Introduzione a Würstchen Diffusione rapida per la generazione di immagini
Introduzione a Würstchen Diffusione rapida immagini

Cos’è Würstchen?
Würstchen è un modello di diffusione, il cui componente condizionato dal testo opera in uno spazio latente altamente compresso delle immagini. Perché è importante? La compressione dei dati può ridurre i costi computazionali sia per l’addestramento che per l’inferenza di ordini di grandezza. L’addestramento su immagini 1024×1024 è molto più costoso dell’addestramento su immagini 32×32. Di solito, altri lavori fanno uso di una compressione relativamente piccola, nell’intervallo di 4x – 8x di compressione spaziale. Würstchen porta questo all’estremo. Attraverso il suo design innovativo, raggiunge una compressione spaziale di 42x! Questo non era mai stato visto prima, perché i metodi comuni non riescono a ricostruire fedelmente immagini dettagliate dopo una compressione spaziale di 16x. Würstchen utilizza una compressione a due stadi, che chiamiamo Stage A e Stage B. Stage A è un VQGAN e Stage B è un Diffusion Autoencoder (maggiori dettagli possono essere trovati nel paper). Insieme, Stage A e B vengono chiamati Decoder, perché decodificano le immagini compresse nello spazio dei pixel. Un terzo modello, Stage C, viene appreso in quel particolare spazio latente altamente compresso. Questo addestramento richiede una frazione del calcolo utilizzato per i modelli di miglior performance attuali, consentendo anche un’elaborazione più economica e veloce. Ci riferiamo a Stage C come Prior.

Perché un altro modello di testo-immagine?
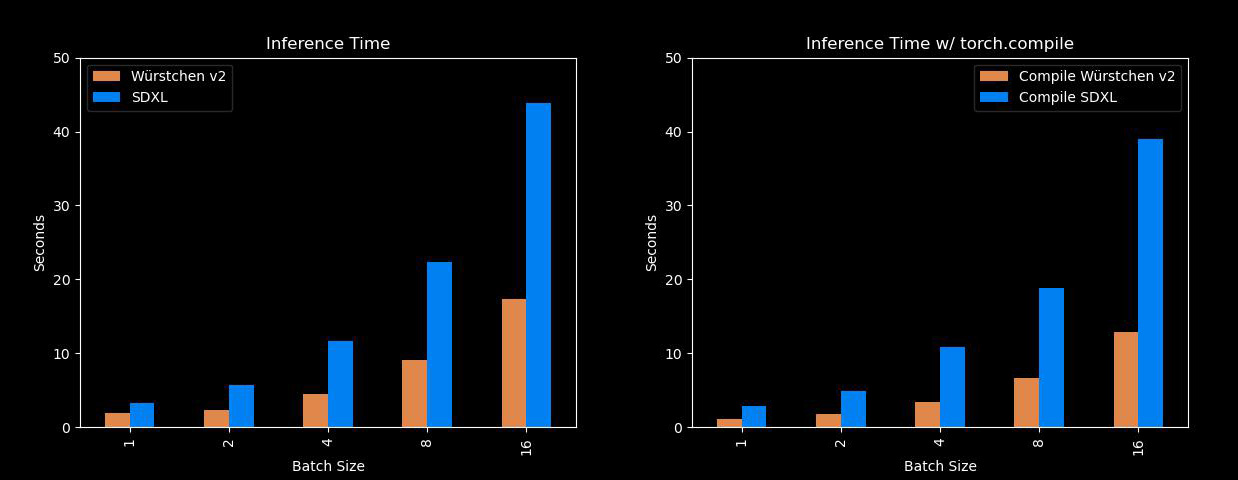
Bene, questo è abbastanza veloce ed efficiente. I principali vantaggi di Würstchen derivano dal fatto che può generare immagini molto più velocemente rispetto a modelli come Stable Diffusion XL, utilizzando anche molta meno memoria! Quindi, per tutti coloro che non hanno A100 a disposizione, questo sarà molto utile. Ecco un confronto con SDXL su diverse dimensioni di batch:
- Navigare nel panorama delle startup di robotica una guida completa all’identificazione di mercato, alla gestione della catena di approvvigionamento e allo sviluppo tecnologico
- Una breve guida all’Intelligenza Artificiale nel Marketing
- Come fare una transizione di carriera verso la Data Science a 30 anni?
