Richiedi i tuoi documenti con Langchain e Deep Lake!
Richiedi i tuoi documenti con Langchain e Deep Lake!' can be condensed to 'Richiedi i tuoi documenti con Langchain e Deep Lake!
Introduzione
I modelli di linguaggio di grandi dimensioni come langchain e deep lake hanno fatto molti progressi nella domanda e risposta sui documenti e nell’indicizzazione delle informazioni. Questi modelli sanno molto del mondo, ma a volte faticano a capire quando non sanno qualcosa. Ciò li porta ad inventare delle cose per colmare le lacune, il che non è ottimale.

Tuttavia, un nuovo metodo chiamato Retrieval Augmented Generation (RAG) sembra promettente. Utilizza RAG per interrogare un LLM con la tua base di conoscenza privata. Aiuta questi modelli a migliorare aggiungendo informazioni extra dalle loro fonti di dati. Questo li rende più innovativi e riduce gli errori quando non hanno abbastanza informazioni.
RAG funziona migliorando le istruzioni con dati proprietari, migliorando così la conoscenza di questi grandi modelli di linguaggio riducendo contemporaneamente la comparsa di allucinazioni.
- Crea meme con il plugin ChatGPT Meme Creator (per far crescere la tua attività)
- Intelligenza Artificiale e l’Estetica della Generazione di Immagini
- Estrazione degli argomenti dei documenti con modelli linguistici di grandi dimensioni (LLM) e l’algoritmo di allocazione latente di Dirichlet (LDA)
Obiettivi di apprendimento
1. Comprensione dell’approccio RAG e dei suoi benefici
2. Riconoscere le sfide nella domanda e risposta sui documenti
3. Differenza tra generazione semplice e generazione arricchita da recupero
4. Implementazione pratica di RAG su un caso d’uso industriale come Doc-QnA
Alla fine di questo articolo di apprendimento, dovresti avere una solida comprensione del Retrieval Augmented Generation (RAG) e della sua applicazione nel migliorare le prestazioni dei LLM nella domanda e risposta sui documenti e nell’indicizzazione delle informazioni.
Questo articolo è stato pubblicato come parte del Data Science Blogathon.
Iniziare
Riguardo alla domanda e risposta sui documenti, l’ideale è fornire al modello le informazioni specifiche di cui ha bisogno proprio quando viene posta una domanda. Tuttavia, decidere quali informazioni sono rilevanti può essere complicato e dipende da ciò che ci si aspetta che il grande modello di linguaggio faccia. Ecco dove diventa importante il concetto di RAG.
Vediamo come funziona una pipeline RAG:
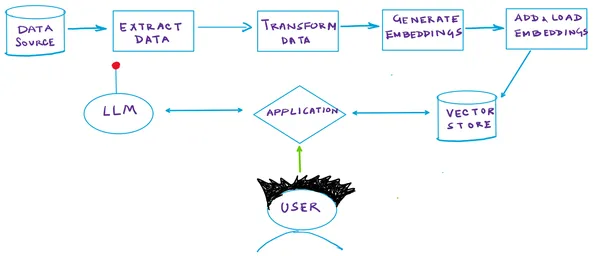
Generazione Arricchita da Recupero
RAG, un’architettura di intelligenza artificiale generativa all’avanguardia, utilizza la similarità semantica per identificare informazioni pertinenti in risposta alle query in modo autonomo. Ecco una breve descrizione di come funziona RAG:
- Database Vettoriale: In un sistema RAG, i tuoi documenti sono archiviati all’interno di un database vettoriale specializzato. Ogni documento viene indicizzato in base a un vettore semantico generato da un modello di incorporamento. Questo approccio consente il recupero rapido dei documenti strettamente correlati a un determinato vettore di query. Ad ogni documento viene assegnata una rappresentazione numerica (il vettore), che ne indica il significato semantico.
