RL Non Collegato Benchmark per l’Apprendimento Rinforzato Offline
RL Benchmark per l'Apprendimento Rinforzato Offline

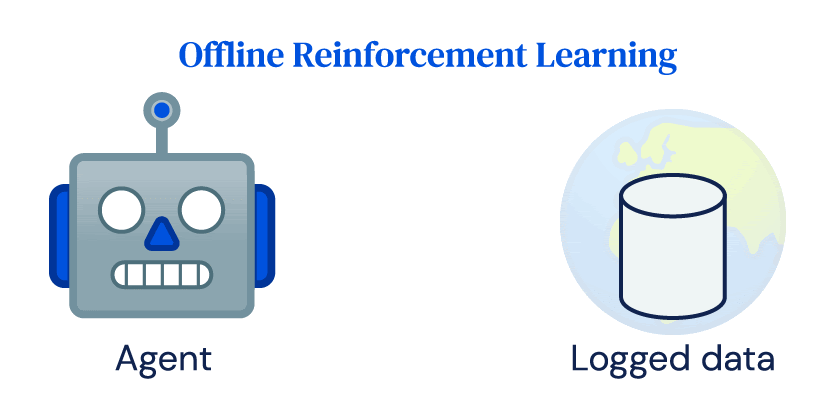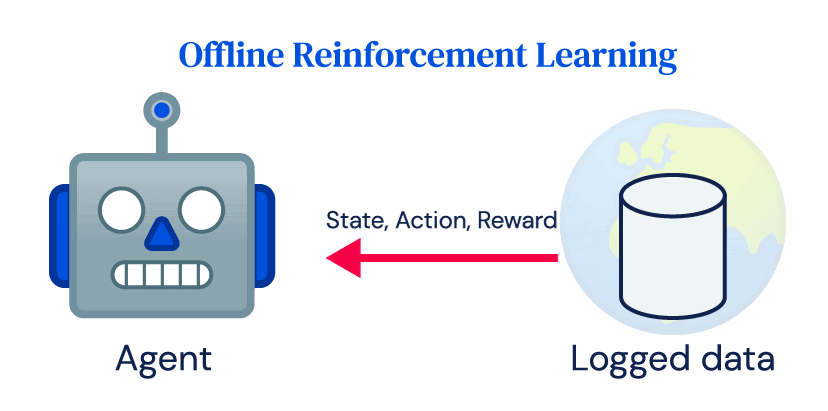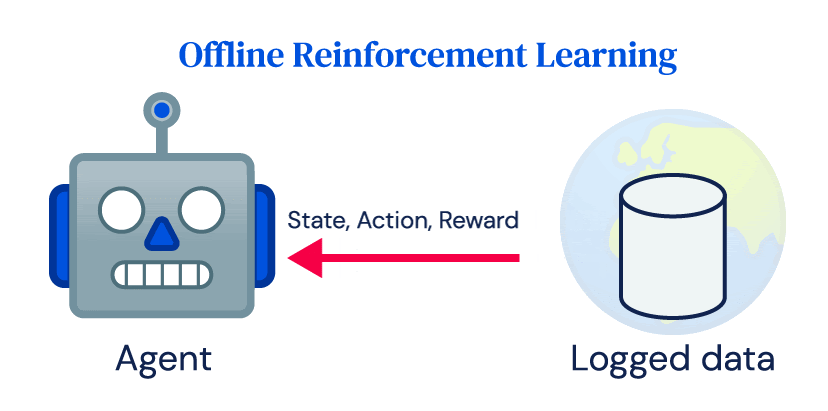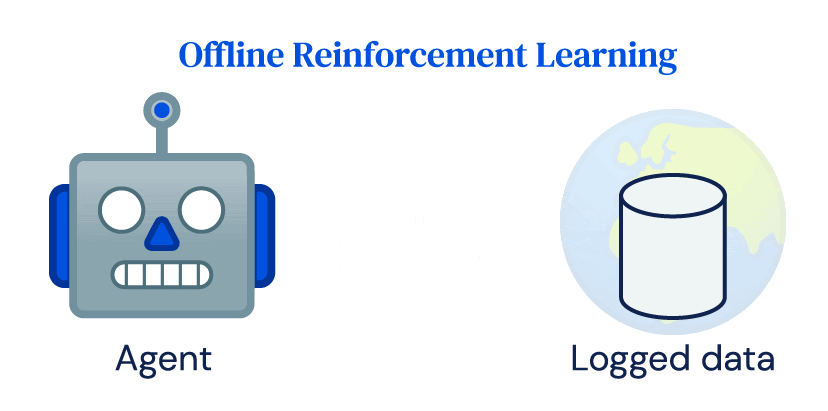
Molte delle vittorie dell’apprendimento rinforzato dipendono fortemente dalle interazioni online ripetute di un agente con un ambiente, che chiamiamo apprendimento rinforzato online. Nonostante il suo successo nella simulazione, l’adozione dell’apprendimento rinforzato per le applicazioni reali è stata limitata. Le centrali elettriche, i robot, i sistemi sanitari o le auto a guida autonoma sono costosi da gestire e i controlli inappropriati possono avere conseguenze pericolose. Non sono facilmente compatibili con l’idea cruciale di esplorazione nell’apprendimento rinforzato e con i requisiti di dati degli algoritmi di apprendimento rinforzato online. Tuttavia, la maggior parte dei sistemi reali produce grandi quantità di dati come parte del loro normale funzionamento, e l’obiettivo dell’apprendimento rinforzato offline è imparare una politica direttamente da quei dati registrati senza interagire con l’ambiente.
I metodi di apprendimento rinforzato offline (ad esempio Agarwal et al., 2020; Fujimoto et al., 2018) hanno mostrato risultati promettenti in domini di benchmark ben noti. Tuttavia, protocolli di valutazione non standardizzati, dataset diversi e mancanza di basi rendono difficili i confronti algoritmici. Tuttavia, alcune importanti proprietà di potenziali domini di applicazioni reali come l’osservabilità parziale, i