Incontra MultiDiffusion Un framework AI unificato che consente la generazione di immagini versatile e controllabile utilizzando un modello di diffusione testo-immagine pre-addestrato.
Incontra MultiDiffusion un framework AI versatile per la generazione controllabile di immagini utilizzando un modello di diffusione testo-immagine pre-addestrato.


Anche se i modelli di diffusione sono ora considerati all’avanguardia, i modelli generativi di testo-immagine sono emersi come una “tecnologia rivoluzionaria” che mostra abilità precedentemente inaudite nella creazione di immagini di alta qualità e diverse da prompt di testo. La capacità di dare agli utenti un controllo intuitivo sul materiale creato rimane una sfida per i modelli di testo-immagine, anche se questo avanzamento offre un potenziale significativo per trasformare il modo in cui creano contenuti digitali.
Attualmente, esistono due tecniche per regolare i modelli di diffusione: (i) addestrare un modello da zero o (ii) raffinare un modello di diffusione esistente per il compito in questione. Anche in uno scenario di raffinamento, questa strategia richiede spesso un notevole calcolo e un lungo periodo di sviluppo a causa del volume sempre crescente di modelli e dati di addestramento. (ii) Riutilizzare un modello che è già stato addestrato e aggiungere alcune capacità di generazione controllata. Alcune tecniche si sono concentrate in precedenza su compiti specifici e hanno creato una metodologia specializzata. Questo studio mira a generare MultiDiffusion, un nuovo framework unificato che migliora notevolmente l’adattabilità di un modello di diffusione pre-addestrato (di riferimento) alla produzione controllata di immagini.

Lo scopo fondamentale di MultiDiffusion è progettare un nuovo processo di generazione che comprenda diversi processi di generazione di diffusione di riferimento uniti da un insieme comune di caratteristiche o vincoli. Le varie aree dell’immagine risultante sono sottoposte al modello di diffusione di riferimento, che prevede in modo più specifico un passaggio di campionamento di denoising per ciascuna. MultiDiffusion quindi esegue un passaggio di campionamento di denoising globale, utilizzando la soluzione migliore dei minimi quadrati, per conciliare tutte queste fasi separate. Prendiamo ad esempio la sfida di creare un’immagine con qualsiasi rapporto di aspetto utilizzando un modello di diffusione di riferimento addestrato su immagini quadrate (vedi Figura 2 di seguito).
- Come dovresti convalidare i modelli di apprendimento automatico
- Tendenze delle startup di intelligenza artificiale Insights dall’ultima selezione di Y Combinator
- Google AI presenta SimPer un framework contrastivo auto-supervisionato per apprendere informazioni periodiche nei dati
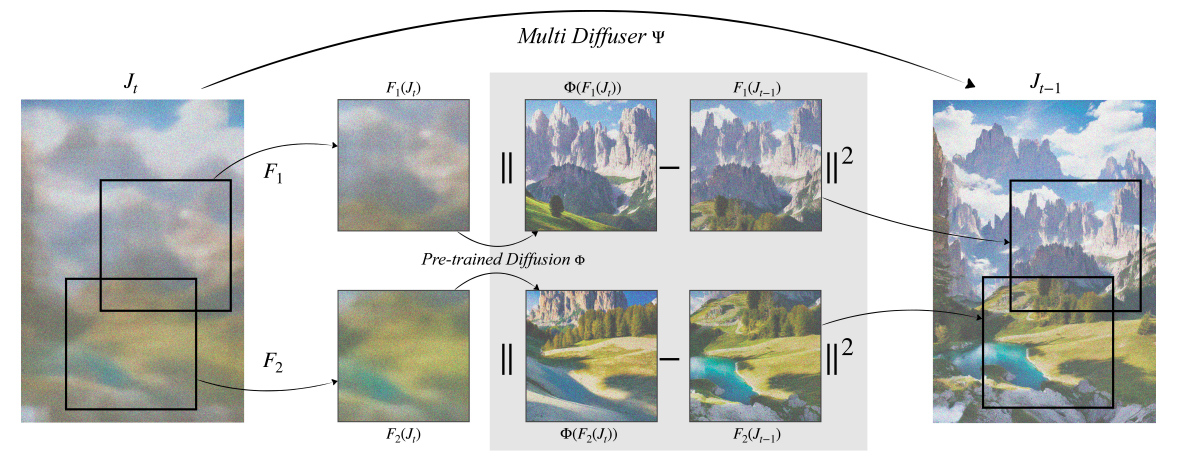
MultiDiffusion unisce le direzioni di denoising di tutti i ritagli quadrati che il modello di riferimento fornisce in ogni fase del processo di denoising. Cerca di seguirli tutti nel modo più fedele possibile, ostacolato dai ritagli adiacenti che condividono pixel comuni. Sebbene ogni ritaglio possa tirare in una direzione diversa per il denoising, va notato che il loro framework produce una singola fase di denoising, producendo immagini di alta qualità e senza soluzione di continuità. Ogni ritaglio dovrebbe rappresentare un vero campione del modello di riferimento.
Utilizzando MultiDiffusion, è possibile applicare un modello di testo-immagine di riferimento pre-addestrato a una varietà di compiti, come la generazione di immagini con una risoluzione o un rapporto di aspetto specifico o la generazione di immagini da prompt di testo illeggibili basati su regioni, come mostrato in Fig. 1. In modo significativo, la loro architettura consente la risoluzione simultanea di entrambi i compiti utilizzando un processo di sviluppo condiviso. Hanno scoperto che la loro metodologia può raggiungere una qualità di generazione controllata all’avanguardia anche confrontandola con approcci appositamente addestrati per questi compiti mediante il confronto con basi di riferimento pertinenti. Inoltre, il loro approccio funziona in modo efficace senza aggiungere un onere computazionale. La base di codice completa sarà presto rilasciata sulla loro pagina di Github. È inoltre possibile vedere ulteriori demo sulla loro pagina del progetto.