- Generazione di Vettori di Query: Quando viene inviata una query, lo stesso modello di incorporamento produce un vettore semantico che rappresenta la query.
- Ricerca basata su Vettori: Successivamente, il modello utilizza la ricerca vettoriale per identificare i documenti nel database che presentano vettori strettamente allineati con il vettore della query. Questo passaggio è cruciale per individuare i documenti più rilevanti.
- Generazione di Risposte: Dopo aver recuperato i documenti pertinenti, il modello li utilizza insieme alla query per generare una risposta. Questa strategia permette al modello di accedere ai dati esterni precisamente quando necessario, arricchendo la sua conoscenza interna.
L’illustrazione
L’illustrazione sottostante riassume tutti i passaggi discussi in precedenza:
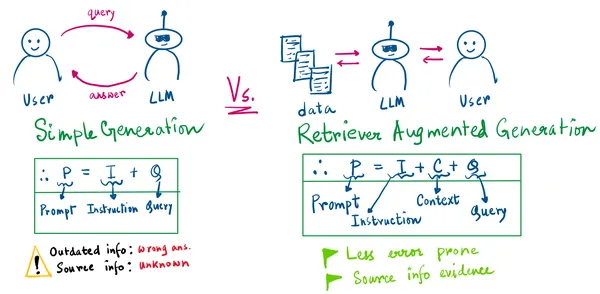
Dal disegno sopra, ci sono 2 cose importanti da evidenziare:
- Nella generazione semplice, non sapremo mai le informazioni di origine.
- La generazione semplice può portare alla generazione di informazioni errate quando il modello è obsoleto o la sua conoscenza è precedente alla domanda posta.
Con l’approccio RAG, la nostra istruzione per il LLM sarà composta da noi, dal contesto recuperato e dalla query dell’utente. Ora abbiamo una prova delle informazioni recuperate.
Quindi, invece di affrontare l’incertezza di riallenare il pipeline più volte in uno scenario di informazioni in costante cambiamento, è possibile aggiungere informazioni aggiornate ai tuoi store di vettori/store di dati. L’utente può tornare la prossima volta e fare domande simili le cui risposte sono ora cambiate (prendi ad esempio alcuni record finanziari di una società XYZ). Sei pronto.
Spero che questo rinfreschi la tua mente su come funziona RAG. Ora, passiamo al punto. Sì, il codice.
So che non sei venuto qui per le chiacchiere. 👻
Andiamo alla parte interessante!
1: Creazione della Struttura del Progetto VSCode
Apri VSCode o il tuo editor di codice preferito e crea una directory di progetto come segue (seguendo attentamente la struttura delle cartelle) –
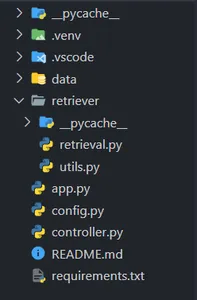
Ricorda di creare un ambiente virtuale con Python ≥ 3.9 e di installare le dipendenze nel file requirements.txt. (Non preoccuparti, condividerò il link GitHub per le risorse.)
2: Creazione di una Classe per le Operazioni di Recupero e Incorporamento
Nel file controller.py, incolla il codice qui sotto e salvalo.
from retriever.retrieval import Retriever
# Crea una classe Controller per gestire l'incorporamento e il recupero dei documenti
class Controller:
def __init__(self):
self.retriever = None
self.query = ""
def embed_document(self, file):
# Incorpora un documento se viene fornito il parametro 'file'
if file is not None:
self.retriever = Retriever()
# Crea e aggiungi incorporamenti per il documento fornito
self.retriever.create_and_add_embeddings(file.name)
def retrieve(self, query):
# Recupera il testo in base alla query dell'utente
texts = self.retriever.retrieve_text(query)
return texts Questa è una classe di supporto per creare un oggetto del nostro Retriever. Implementa due funzioni:
embed_document: genera gli incorporamenti del documento
retrieve: recupera il testo quando l’utente fa una query
In seguito, approfondiremo le funzioni helper create_and_add_embeddings e retrieve_text nel nostro Retriever!