flussi sensoriali ad alta dimensione (ad esempio le immagini), gli spazi di azione diversi, i problemi di esplorazione, la non stazionarietà e la stocasticità, sono sottorappresentate nella letteratura corrente sull’apprendimento rinforzato offline.
- Previsione del traffico con avanzati Graph Neural Networks
- Apprendimento automatico rapido tramite la composizione di comportamenti
- FermiNet Fisica Quantistica e Chimica dalle Prime Principî
[INSERISCI GIF + DIDASCALIA]
Introduciamo una nuova collezione di domini di attività e dataset associati insieme a un protocollo di valutazione chiaro. Includiamo domini ampiamente utilizzati come DM Control Suite (Tassa et al., 2018) e giochi Atari 2600 (Bellemare et al., 2013), ma anche domini che sono ancora una sfida per algoritmi di apprendimento rinforzato online potenti come i compiti della suite di apprendimento rinforzato del mondo reale (RWRL) (Dulac-Arnold et al., 2020) e i compiti di locomozione DM (Heess et al., 2017; Merel et al., 2019a,b, 2020). Standardizzando gli ambienti, i dataset e i protocolli di valutazione, speriamo di rendere la ricerca sull’apprendimento rinforzato offline più riproducibile e accessibile. Chiamiamo la nostra suite di benchmark “RL Unplugged”, perché i metodi di apprendimento rinforzato offline possono utilizzarla senza che attori interagiscano con l’ambiente. Il nostro articolo offre quattro contributi principali: (i) un’API unificata per i dataset (ii) un insieme vario di ambienti (iii) protocolli di valutazione chiari per la ricerca sull’apprendimento rinforzato offline e (iv) basi di prestazioni di riferimento.






