Questo articolo su AI dell’NTU Singapore presenta MeVIS una benchmark su larga scala per la segmentazione video con espressioni di movimento
This article from NTU Singapore presents MeVIS, a large-scale benchmark for video segmentation with motion expressions.


La segmentazione dei video guidata dal linguaggio è un dominio in sviluppo che si concentra sulla segmentazione e sul tracciamento di oggetti specifici nei video utilizzando descrizioni in linguaggio naturale. Attualmente, i dataset per il riferimento agli oggetti nei video enfatizzano generalmente gli oggetti prominenti e si basano su espressioni linguistiche con molte attributi statici. Questi attributi permettono di identificare l’oggetto target in un solo frame. Tuttavia, questi dataset trascurano l’importanza del movimento nella segmentazione degli oggetti video guidata dal linguaggio.

I ricercatori hanno introdotto MeVIS, un nuovo dataset su larga scala chiamato Motion Expression Video Segmentation (MeViS), per aiutare la nostra indagine. Il dataset MeViS comprende 2.006 video con 8.171 oggetti e vengono fornite 28.570 espressioni di movimento per riferirsi a questi oggetti. Le immagini sopra mostrano le espressioni in MeViS che si concentrano principalmente sugli attributi di movimento, e l’oggetto target riferito non può essere identificato esaminando un singolo frame. Ad esempio, il primo esempio presenta tre pappagalli con aspetto simile, e l’oggetto target è identificato come “L’uccello che vola via”. Questo oggetto può essere riconosciuto solo catturando il suo movimento lungo tutto il video.
Alcuni passaggi assicurano che il dataset MeVIS enfatizzi i movimenti temporali dei video.
- Google presenta MediaPipe per Raspberry Pi con un SDK Python facile da usare per il machine learning su dispositivo
- Come aiutare gli studenti delle scuole superiori a prepararsi all’avvento dell’intelligenza artificiale
- Il mito dell’AI ‘Open Source
In primo luogo, il contenuto video viene selezionato attentamente e contiene oggetti multipli che coesistono con il movimento, escludendo i video con oggetti isolati che possono essere descritti facilmente da attributi statici.
In secondo luogo, vengono dati priorità alle espressioni linguistiche che non contengono indizi statici, come nomi di categorie o colori degli oggetti, nei casi in cui gli oggetti target possono essere descritti in modo univoco solo da parole di movimento.
Oltre a proporre il dataset MeViS, i ricercatori presentano anche un approccio di base, chiamato Language-guided Motion Perception and Matching (LMPM), per affrontare le sfide poste da questo dataset. Il loro approccio coinvolge la generazione di query condizionate al linguaggio per identificare potenziali oggetti target all’interno del video. Questi oggetti sono poi rappresentati utilizzando embedding di oggetti, che sono più robusti ed efficienti computazionalmente rispetto alle mappe di caratteristiche degli oggetti. I ricercatori applicano il Perception del Movimento a questi embedding di oggetti per catturare il contesto temporale ed avere una comprensione globale della dinamica del movimento del video. Ciò consente al loro modello di cogliere sia i movimenti momentanei che quelli prolungati presenti nel video.
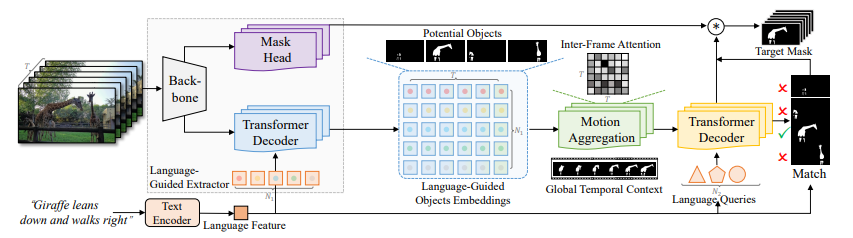
L’immagine sopra mostra l’architettura di LMLP. Utilizzano un decoder Transformer per interpretare il linguaggio dai combined object embeddings influenzati dal movimento. Ciò aiuta a prevedere i movimenti degli oggetti. Successivamente, confrontano le caratteristiche linguistiche con i movimenti degli oggetti proiettati per trovare l’oggetto/i target menzionato/i nelle espressioni. Questo metodo innovativo unisce la comprensione del linguaggio e la valutazione del movimento per gestire efficacemente il complesso compito del dataset.
Questa ricerca ha fornito una base per lo sviluppo di algoritmi più avanzati di segmentazione video guidata dal linguaggio. Ha aperto strade in direzioni più sfidanti, come:
- Esplorare nuove tecniche per una migliore comprensione e modellazione del movimento nelle modalità visuali e linguistiche.
- Creare modelli più efficienti che riducano il numero di oggetti rilevati ridondanti.
- Progettare metodi efficaci di fusione cross-modale per sfruttare le informazioni complementari tra il linguaggio e i segnali visuali.
- Sviluppare modelli avanzati in grado di gestire scene complesse con oggetti ed espressioni diverse.
Affrontare queste sfide richiede ricerca per far progredire lo stato attuale dell’arte nel campo della segmentazione video guidata dal linguaggio.






