Scopri i segreti per scegliere l’algoritmo di Machine Learning perfetto!
Scegli l'algoritmo di ML perfetto!
Una delle decisioni chiave che devi prendere quando risolvi un problema di data science è quale algoritmo di machine learning utilizzare.
Ci sono centinaia di algoritmi di machine learning tra cui scegliere, ognuno con i propri vantaggi e svantaggi. Alcuni algoritmi possono funzionare meglio di altri su tipi specifici di problemi o su specifici set di dati.
Il teorema del “No Free Lunch” (NFL) afferma che non esiste un algoritmo che funzioni meglio per ogni problema, o in altre parole, tutti gli algoritmi hanno le stesse prestazioni quando le loro prestazioni vengono mediamente calcolate su tutti i possibili problemi.
- Jasper Vs. Scalenut Quale strumento di scrittura è il migliore? (luglio 2023)
- Come sfruttare l’IA generativa per sviluppare strategie Go-to-Market globali, agili ed efficaci
- La ricerca sull’IA presso il CNRS francese propone un meta-imager programmabile intelligentemente adattativo al rumore un approccio tempestivo al rilevamento specifico del compito e adattivo al rumore
In questo articolo, discuteremo i principali aspetti da considerare quando si sceglie un modello per il tuo problema e come confrontare diversi algoritmi di machine learning.
Aspetti chiave degli algoritmi
L’elenco seguente contiene 10 domande che potresti farti quando consideri un algoritmo di machine learning specifico:
- Quali tipi di problemi può risolvere l’algoritmo? L’algoritmo può risolvere solo problemi di regressione o classificazione, o può risolvere entrambi? Può gestire problemi multi-classe/multi-label o solo problemi di classificazione binaria?
- L’algoritmo ha delle ipotesi sul set di dati? Ad esempio, alcuni algoritmi assumono che i dati siano linearmente separabili (ad esempio, perceptron o SVM lineari), mentre altri assumono che i dati siano distribuiti normalmente (ad esempio, Gaussian Mixture Models).
- Ci sono delle garanzie sulle prestazioni dell’algoritmo? Ad esempio, se l’algoritmo cerca di risolvere un problema di ottimizzazione (come nella regressione logistica o nelle reti neurali), è garantito trovare il minimo globale o solo una soluzione di minimo locale?
- Quanti dati sono necessari per addestrare il modello in modo efficace? Alcuni algoritmi, come le reti neurali profonde, sono più intelligenti nel trattare i dati rispetto ad altri.
- L’algoritmo tende a fare overfitting? In caso affermativo, l’algoritmo fornisce modi per gestire l’overfitting?
- Quali sono i requisiti di tempo di esecuzione e memoria dell’algoritmo, sia durante l’addestramento che durante la fase di previsione?
- Quali sono le fasi di pre-elaborazione dei dati richieste per preparare i dati per l’algoritmo?
- Quanti iperparametri ha l’algoritmo? Gli algoritmi con molti iperparametri richiedono più tempo per l’addestramento e l’ottimizzazione.
- È possibile interpretare facilmente i risultati dell’algoritmo? In molti domini di problema (come la diagnosi medica), vorremmo essere in grado di spiegare le previsioni del modello in termini umani. Alcuni modelli possono essere facilmente visualizzati (come gli alberi decisionali), mentre altri si comportano come una scatola nera (ad esempio, le reti neurali).
- L’algoritmo supporta l’apprendimento online (incrementale), cioè possiamo addestrarlo su campioni aggiuntivi senza dover ricostruire il modello da zero?
Esempio di confronto tra algoritmi
Per esempio, prendiamo due degli algoritmi più popolari: alberi decisionali e reti neurali, e li confrontiamo secondo i criteri sopra citati.
Alberi Decisionali
- Gli alberi decisionali possono gestire sia problemi di classificazione che di regressione. Possono anche gestire facilmente problemi multi-classe e multi-label.
- Gli algoritmi degli alberi decisionali non hanno ipotesi specifiche sul set di dati.
