Come dovresti convalidare i modelli di apprendimento automatico
Validating machine learning models
Impara a costruire fiducia nelle tue soluzioni di apprendimento automatico

I grandi modelli di linguaggio hanno già trasformato in modo significativo l’industria della scienza dei dati. Uno dei più grandi vantaggi è il fatto che per la maggior parte delle applicazioni possono essere utilizzati così come sono, non dobbiamo addestrarli noi stessi. Questo ci obbliga a rivalutare alcune delle comuni supposizioni sul processo di apprendimento automatico: molti professionisti considerano la convalida “parte dell’addestramento”, il che suggerirebbe che non è più necessaria. Speriamo che al lettore sia venuto un brivido all’idea che la convalida sia obsoleta, perché certamente non lo è.
In questo articolo, esaminiamo l’idea stessa della convalida e del test del modello. Se ti consideri perfettamente fluente nelle basi dell’apprendimento automatico, puoi saltare questo articolo. Altrimenti, preparati: abbiamo alcuni scenari fantasiosi per cui dovrai sospendere l’incredulità.
Questo articolo è un lavoro congiunto di Patryk Miziuła, PhD e Jan Kanty Milczek.
Apprendimento su un’isola deserta
Immagina di voler insegnare a qualcuno a riconoscere le lingue dei tweet su Twitter. Quindi lo porti su un’isola deserta, gli dai 100 tweet in 10 lingue diverse, gli dici in quale lingua è ogni tweet e lo lasci da solo per un paio di giorni. Dopo di che, torni sull’isola per verificare se ha davvero imparato a riconoscere le lingue. Ma come puoi esaminarlo?
- Tendenze delle startup di intelligenza artificiale Insights dall’ultima selezione di Y Combinator
- Google AI presenta SimPer un framework contrastivo auto-supervisionato per apprendere informazioni periodiche nei dati
- Una nuova ricerca sull’IA dall’Italia introduce un modello generativo basato sulla diffusione capace sia di sintesi musicale che di separazione delle fonti
Il tuo primo pensiero potrebbe essere di chiedergli quali lingue sono presenti nei tweet che ha ricevuto. Quindi gli fai questa sfida e lui risponde correttamente per tutti i 100 tweet. Significa davvero che è in grado di riconoscere le lingue in generale? Forse, ma potrebbe aver semplicemente memorizzato questi 100 tweet! E tu non hai modo di sapere quale scenario sia vero!
In questo caso non hai verificato ciò che volevi verificare. Basandoti su un esame del genere, semplicemente non puoi sapere se puoi fare affidamento sulle sue capacità di riconoscimento delle lingue in una situazione di vita o di morte (che tendono a verificarsi quando sono coinvolte isole deserte).
Cosa dovremmo fare invece? Come fare per essere sicuri che abbia imparato anziché semplicemente memorizzare? Diamo a lui altri 50 tweet e chiediamogli di dirci le lingue! Se le indovina, è sicuramente in grado di riconoscere la lingua. Ma se fallisce completamente, sai che ha semplicemente imparato a memoria i primi 100 tweet, il che non era lo scopo dell’intera cosa.
Ma come è tutto questo collegato ai modelli di apprendimento automatico?
La storia sopra descrive in modo figurativo come i modelli di apprendimento automatico imparano e come dovremmo verificare la loro qualità:
- L’uomo nella storia rappresenta un modello di apprendimento automatico. Per disconnettere un essere umano dal mondo, devi portarlo su un’isola deserta. Per un modello di apprendimento automatico è più semplice, è solo un programma informatico, quindi non comprende intrinsecamente l’idea del mondo.
- Riconoscere la lingua di un tweet è un compito di classificazione, con 10 possibili classi, alias categorie, poiché abbiamo scelto 10 lingue.
- I primi 100 tweet utilizzati per l’apprendimento sono chiamati set di addestramento. Le lingue corrette associate sono chiamate etichette.