3: Programmazione della nostra Pipeline di Recupero!
Nel file retrieval.py, incolla il codice qui sotto e salvalo.
3.1: Importa le librerie e i moduli necessari
import os
from langchain import PromptTemplate
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores.deeplake import DeepLake
from langchain.document_loaders import TextLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain.document_loaders import PyMuPDFLoader
from langchain.chat_models.openai import ChatOpenAI
from langchain.chains import RetrievalQA
from langchain.memory import ConversationBufferWindowMemory
from .utils import save
import config as cfg3.2: Inizializza la Classe Retriever
# Definisci la classe Retriever
class Retriever:
def __init__(self):
self.text_retriever = None
self.text_deeplake_schema = None
self.embeddings = None
self.memory = ConversationBufferWindowMemory(k=2, return_messages=True)csv3.3: Scriviamo il codice per creare e aggiungere gli incorporamenti dei documenti a Deep Lake
def create_and_add_embeddings(self, file):
# Crea una directory chiamata "data" se non esiste già
os.makedirs("data", exist_ok=True)
# Inizializza gli incorporamenti usando OpenAIEmbeddings
self.embeddings = OpenAIEmbeddings(
openai_api_key=cfg.OPENAI_API_KEY,
chunk_size=cfg.OPENAI_EMBEDDINGS_CHUNK_SIZE,
)
# Carica i documenti dal file fornito utilizzando PyMuPDFLoader
loader = PyMuPDFLoader(file)
documents = loader.load()
# Suddivide il testo in blocchi utilizzando CharacterTextSplitter
text_splitter = CharacterTextSplitter(
chunk_size=cfg.CHARACTER_SPLITTER_CHUNK_SIZE,
chunk_overlap=0,
)
docs = text_splitter.split_documents(documents)
# Crea uno schema DeepLake per i documenti di testo
self.text_deeplake_schema = DeepLake(
dataset_path=cfg.TEXT_VECTORSTORE_PATH,
embedding_function=self.embeddings,
overwrite=True,
)
# Aggiungi i documenti suddivisi allo schema DeepLake
self.text_deeplake_schema.add_documents(docs)
# Crea un recuperatore di testo dallo schema DeepLake con tipo di ricerca "similarità"
self.text_retriever = self.text_deeplake_schema.as_retriever(
search_type="similarity"
)
# Configura i parametri di ricerca per il recuperatore di testo
self.text_retriever.search_kwargs["distance_metric"] = "cos"
self.text_retriever.search_kwargs["fetch_k"] = 15
self.text_retriever.search_kwargs["maximal_marginal_relevance"] = True
self.text_retriever.search_kwargs["k"] = 33.4: Ora, codifichiamo la funzione che recupererà il testo!
def retrieve_text(self, query):
# Crea uno schema DeepLake per i documenti di testo in modalità di sola lettura
self.text_deeplake_schema = DeepLake(
dataset_path=cfg.TEXT_VECTORSTORE_PATH,
read_only=True,
embedding_function=self.embeddings,
)
# Definisci un modello di prompt per dare istruzioni al modello
prompt_template = """Sei un AI avanzato in grado di analizzare il testo da
documenti e fornire risposte dettagliate alle query degli utenti. Il tuo obiettivo è
offrire risposte complete per eliminare la necessità che gli utenti ritornino
al documento. Se non hai la risposta, riconoscilo invece di
inventare informazioni.
