Sintonizzazione fine efficiente dei parametri utilizzando 🤗 PEFT
'Efficient fine-tuning of parameters using 🤗 PEFT.'
Motivazione
I Large Language Models (LLM) basati sull’architettura transformer, come GPT, T5 e BERT, hanno raggiunto risultati all’avanguardia in varie attività di elaborazione del linguaggio naturale (NLP). Hanno anche iniziato ad esplorare altri ambiti, come la visione artificiale (CV) (VIT, Stable Diffusion, LayoutLM) e l’audio (Whisper, XLS-R). Il paradigma convenzionale prevede un addestramento su larga scala su dati generici del web, seguito da un raffinamento per compiti specifici. Il raffinamento di questi LLM preaddestrati su set di dati specifici porta a notevoli miglioramenti delle prestazioni rispetto all’utilizzo dei LLM preaddestrati come sono (ad esempio, inferenza zero-shot).
Tuttavia, man mano che i modelli diventano sempre più grandi, diventa impossibile eseguire un raffinamento completo su hardware consumer. Inoltre, archiviare e distribuire modelli raffinati in modo indipendente per ogni compito specifico diventa molto costoso, poiché i modelli raffinati hanno le stesse dimensioni del modello preaddestrato originale. Gli approcci di Raffinamento Efficienti dei Parametri (PEFT) sono pensati per affrontare entrambi i problemi!
Gli approcci PEFT raffinano solo un piccolo numero di parametri (extra) del modello, mantenendo la maggior parte dei parametri dei LLM preaddestrati immutati, riducendo così notevolmente i costi computazionali e di archiviazione. Questo supera anche i problemi del cosiddetto “catastrophic forgetting”, un comportamento osservato durante il raffinamento completo dei LLM. Gli approcci PEFT hanno dimostrato di essere migliori del raffinamento completo in scenari di bassa disponibilità di dati e di generalizzare meglio in scenari fuori dominio. Possono essere applicati a diverse modalità, ad esempio, classificazione di immagini e stable diffusion dreambooth.
Aiuta anche la portabilità, in cui gli utenti possono regolare i modelli utilizzando metodi PEFT per ottenere checkpoint minimi di pochi MB rispetto ai grandi checkpoint del raffinamento completo. Ad esempio, bigscience/mt0-xxl occupa 40 GB di archiviazione e il raffinamento completo comporterebbe checkpoint di 40 GB per ogni set di dati specifico, mentre utilizzando i metodi PEFT sarebbero solo alcuni MB per ogni set di dati specifico, ottenendo comunque prestazioni comparabili al raffinamento completo. I pesi addestrati dai metodi PEFT vengono aggiunti al modello LLM preaddestrato. Pertanto, lo stesso LLM può essere utilizzato per più compiti aggiungendo piccoli pesi senza dover sostituire l’intero modello.
- Generazione di testo immagine-a-testo senza addestramento con BLIP-2
- Hugging Face e AWS si associano per rendere l’IA più accessibile
- Swift 🧨Diffusers – Diffusori veloci e stabili per Mac
In breve, gli approcci PEFT consentono di ottenere prestazioni paragonabili al raffinamento completo utilizzando solo un piccolo numero di parametri addestrabili.
Oggi, siamo entusiasti di presentare la libreria 🤗 PEFT, che offre le ultime tecniche di raffinamento efficiente dei parametri integrate in modo fluido con 🤗 Transformers e 🤗 Accelerate. Ciò consente di utilizzare i modelli più popolari e performanti di Transformers, uniti alla semplicità e alla scalabilità di Accelerate. Di seguito sono elencati i metodi PEFT attualmente supportati, con altri in arrivo:
- LoRA: LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS
- Prefix Tuning: P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks
- Prompt Tuning: The Power of Scale for Parameter-Efficient Prompt Tuning
- P-Tuning: GPT Understands, Too
Casi d’uso
Esploriamo molti casi d’uso interessanti qui . Ecco alcuni dei più interessanti:
-
Utilizzo di 🤗 PEFT LoRA per l’addestramento del modello
bigscience/T0_3B(3 miliardi di parametri) su hardware consumer con 11 GB di RAM, come Nvidia GeForce RTX 2080 Ti, Nvidia GeForce RTX 3080, ecc., utilizzando l’integrazione di 🤗 Accelerate con DeepSpeed: peft_lora_seq2seq_accelerate_ds_zero3_offload.py. Ciò significa che è possibile addestrare tali grandi LLM su Google Colab. -
Portando l’esempio precedente a un livello superiore, abilitando il raffinamento INT8 del modello
OPT-6.7b(6,7 miliardi di parametri) su Google Colab utilizzando 🤗 PEFT LoRA e bitsandbytes:
-
Addestramento di Stable Diffusion Dreambooth utilizzando 🤗 PEFT su hardware consumer con 11 GB di RAM, come Nvidia GeForce RTX 2080 Ti, Nvidia GeForce RTX 3080, ecc. Prova la demo spaziale, che dovrebbe funzionare senza problemi su un’istanza T4 (16 GB GPU): smangrul/peft-lora-sd-dreambooth.