- Gli altri 50 tweet utilizzati solo per esaminare l’uomo/modello sono chiamati set di test. Nota che conosciamo le loro etichette, ma l’uomo/modello no.
Il grafico qui sotto mostra come addestrare e testare correttamente il modello:
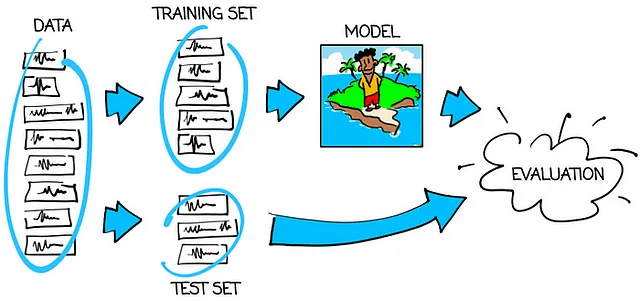
Quindi la regola principale è:
Testa un modello di apprendimento automatico su un insieme di dati diverso rispetto a quello su cui è stato addestrato.
Se il modello si comporta bene sull’insieme di addestramento, ma si comporta male sull’insieme di test, diciamo che il modello è sovraadattato. “Sovraadattamento” significa memorizzare i dati di addestramento. Questo è sicuramente ciò che non vogliamo ottenere. Il nostro obiettivo è avere un modello addestrato – buono sia per l’insieme di addestramento che per l’insieme di test. Solo questo tipo di modello può essere affidabile. E solo allora possiamo credere che si comporterà altrettanto bene nell’applicazione finale per cui è stato creato come ha fatto sull’insieme di test.
Ora andiamo avanti.
1000 uomini su 1000 isole deserte
Immagina che tu voglia davvero insegnare a un uomo a riconoscere le lingue dei tweet su Twitter. Quindi trovi 1000 candidati, porti ognuno su un’isola deserta diversa, dai a ognuno gli stessi 100 tweet in 10 lingue diverse, dici a ognuno in quale lingua è scritto ogni tweet e li lasci soli per un paio di giorni. Dopo, esaminerai ogni candidato con lo stesso insieme di 50 tweet diversi.
Quale candidato sceglierai? Ovviamente, quello che ha ottenuto i migliori risultati con i 50 tweet. Ma quanto è bravo davvero? Possiamo davvero credere che si comporterà altrettanto bene nell’applicazione finale come ha fatto con questi 50 tweet?
La risposta è no! Perché no? Per metterlo semplicemente, se ogni candidato conosce alcune risposte e indovina alcune delle altre, allora scegli quello che ha ottenuto il maggior numero di risposte corrette, non quello che ne conosceva di più. È sicuramente il miglior candidato, ma il suo risultato è gonfiato da “indovinamenti fortunati”. Probabilmente è stata una grande parte del motivo per cui è stato scelto.
Per mostrare questo fenomeno in forma numerica, immagina che 47 tweet fossero facili per tutti i candidati, ma i restanti 3 messaggi fossero così difficili per tutti i concorrenti che tutti hanno semplicemente indovinato le lingue alla cieca. La probabilità che qualcuno (forse più di una persona) abbia indovinato tutti e 3 i tweet difficili è superiore al 63% (informazione per i patiti di matematica: è quasi 1-1/e). Quindi probabilmente sceglierai qualcuno che ha ottenuto un punteggio perfetto, ma in realtà non è perfetto per ciò di cui hai bisogno.
Magari 3 su 50 tweet nel nostro esempio non sembrano impressionanti, ma per molti casi reali questa discrepanza tende ad essere molto più evidente.
Allora come possiamo verificare quanto è bravo il vincitore effettivamente? Sì, dobbiamo procurarci un altro insieme di 50 tweet e esaminarlo di nuovo! Solo in questo modo otterremo un punteggio di cui possiamo fidarci. Questo livello di precisione è ciò che ci aspettiamo dall’applicazione finale.