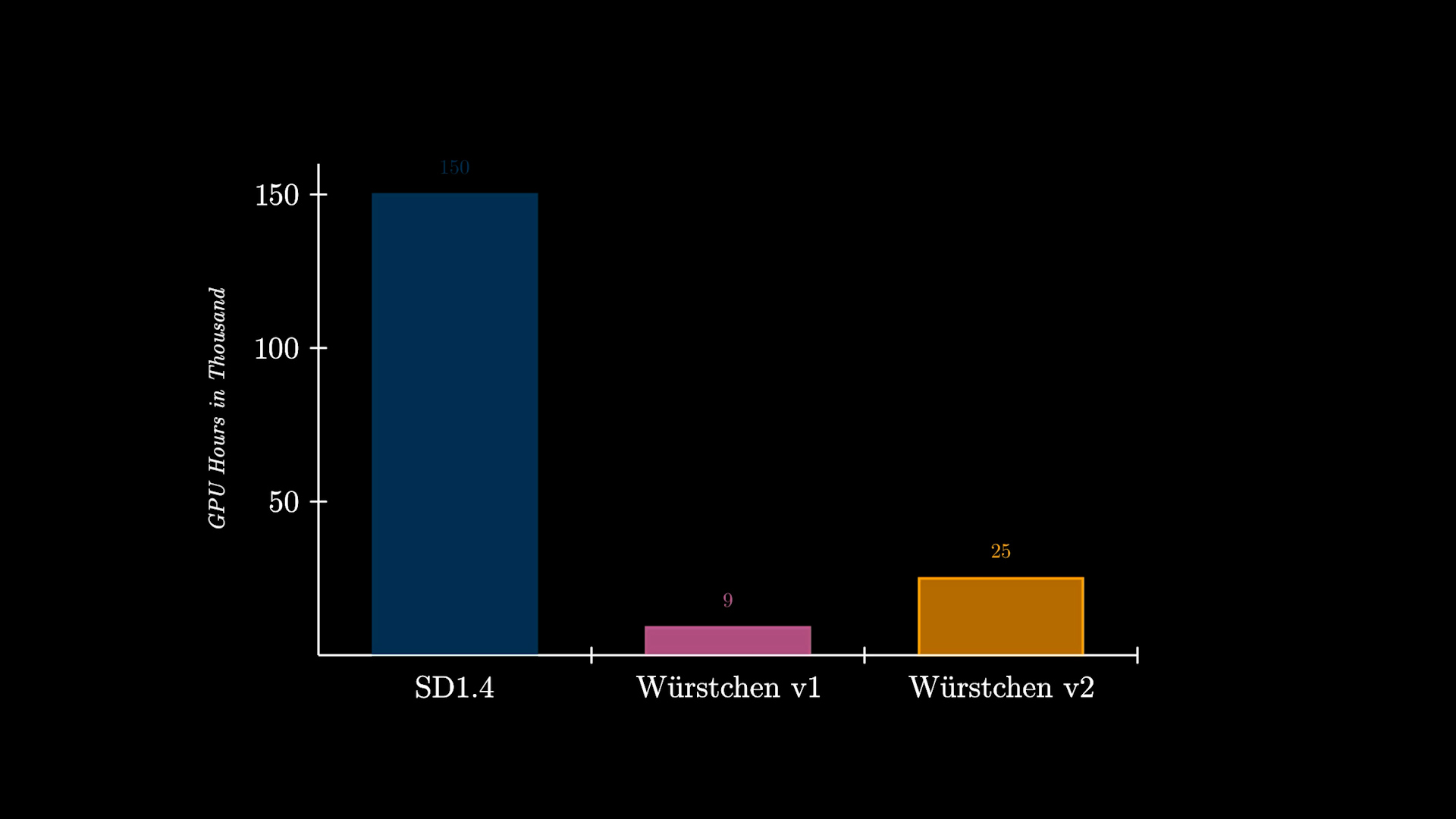
Inoltre, un altro beneficio significativo di Würstchen è il ridotto costo di addestramento. Würstchen v1, che funziona a 512×512, ha richiesto solo 9.000 ore di GPU di addestramento. Confrontando questo con le 150.000 ore di GPU spese su Stable Diffusion 1.4, si può notare che questa riduzione del costo del 16x non beneficia solo i ricercatori durante la conduzione di nuovi esperimenti, ma apre anche la possibilità per più organizzazioni di addestrare tali modelli. Würstchen v2 ha utilizzato 24.602 ore di GPU. Con risoluzioni che arrivano fino a 1536, questo è comunque 6x più economico rispetto a SD1.4, che è stato addestrato solo a 512×512.
