sono preelaborati, possiamo eseguire l’elaborazione per ottenere una mappa di segmentazione binaria di forma (altezza, larghezza) per ogni query di testo.
import torch
with torch.no_grad():
outputs = model(**inputs)
logits = outputs.logits
print(logits.shape)
>>> torch.Size([3, 352, 352])Visualizziamo i risultati per vedere quanto bene CLIPSeg si è comportato (il codice è adattato da questo post).
import matplotlib.pyplot as plt
logits = logits.unsqueeze(1)
_, ax = plt.subplots(1, len(texts) + 1, figsize=(3*(len(texts) + 1), 12))
[a.axis('off') for a in ax.flatten()]
ax[0].imshow(image)
[ax[i+1].imshow(torch.sigmoid(logits[i][0])) for i in range(len(texts))];
[ax[i+1].text(0, -15, prompt) for i, prompt in enumerate(texts)]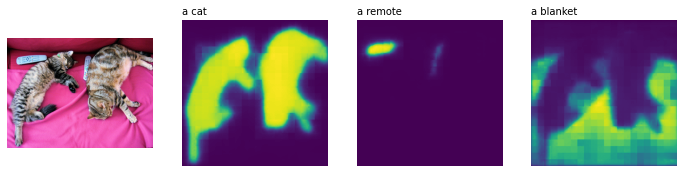
Incredibile, vero?
I modelli di visione-linguaggio consentono una miriade di casi d’uso utili e interessanti che vanno oltre la semplice VQA e la segmentazione a zero-shot. Ti invitiamo a provare i diversi casi d’uso supportati dai modelli menzionati in questa sezione. Per il codice di esempio, consulta la documentazione corrispondente dei modelli.
Aree di Ricerca Emergenti
Con i massicci progressi nei modelli di visione-linguaggio, stiamo assistendo all’emergere di nuovi compiti e aree di applicazione, come la medicina e la robotica. Ad esempio, i modelli di visione-linguaggio stanno sempre più venendo adottati per casi d’uso medici, dando luogo a lavori come Clinical-BERT per la diagnosi medica e la generazione di rapporti da radiografie e MedFuseNet per la risposta alle domande visive nel campo medico.
Vediamo anche un’enorme crescita di lavori che sfruttano rappresentazioni congiunte di visione e linguaggio per la manipolazione delle immagini (ad esempio, StyleCLIP, StyleMC, DiffusionCLIP), il recupero di video basato su testo (ad esempio, X-CLIP) e la manipolazione (ad esempio, Text2Live) e la manipolazione di forme e texture 3D (ad esempio, AvatarCLIP, CLIP-NeRF, Latent3D, CLIPFace, Text2Mesh). In una linea simile di lavoro, MVT propone un modello di rappresentazione congiunta di scene e testo 3D, che può essere utilizzato per vari compiti successivi come il completamento di scene 3D.
Sebbene la ricerca in robotica non abbia ancora sfruttato i modelli di visione-linguaggio su vasta scala, vediamo lavori come CLIPort che sfruttano rappresentazioni congiunte di visione e linguaggio per l’apprendimento per imitazione end-to-end e riportano grandi miglioramenti rispetto alla precedente letteratura. Vediamo anche che i grandi modelli di linguaggio vengono sempre più adottati in compiti di robotica come il ragionamento di senso comune, la navigazione e la pianificazione delle attività. Ad esempio, ProgPrompt propone un framework per generare piani di attività robotiche situati utilizzando grandi modelli di linguaggio (LLMs). Allo stesso modo, SayCan utilizza LLM per selezionare le azioni più plausibili date una descrizione visiva dell’ambiente e gli oggetti disponibili. Sebbene questi progressi siano impressionanti, la ricerca in robotica è ancora limitata a insiemi limitati di ambienti e oggetti a causa della limitazione dei dataset di rilevamento degli oggetti. Con l’emergere di modelli di rilevamento di oggetti a vocabolario aperto come OWL-ViT e GLIP, possiamo aspettarci un’integrazione più stretta di modelli multimodali con i framework di navigazione, ragionamento, manipolazione e pianificazione delle attività robotiche.
Conclusione
Negli ultimi anni sono stati compiuti incredibili progressi nei modelli multimodali, con i modelli di visione-linguaggio che hanno compiuto il balzo più significativo in termini di prestazioni, varietà di casi d’uso e applicazioni. In questo articolo, abbiamo parlato degli ultimi sviluppi nei modelli di visione-linguaggio, nonché dei dataset multimodali disponibili e delle strategie di pre-addestramento che possiamo utilizzare per addestrare e affinare tali modelli. Abbiamo anche mostrato come questi modelli siano integrati in 🤗 Transformers e come è possibile utilizzarli per eseguire vari compiti con poche righe di codice.
Continuiamo ad integrare i modelli di visione artificiale e multi-modalità più impattanti e saremmo felici di ricevere un tuo feedback. Per rimanere aggiornato sulle ultime novità della ricerca multi-modalità, puoi seguirci su Twitter: @adirik, @NielsRogge, @apsdehal, @a_e_roberts, @RisingSayak e @huggingface.
Riconoscimenti: Ringraziamo Amanpreet Singh e Amy Roberts per le loro rigide revisioni. Inoltre, grazie a Niels Rogge, Younes Belkada e Suraj Patil, tra molti altri presso Hugging Face, che hanno gettato le basi per aumentare l’uso dei modelli multi-modalità di Transformers.