- Un albero decisionale viene costruito utilizzando un algoritmo greedy, che non è garantito di trovare l’albero ottimale (ossia l’albero che minimizza il numero di test necessari per classificare correttamente tutti i campioni di addestramento). Tuttavia, un albero decisionale può raggiungere un’accuratezza del 100% sul set di addestramento se estendiamo i suoi nodi fino a quando tutti i campioni nei nodi foglia appartengono alla stessa classe. Tali alberi di solito non sono buoni predittori, in quanto fanno overfitting del rumore nel set di addestramento.
- Gli alberi decisionali possono funzionare bene anche su set di dati di piccole dimensioni o di dimensioni VoAGI.
- Gli alberi decisionali possono facilmente fare overfitting. Tuttavia, possiamo ridurre l’overfitting utilizzando la potatura degli alberi. Possiamo anche utilizzare metodi di insieme come le foreste casuali che combinano l’output di più alberi decisionali. Questi metodi soffrono meno di overfitting.
- Il tempo di costruzione di un albero decisionale è O(n²p), dove n è il numero di campioni di addestramento e p è il numero di caratteristiche. Il tempo di previsione negli alberi decisionali dipende dall’altezza dell’albero, che di solito è logaritmica in n, dal momento che la maggior parte degli alberi decisionali è abbastanza bilanciata.
- Gli alberi decisionali non richiedono alcuna pre-elaborazione dei dati. Possono gestire senza problemi diversi tipi di caratteristiche, inclusi caratteristiche numeriche e categoriche. Inoltre, non richiedono la normalizzazione dei dati.
- Gli alberi decisionali hanno diversi iperparametri chiave che devono essere ottimizzati, specialmente se si utilizza la potatura, come la profondità massima dell’albero e la misura dell’impurità da utilizzare per decidere come dividere i nodi.
- Gli alberi decisionali sono semplici da capire e interpretare, e possiamo visualizzarli facilmente (a meno che l’albero non sia molto grande).
- Gli alberi decisionali non possono essere facilmente modificati per tener conto di nuovi campioni di addestramento, poiché piccoli cambiamenti nel set di dati possono causare grandi cambiamenti nella topologia dell’albero.
Reti neurali
- Le reti neurali sono uno dei modelli di apprendimento automatico più generali e flessibili che esistono. Possono risolvere quasi ogni tipo di problema, inclusa la classificazione, la regressione, l’analisi delle serie temporali, la generazione automatica di contenuti, ecc.
- Le reti neurali non fanno assumzioni sul set di dati, ma i dati devono essere normalizzati.
- Le reti neurali vengono addestrate utilizzando la discesa del gradiente. Pertanto, possono trovare solo una soluzione ottimale locale. Tuttavia, ci sono varie tecniche che possono essere utilizzate per evitare di rimanere bloccati in minimi locali, come l’inerzia e i tassi di apprendimento adattivi.
- Le reti neurali profonde richiedono molti dati per addestrarsi nell’ordine dei milioni di punti di campione. In generale, più grande è la rete (più strati e neuroni ha), più dati abbiamo bisogno per addestrarla.
- Le reti troppo grandi potrebbero memorizzare tutti i campioni di addestramento e non generalizzare bene. Per molti problemi, è possibile partire da una rete piccola (ad esempio, con uno o due strati nascosti) e aumentare gradualmente la sua dimensione fino a quando non si inizia ad adattarsi troppo al set di addestramento. È anche possibile aggiungere regolarizzazione per gestire l’overfitting.
- Il tempo di addestramento di una rete neurale dipende da molti fattori (la dimensione della rete, il numero di iterazioni della discesa del gradiente necessarie per addestrarla, ecc.). Tuttavia, il tempo di previsione è molto veloce poiché abbiamo solo bisogno di fare un passaggio in avanti sulla rete per ottenere l’etichetta.
- Le reti neurali richiedono che tutte le caratteristiche siano numeriche e normalizzate.
- Le reti neurali hanno molti iperparametri che devono essere regolati, come il numero di strati, il numero di neuroni in ciascuno strato, quale funzione di attivazione utilizzare, il tasso di apprendimento, ecc.
- Le previsioni delle reti neurali sono difficili da interpretare poiché si basano sul calcolo di un gran numero di neuroni, ognuno dei quali contribuisce solo in piccola parte alla previsione finale.