{context}
Domanda: {question}
Risposta:
"""
# Crea un PromptTemplate con "context" e "question"
PROMPT = PromptTemplate(
template=prompt_template, input_variables=["context", "question"]
)
# Definisci gli argomenti del tipo di catena
chain_type_kwargs = {"prompt": PROMPT}
# Inizializza il modello ChatOpenAI
model = ChatOpenAI(
model_name="gpt-3.5-turbo",
openai_api_key=cfg.OPENAI_API_KEY,
)
# Crea un'istanza RetrievalQA del modello
qa = RetrievalQA.from_chain_type(
llm=model,
chain_type="stuff",
retriever=self.text_retriever,
return_source_documents=False,
verbose=False,
chain_type_kwargs=chain_type_kwargs,
memory=self.memory,
)
# Interroga il modello con la domanda dell'utente
response = qa({"query": query})
# Restituisci la risposta da llm
return response["result"]4: Funzione di utilità per interrogare la nostra pipeline ed estrarre il risultato
Incolla il codice seguente nel tuo file utils.py:
def save(query, qa):
# Usa la funzione get_openai_callback
with get_openai_callback() as cb:
# Interroga l'oggetto qa con la domanda dell'utente
response = qa({"query": query}, return_only_outputs=True)
# Restituisci la risposta dalla risposta di llm
return response["result"]5: Un file di configurazione per memorizzare le tue chiavi… niente di particolare!
Incolla il codice seguente nel tuo file config.py:
import os
OPENAI_API_KEY = os.getenv(OPENAI_API_KEY)
TEXT_VECTORSTORE_PATH = "data\deeplake_text_vectorstore"
CHARACTER_SPLITTER_CHUNK_SIZE = 75
OPENAI_EMBEDDINGS_CHUNK_SIZE = 16Infine, possiamo codificare la nostra app Gradio per la demo!!
6: L’app Gradio!
Incolla il codice seguente nel tuo file app.py:
# Importa le librerie necessarie
import os
from controller import Controller
import gradio as gr
# Disabilita il parallelismo dei tokenizzatori per una migliore performance
os.environ["TOKENIZERS_PARALLELISM"] = "false"
# Inizializza la classe Controller
controller = Controller()
# Definisci una funzione per elaborare il file PDF caricato
def process_pdf(file):
if file is not None:
controller.embed_document(file)
return (
gr.update(visible=True),
gr.update(visible=True),
gr.update(visible=True),
gr.update(visible=True),
)
# Definisci una funzione per rispondere ai messaggi degli utenti
def respond(message, history):
botmessage = controller.retrieve(message)
history.append((message, botmessage))
return "", history
# Definisci una funzione per cancellare la cronologia della conversazione
def clear_everything():
return (None, None, None)
# Crea un'interfaccia Gradio
with gr.Blocks(css=CSS, title="") as demo:
# Mostra titoli e descrizioni
gr.Markdown("# AskPDF ", elem_id="app-title")
gr.Markdown("## Carica un PDF e fai domande!", elem_id="select-a-file")
gr.Markdown(
"Carica un PDF interessante e fai domande al riguardo!",
elem_id="select-a-file",
)
# Crea la sezione di caricamento
with gr.Row():
with gr.Column(scale=3):
upload = gr.File(label="Carica PDF", type="file")
with gr.Row():
clear_button = gr.Button("Cancella", variant="secondary")
# Crea l'interfaccia della chatbot
with gr.Column(scale=6):
chatbot = gr.Chatbot()
with gr.Row().style(equal_height=True):
with gr.Column(scale=8):
question = gr.Textbox(
show_label=False,
placeholder="es. Di cosa tratta il documento?",
lines=1,
max_lines=1,
).style(container=False)
with gr.Column(scale=1, min_width=60):
submit_button = gr.Button(
"Chiedimi 🤖", variant="primary", elem_id="submit-button"
)
# Definisci i pulsanti
upload.change(
fn=process_pdf,
inputs=[upload],
outputs=[
question,
clear_button,
submit_button,
chatbot,
],
api_name="upload",
)
question.submit(respond, [question, chatbot], [question, chatbot])
submit_button.click(respond, [question, chatbot], [question, chatbot])
clear_button.click(
fn=clear_everything,
inputs=[],
outputs=[upload, question, chatbot],
api_name="clear",
)
# Avvia l'interfaccia Gradio
if __name__ == "__main__":
demo.launch(enable_queue=False, share=False)Prendi la tua🧋, perché è ora di vedere come funziona la nostra pipeline!