Torniamo alla terminologia dell’apprendimento automatico
In termini di nomi:
- Il primo insieme di 100 tweet è ancora l’insieme di addestramento, poiché lo usiamo per addestrare i modelli.
- Ma ora lo scopo del secondo insieme di 50 tweet è cambiato. Questa volta è stato utilizzato per confrontare diversi modelli. Un tale insieme è chiamato insieme di convalida.
- Abbiamo già capito che il risultato del miglior modello esaminato sull’insieme di convalida è artificialmente migliorato. Questo è il motivo per cui abbiamo bisogno di un altro insieme di 50 tweet che svolga il ruolo dell’insieme di test e ci fornisca informazioni affidabili sulla qualità del miglior modello.
Puoi trovare il flusso di utilizzo dell’insieme di addestramento, di convalida e di test nell’immagine qui sotto:
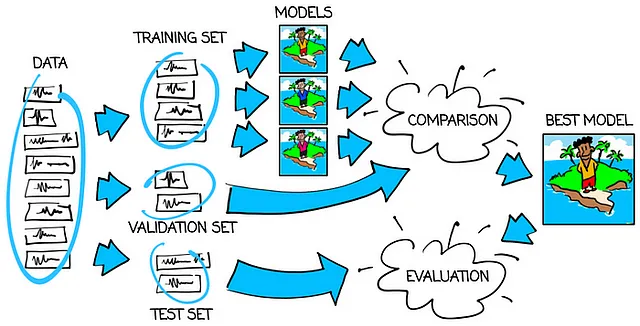
Bene, e perché abbiamo usato insiemi di esattamente 100, 50 e 50 tweet?
Ecco le due idee generali dietro questi numeri:
Inserisci il maggior numero di dati possibili nell’insieme di addestramento.
Più dati di addestramento abbiamo, più ampio sarà lo sguardo dei modelli e maggiore sarà la possibilità di addestrare anziché sovraadattare. Gli unici limiti dovrebbero essere la disponibilità dei dati e i costi di elaborazione dei dati.
Inserisci nella validazione e nei set di test la quantità minima di dati possibile, ma assicurati che siano abbastanza grandi.
Perché? Perché non vuoi sprecare molti dati per nient’altro che l’addestramento. Ma d’altra parte probabilmente pensi che valutare il modello basandosi su un singolo tweet potrebbe essere rischioso. Quindi hai bisogno di un insieme di tweet abbastanza grande da non temere disturbi nel punteggio nel caso di un piccolo numero di tweet davvero strani.
E come convertire queste due linee guida in numeri precisi? Se hai a disposizione 200 tweet, allora la divisione 100/50/50 sembra essere adeguata in quanto rispetta entrambe le regole sopra citate. Ma se hai 1.000.000 di tweet, puoi facilmente optare per una divisione di 800.000/100.000/100.000 o addirittura 900.000/50.000/50.000. Forse hai visto qualche suggerimento percentuale da qualche parte, come ad esempio 60%/20%/20% circa. Beh, sono solo una semplificazione eccessiva delle due regole principali sopra citate, quindi è meglio attenersi alle linee guida originali.
OK, ma come scegliere quali tweet andranno nel set di addestramento/validazione/test?
Riteniamo che questa regola principale appaia chiara a questo punto:
Utilizza tre diversi insiemi di dati per addestrare, convalidare e testare i modelli.
Quindi cosa succede se questa regola viene violata? Cosa succede se gli stessi dati, o quasi gli stessi dati, per caso o per mancanza di attenzione, finiscono in più di uno dei tre set di dati? Questo è ciò che chiamiamo fuga di dati. I set di convalida e di test non sono più affidabili. Non possiamo dire se il modello è addestrato o sovradattato. Semplicemente non possiamo fidarci del modello. Non è buono.
Forse pensi che questi problemi non riguardino la nostra storia sull’isola deserta. Prendiamo semplicemente 100 tweet per l’addestramento, altri 50 per la convalida e altri 50 per il test e basta. Purtroppo, non è così semplice. Dobbiamo essere molto attenti. Vediamo alcuni esempi.