- Le reti neurali possono facilmente adattarsi per includere campioni di addestramento aggiuntivi, in quanto utilizzano un algoritmo di apprendimento incrementale (discesa del gradiente stocastica).
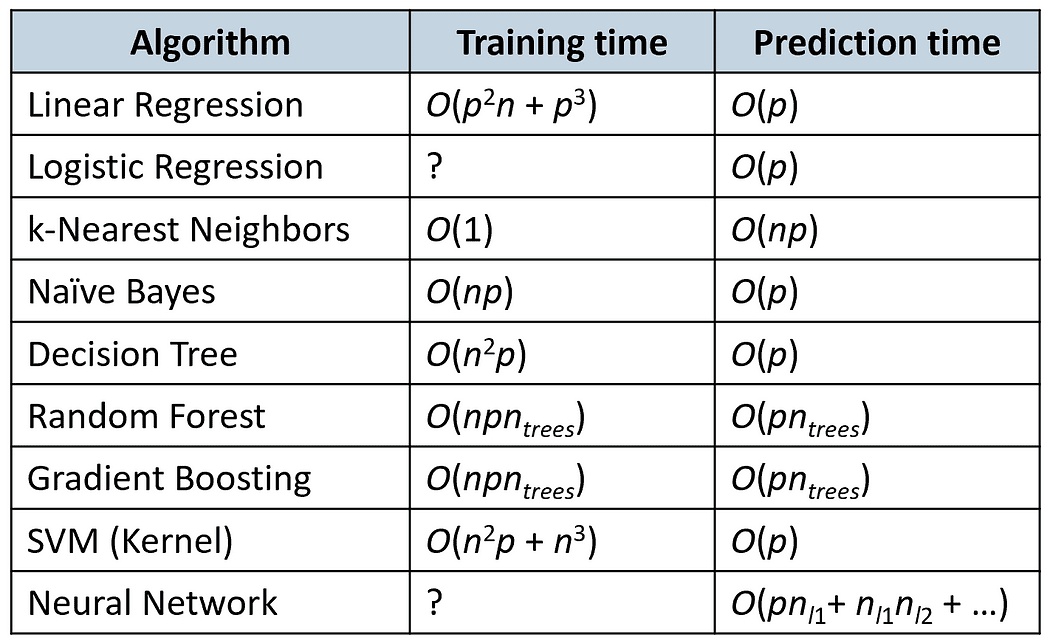
Complessità temporale
La seguente tabella confronta i tempi di addestramento e di previsione di alcuni algoritmi popolari (n è il numero di campioni di addestramento e p è il numero di caratteristiche).
Algoritmi di maggior successo nelle competizioni Kaggle
Secondo un sondaggio condotto nel 2016, gli algoritmi più frequentemente utilizzati dai vincitori delle competizioni Kaggle erano gli algoritmi di boosting del gradiente (XGBoost) e le reti neurali (vedi questo articolo).
Dei 29 vincitori delle competizioni Kaggle nel 2015, 8 hanno utilizzato XGBoost, 9 hanno utilizzato reti neurali profonde e 11 hanno utilizzato un insieme di entrambi.
XGBoost è stato principalmente utilizzato in problemi che riguardavano dati strutturati (ad esempio, tabelle relazionali), mentre le reti neurali sono state più efficaci nel gestire problemi non strutturati (ad esempio, problemi che riguardano immagini, voce o testo).
Sarebbe interessante verificare se questa è ancora la situazione oggi o se le tendenze sono cambiate (qualcuno è pronto per la sfida?)
Grazie per aver letto!
Dr. Roi Yehoshua è un professore di insegnamento presso la Northeastern University di Boston, dove insegna corsi che compongono il programma di laurea in Data Science. Le sue ricerche sui sistemi multi-robot e sull’apprendimento per rinforzo sono state pubblicate sulle principali riviste e conferenze nel campo dell’IA. È anche un autore di punta sulla piattaforma sociale VoAGI, dove pubblica frequentemente articoli su Data Science e Machine Learning.
Originale. Ripubblicato con il permesso.