Per avviare l’app Gradio, apri una nuova istanza del terminale e inserisci il comando seguente:
python app.pyNota: Assicurati che l’ambiente virtuale sia attivato e ti trovi nella directory del progetto corrente.
Gradio avvierà una nuova istanza della tua applicazione nel server localhost come segue:

Tutto ciò che devi fare è fare CTRL + clic sull’URL localhost (ultima riga) e la tua app si aprirà nel tuo browser.
YAY!
La nostra app Gradio è qui!
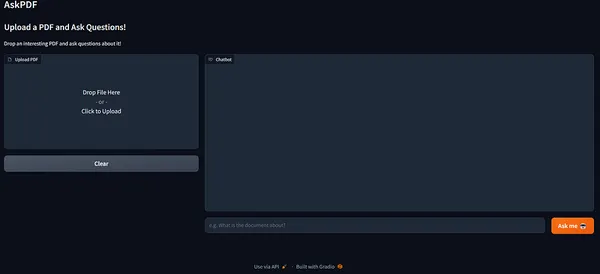
Lascia cadere un interessante PDF! Userò il pdf del capitolo 1 di Harry Potter da questo repository Kaggle che contiene libri di Harry Potter in formato .pdf per i capitoli da 1 a 7.
Lumos! Che la luce sia con te🪄
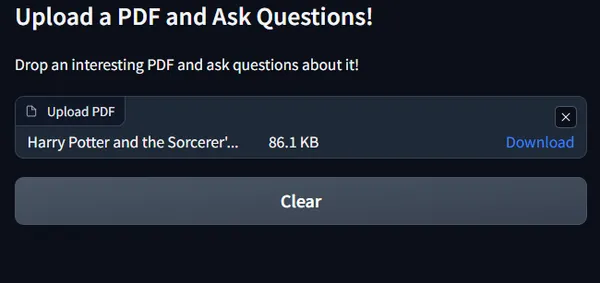
Ora, non appena carichi, la casella di testo per fare una domanda sarà attivata come segue:

Passiamo ora alla parte più attesa – il Quiz!
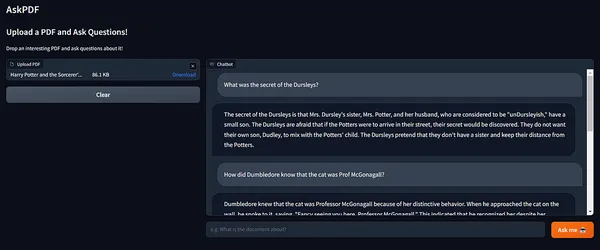
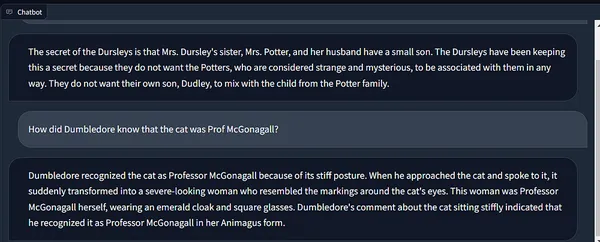
Wow! 😲
Adoro quanto siano accurate le risposte!
Inoltre, guarda come la memoria di Langchain mantiene lo stato della catena, incorporando il contesto delle esecuzioni precedenti.
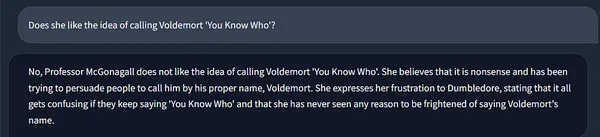
Ricorda che she qui è la nostra amata Professoressa McGonagall! ❤️🔥
Una breve demo su come funziona l’app!