Esempio 1: molti tweet casuali
Supponiamo che tu abbia raccolto 1.000.000 di tweet completamente casuali da Twitter. Autori diversi, tempi, argomenti, localizzazioni, numeri di reazioni, ecc. Proprio casuali. E sono in 10 lingue diverse e vuoi usarli per insegnare al modello a riconoscere la lingua. Allora non devi preoccuparti di nulla e puoi semplicemente estrarre 900.000 tweet per il set di addestramento, 50.000 per il set di convalida e 50.000 per il set di test. Questo è chiamato divisione casuale.
Perché estrarli casualmente e non mettere i primi 900.000 tweet nel set di addestramento, i successivi 50.000 nel set di convalida e gli ultimi 50.000 nel set di test? Perché i tweet possono essere inizialmente ordinati in un modo che non aiuterebbe, come ad esempio in ordine alfabetico o per numero di caratteri. E non ci interessa mettere solo tweet che iniziano con ‘Z’ o i più lunghi nel set di test, giusto? Quindi è più sicuro estrarli casualmente.
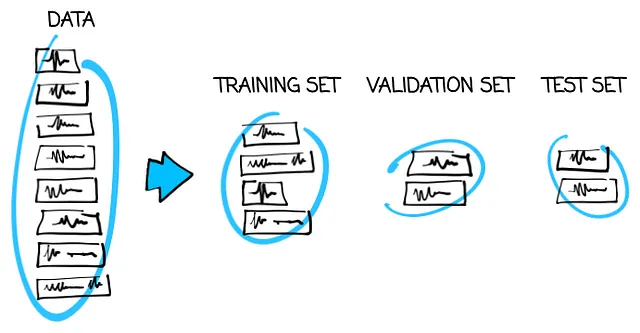
L’ipotesi che i tweet siano completamente casuali è forte. Pensa sempre due volte se è vero. Negli esempi successivi vedrai cosa succede se non lo è.
Esempio 2: non così tanti tweet casuali
Se abbiamo solo 200 tweet completamente casuali in 10 lingue, allora possiamo ancora dividerli casualmente. Ma poi sorge un nuovo rischio. Supponiamo che una lingua sia predominante con 128 tweet e ci siano 8 tweet per ciascuna delle altre 9 lingue. La probabilità dice che la possibilità che non tutte le lingue andranno nel set di test da 50 elementi è superiore al 61% (informazione per i maniaci della matematica: usa il principio di inclusione-esclusione). Ma vogliamo sicuramente testare il modello su tutte e 10 le lingue, quindi abbiamo sicuramente bisogno di tutte nel set di test. Cosa dovremmo fare?
Possiamo estrarre i tweet classe per classe. Quindi prendi la classe predominante di 128 tweet, estrai i 64 tweet per il set di addestramento, 32 per il set di convalida e 32 per il set di test. Fai lo stesso per tutte le altre classi: estrai rispettivamente 4, 2 e 2 tweet per l’addestramento, la convalida e il test per ogni classe. In questo modo, formerai tre set delle dimensioni necessarie, ognuno con tutte le classi nelle stesse proporzioni. Questa strategia è chiamata divisione casuale stratificata.
La suddivisione casuale stratificata sembra migliore/più sicura della suddivisione casuale ordinaria, quindi perché non l’abbiamo usata nell’Esempio 1? Perché non era necessario! Quello che spesso sfugge all’intuizione è che se il 5% su 1.000.000 di tweet è in inglese e ne estraiamo 50.000 senza considerare la lingua, allora il 5% dei tweet estratti sarà anche in inglese. Questo è come funziona la probabilità. Ma la probabilità ha bisogno di numeri abbastanza grandi per funzionare correttamente, quindi se hai 1.000.000 di tweet non ti preoccupi, ma se ne hai solo 200, fai attenzione.