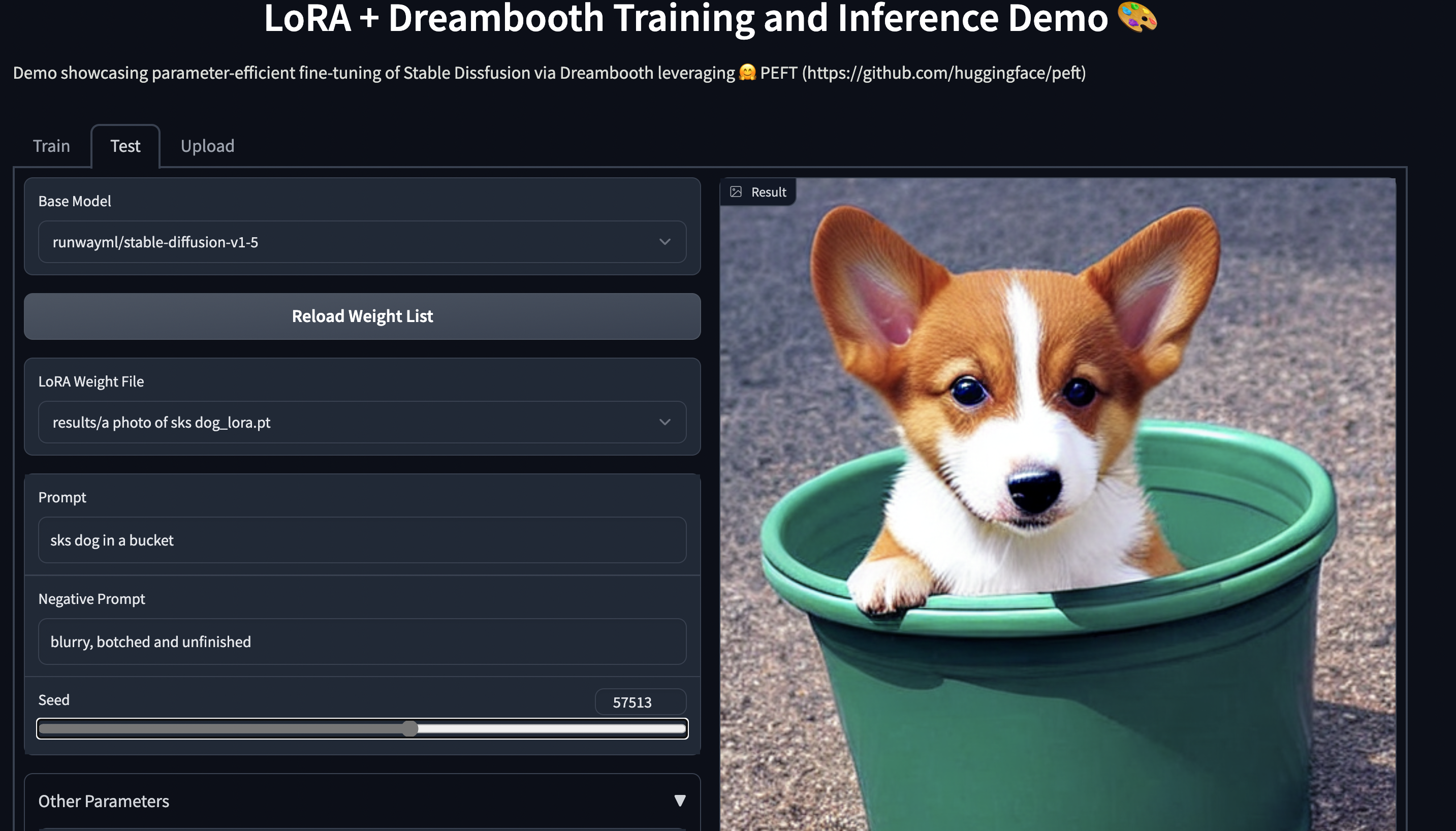 Spazio PEFT LoRA Dreambooth Gradio
Spazio PEFT LoRA Dreambooth Gradio
Allenare il tuo modello usando 🤗 PEFT
Consideriamo il caso del fine-tuning di bigscience/mt0-large usando LoRA.