L’approccio pratico e responsabile di RAG può essere estremamente utile per i data scientist in diversi ambiti di ricerca per creare prodotti AI precisi e responsabili.
1. Nella diagnosi del settore sanitario, implementare RAG per assistere medici e scienziati nella diagnosi di condizioni mediche complesse integrando record dei pazienti, letteratura medica, articoli di ricerca e riviste nella base di conoscenza, che aiuterà a recuperare informazioni aggiornate durante la presa di decisioni critiche e la ricerca nel settore sanitario.
2. Nel supporto clienti, le aziende possono utilizzare facilmente chatbot AI di conversazione alimentati da RAG per aiutare a risolvere richieste, reclami e fornire informazioni sui prodotti e manuali, FAQ da un database privato di prodotti e informazioni sugli ordini di acquisto fornendo risposte accurate, migliorando l’esperienza del cliente!
3. Nel settore fintech, gli analisti possono incorporare dati finanziari in tempo reale, notizie di mercato e storico dei prezzi delle azioni nella loro base di conoscenza e un framework RAG risponderà rapidamente ed efficientemente alle query su tendenze di mercato, situazione finanziaria dell’azienda, investimenti e ricavi, facilitando decisioni solide e responsabili.
4. Nel mercato dell’ed-tech, le piattaforme di e-learning possono avere chatbot RAG per aiutare gli studenti a risolvere le loro domande fornendo suggerimenti, risposte complete e soluzioni basate su un vasto archivio di libri di testo, articoli di ricerca e risorse educative. Ciò consente agli studenti di approfondire la loro comprensione delle materie senza dover effettuare ricerche manuali estese.
Le possibilità sono illimitate!
Conclusioni
In questo articolo, abbiamo esplorato la meccanica di RAG con Langchain e Deep Lake, in cui la similarità semantica svolge un ruolo fondamentale nel individuare informazioni rilevanti. Con database vettoriali, generazione di vettori di query e recupero basato su vettori, questi modelli accedono ai dati esterni in modo preciso quando necessario.
Il risultato? Risposte più precise e appropriate dal punto di vista contestuale, arricchite con dati proprietari. Spero che ti sia piaciuto e che tu abbia imparato qualcosa durante il percorso! Sentiti libero di scaricare il codice completo dal mio repository GitHub per provarlo.
Punti chiave
- Introduzione a RAG: Retrieval Augmented Generation (RAG) è una tecnica promettente nei Large Language Models (LLM) che migliora la loro conoscenza aggiungendo informazioni extra dalle proprie fonti di dati, rendendoli più intelligenti e riducendo gli errori quando mancano informazioni.
- Sfide nella QnA dei documenti: I Large Language Models hanno fatto progressi significativi nella Question and Answering (QnA) dei documenti, ma a volte possono avere difficoltà a discernere quando mancano informazioni, portando a errori.
- Pipeline di RAG: La pipeline di RAG utilizza la similarità semantica per identificare informazioni di query rilevanti. Comprende un Database Vettoriale, Generazione di Vettori di Query, Recupero Basato su Vettori e Generazione di Risposte, fornendo infine risposte più precise e appropriate dal punto di vista contestuale.
- Vantaggi di RAG: RAG consente ai modelli di fornire prove per le informazioni che recuperano, riducendo la necessità di frequenti ritraining in scenari di informazioni in rapido cambiamento.
- Implementazione pratica: L’articolo fornisce una guida pratica per implementare la pipeline di RAG, inclusa la configurazione della struttura del progetto, la creazione di una classe di recupero e embedding, la codifica della pipeline di recupero e la creazione di un’app Gradio per interazioni in tempo reale.
Domande frequenti
I media mostrati in questo articolo non sono di proprietà di Analytics Vidhya e sono utilizzati a discrezione dell’autore.