Esempio 3: tweet da varie istituzioni
Ora supponiamo di avere 100.000 tweet, ma provengono solo da 20 istituzioni (diciamo una stazione TV di notizie, un grande club di calcio, ecc.), e ognuna di esse gestisce 10 account Twitter in 10 lingue diverse. E ancora una volta il nostro obiettivo è riconoscere la lingua dei tweet in generale. Possiamo semplicemente usare la suddivisione casuale?
Hai ragione, se potessimo, non lo avremmo chiesto. Ma perché no? Per capirlo, consideriamo prima un caso ancora più semplice: cosa succederebbe se addestrassimo, convalidassimo e testassimo un modello solo su tweet provenienti da un’unica istituzione? Potremmo usarlo su tweet di qualsiasi altra istituzione? Non lo sappiamo! Forse il modello si adatterebbe allo stile unico di tweet di questa istituzione. Non avremmo strumenti per verificarlo!
Torniamo al nostro caso. Il punto è lo stesso. Il numero totale di 20 istituzioni è piuttosto limitato. Quindi, se usiamo dati dalle stesse 20 istituzioni per addestrare, confrontare e valutare i modelli, forse il modello si adatterà troppo ai 20 stili unici di queste 20 istituzioni e fallirà con qualsiasi altro autore. E ancora una volta non c’è modo di verificarlo. Non è buono.
Quindi cosa fare? Seguiamo un’altra regola principale:
I set di convalida e test devono simulare il caso reale a cui il modello verrà applicato nel modo più fedele possibile.
Ora la situazione è più chiara. Dal momento che ci aspettiamo autori diversi nell’applicazione finale rispetto a quelli che abbiamo nei nostri dati, dovremmo avere anche autori diversi nei set di convalida e test rispetto a quelli che abbiamo nel set di addestramento! E il modo per farlo è suddividere i dati per istituzioni! Se estraiamo, ad esempio, 10 istituzioni per il set di addestramento, altre 5 per il set di convalida e mettiamo le ultime 5 nel set di test, il problema è risolto.

Nota che una suddivisione meno rigorosa per istituzione (come mettere l’intera parte di 4 istituzioni e una piccola parte delle altre 16 nel set di test) sarebbe una fuga di dati, il che è sbagliato, quindi dobbiamo essere inflessibili quando si tratta di separare le istituzioni.
Un’ultima nota triste: per una corretta suddivisione di convalida per istituzione, possiamo fidarci della nostra soluzione per i tweet provenienti da diverse istituzioni. Ma i tweet provenienti da account privati possono – e lo fanno – apparire diversi, quindi non possiamo essere sicuri che il modello che abbiamo si comporterà bene per loro. Con i dati che abbiamo, non abbiamo strumenti per verificarlo…
Esempio 4: gli stessi tweet, obiettivo diverso
L’Esempio 3 è difficile, ma se l’hai seguito attentamente questo sarà abbastanza semplice. Quindi, supponiamo di avere esattamente gli stessi dati dell’Esempio 3, ma stavolta l’obiettivo è diverso. Questa volta vogliamo riconoscere la lingua di altri tweet delle stesse 20 istituzioni che abbiamo nei nostri dati. La suddivisione casuale sarà OK adesso?
La risposta è: sì. La suddivisione casuale segue perfettamente l’ultima regola principale sopra indicata poiché siamo interessati solo alle istituzioni che abbiamo nei nostri dati.
Gli Esempi 3 e 4 ci mostrano che il modo in cui dovremmo suddividere i dati non dipende solo dai dati che abbiamo. Dipende sia dai dati che dal compito. Ti preghiamo di tenerlo a mente ogni volta che progetti la suddivisione tra addestramento, convalida e test.
Esempio 5: ancora gli stessi tweet, ma obiettivo diverso
Nell’ultimo esempio manteniamo i dati che abbiamo, ma ora cerchiamo di insegnare a un modello a predire l’istituzione dai futuri tweet. Quindi abbiamo nuovamente un compito di classificazione, ma questa volta con 20 classi poiché abbiamo tweet da 20 istituzioni. Cosa possiamo fare in questo caso? Possiamo suddividere i nostri dati casualmente?