- Otteniamo gli import necessari
from transformers import AutoModelForSeq2SeqLM
+ from peft import get_peft_model, LoraConfig, TaskType
model_name_or_path = "bigscience/mt0-large"
tokenizer_name_or_path = "bigscience/mt0-large"- Creiamo una configurazione corrispondente al metodo PEFT
peft_config = LoraConfig(
task_type=TaskType.SEQ_2_SEQ_LM, inference_mode=False, r=8, lora_alpha=32, lora_dropout=0.1
)- Involgiamo il modello base 🤗 Transformers chiamando
get_peft_model
model = AutoModelForSeq2SeqLM.from_pretrained(model_name_or_path)
+ model = get_peft_model(model, peft_config)
+ model.print_trainable_parameters()
# output: trainable params: 2359296 || all params: 1231940608 || trainable%: 0.19151053100118282Ecco fatto! Il resto del ciclo di allenamento rimane lo stesso. Si prega di fare riferimento all’esempio peft_lora_seq2seq.ipynb per un esempio completo.
- Quando sei pronto per salvare il modello per l’inferenza, fai semplicemente quanto segue.
model.save_pretrained("output_dir")
# model.push_to_hub("my_awesome_peft_model") funziona ancheQuesto salverà solo i pesi incrementali PEFT che sono stati allenati. Ad esempio, puoi trovare il bigscience/T0_3B sintonizzato usando LoRA sul dataset raft twitter_complaints qui: smangrul/twitter_complaints_bigscience_T0_3B_LORA_SEQ_2_SEQ_LM . Nota che contiene solo 2 file: adapter_config.json e adapter_model.bin, quest’ultimo è solo di 19MB.
- Per caricarlo per l’inferenza, segui lo snippet qui sotto:
from transformers import AutoModelForSeq2SeqLM
+ from peft import PeftModel, PeftConfig
peft_model_id = "smangrul/twitter_complaints_bigscience_T0_3B_LORA_SEQ_2_SEQ_LM"
config = PeftConfig.from_pretrained(peft_model_id)
model = AutoModelForSeq2SeqLM.from_pretrained(config.base_model_name_or_path)
+ model = PeftModel.from_pretrained(model, peft_model_id)
tokenizer = AutoTokenizer.from_pretrained(config.base_model_name_or_path)
model = model.to(device)
model.eval()
inputs = tokenizer("Testo del tweet: @HondaCustSvc Il vostro servizio clienti è stato orribile durante il processo di richiamo. Non comprerò mai più un'auto Honda. Etichetta :", return_tensors="pt")
with torch.no_grad():
outputs = model.generate(input_ids=inputs["input_ids"].to("cuda"), max_new_tokens=10)
print(tokenizer.batch_decode(outputs.detach().cpu().numpy(), skip_special_tokens=True)[0])
# 'lamentela'Passaggi successivi
Abbiamo rilasciato PEFT come un modo efficiente per sintonizzare grandi LLM su compiti e domini successivi, risparmiando molta potenza di calcolo e spazio di archiviazione pur raggiungendo prestazioni comparabili al fine-tuning completo. Nei prossimi mesi, esploreremo altri metodi PEFT, come (IA)3 e adattatori bottleneck. Inoltre, ci concentreremo su nuovi casi d’uso come l’addestramento INT8 del modello whisper-large in Google Colab e la sintonizzazione dei componenti RLHF come la politica e il ranker utilizzando approcci PEFT.
Nel frattempo, siamo entusiasti di vedere come i professionisti del settore applicano PEFT ai loro casi d’uso – se avete domande o feedback, aprite una segnalazione sul nostro repository GitHub 🤗.
Buon Fine-Tuning dei Parametri!