Come prima, pensiamo a un caso più semplice per un po’. Supponiamo di avere solo due istituzioni: una stazione televisiva e un grande club di calcio. Di cosa tweetano? Entrambi amano passare da un argomento caldo a un altro. Tre giorni su Trump o Messi, poi tre giorni su Biden e Ronaldo, e così via. Chiaramente, nei loro tweet possiamo trovare parole chiave che cambiano ogni paio di giorni. E quali parole chiave vedremo in un mese? Quale politico o cattivo o calciatore o allenatore di calcio sarà “caldo” allora? Possibilmente uno che al momento è completamente sconosciuto. Quindi se vuoi imparare a riconoscere l’istituzione, non dovresti concentrarti su parole chiave temporanee, ma piuttosto cercare di cogliere lo stile generale.
OK, torniamo alle nostre 20 istituzioni. La precedente osservazione rimane valida: gli argomenti dei tweet cambiano nel tempo, quindi se vogliamo che la nostra soluzione funzioni per i futuri tweet, non dovremmo concentrarci su parole chiave di breve durata. Ma un modello di apprendimento automatico è pigro. Se trova un modo facile per portare a termine il compito, non guarda oltre. E attenersi alle parole chiave è proprio un modo facile. Quindi come possiamo verificare se il modello ha imparato correttamente o ha semplicemente memorizzato le parole chiave temporanee?
Siamo abbastanza sicuri che tu realizzi che se usi la suddivisione casuale, dovresti aspettarti tweet su ogni eroe della settimana in tutti e tre i set. In questo modo, ti ritrovi con le stesse parole chiave nei set di addestramento, validazione e test. Questo non è quello che vorremmo avere. Dobbiamo suddividere in modo più intelligente. Ma come?
Quando torniamo all’ultima regola principale, diventa facile. Vogliamo utilizzare la nostra soluzione in futuro, quindi i set di validazione e test dovrebbero essere il futuro rispetto al set di addestramento! Dovremmo suddividere i dati in base al tempo. Quindi se abbiamo, ad esempio, 12 mesi di dati – da luglio 2022 a giugno 2023 – mettere luglio 2022 – aprile 2023 nel set di test, maggio 2023 nel set di validazione e giugno 2023 nel set di test dovrebbe fare il lavoro.

Forse ti preoccupa che con la suddivisione in base al tempo non verifichiamo la qualità del modello nel corso delle stagioni. Hai ragione, è un problema. Ma comunque un problema più piccolo rispetto a quello che otterremmo se suddividessimo casualmente. Puoi considerare anche, ad esempio, la seguente suddivisione: dal 1° al 20° di ogni mese nel set di addestramento, dal 20° al 25° di ogni mese nel set di validazione, dal 25° alla fine di ogni mese nel set di test. In ogni caso, scegliere una strategia di validazione è un compromesso tra possibili falle nei dati. Finché lo capisci e scegli consapevolmente l’opzione più sicura, stai facendo bene.
Sommario
Ambientiamo la nostra storia su un’isola deserta e cerchiamo di evitare qualsiasi complessità, isolando il problema della validazione e del test del modello da tutte le possibili considerazioni del mondo reale. Anche così, ci siamo imbattuti in trappola dopo trappola. Fortunatamente, le regole per evitarle sono facili da imparare. Come scoprirai lungo il cammino, sono anche difficili da padroneggiare. Non sempre noterai immediatamente la fuga di dati. E non sarai sempre in grado di prevenirla. Tuttavia, una considerazione attenta della credibilità del tuo schema di validazione porterà a modelli migliori. Questo è qualcosa che rimane rilevante anche quando vengono inventati nuovi modelli e rilasciati nuovi framework.
Inoltre, abbiamo 1000 uomini bloccati su isole deserte. Un buon modello potrebbe essere proprio ciò di cui abbiamo bisogno per salvarli tempestivamente.