Puoi trovare anche un video di spiegazione dettagliato qui:
Come utilizzare Würstchen?
Puoi provarlo utilizzando il Demo qui:
In alternativa, il modello è disponibile attraverso la Diffusers Library, quindi puoi utilizzare l’interfaccia con cui sei già familiare. Ad esempio, ecco come eseguire l’inferenza utilizzando il AutoPipeline:
import torch
from diffusers import AutoPipelineForText2Image
from diffusers.pipelines.wuerstchen import DEFAULT_STAGE_C_TIMESTEPS
pipeline = AutoPipelineForText2Image.from_pretrained("warp-ai/wuerstchen", torch_dtype=torch.float16).to("cuda")
caption = "Gatto antropomorfo vestito da pompiere"
images = pipeline(
caption,
height=1024,
width=1536,
prior_timesteps=DEFAULT_STAGE_C_TIMESTEPS,
prior_guidance_scale=4.0,
num_images_per_prompt=4,
).images
Su quali dimensioni di immagine funziona Würstchen?
Würstchen è stato addestrato su risoluzioni di immagine tra 1024×1024 e 1536×1536. A volte osserviamo anche buoni risultati a risoluzioni come 1024×2048. Sentiti libero di provarlo. Abbiamo anche osservato che il Prior (Stage C) si adatta estremamente velocemente a nuove risoluzioni. Quindi, affinarlo a 2048×2048 dovrebbe essere computazionalmente economico. 
Modelli sul Hub
Tutti i punti di controllo possono essere visualizzati anche sul Huggingface Hub. Sono disponibili diversi punti di controllo, oltre a future demo e pesi del modello. Al momento ci sono 3 punti di controllo disponibili per il Prior e 1 punto di controllo per il Decoder. Dai un’occhiata alla documentazione per capire come vengono spiegati i punti di controllo e quali sono i diversi modelli Prior e per cosa possono essere utilizzati.
Integrazione di Diffusers
Perché Würstchen è completamente integrato in diffusers, viene fornito automaticamente con varie funzionalità e ottimizzazioni. Queste includono:
- Utilizzo automatico dell’attenzione accelerata PyTorch 2
SDPA, come descritto di seguito. - Supporto per l’implementazione dell’attenzione flash di xFormers, se hai bisogno di utilizzare PyTorch 1.x invece della versione 2.
- Scarico del modello, per spostare i componenti inutilizzati sulla CPU quando non sono in uso. Ciò consente di risparmiare memoria con un impatto sulle prestazioni trascurabile.
- Scarico sequenziale sulla CPU, per situazioni in cui la memoria è davvero preziosa. L’utilizzo della memoria sarà ridotto al minimo, a discapito di una inferenza più lenta.
- Ponderazione del prompt con la libreria Compel.
- Supporto per il dispositivo
mpssu Mac Apple Silicon. - Utilizzo di generatori per la riproducibilità.
- Impostazioni predefinite sensate per l’inferenza al fine di produrre risultati di alta qualità nella maggior parte delle situazioni. Naturalmente, è possibile modificare tutti i parametri come si desidera!
Tecnica di ottimizzazione 1: Attenzione flash
A partire dalla versione 2.0, PyTorch ha integrato una versione altamente ottimizzata ed efficiente in termini di risorse del meccanismo di attenzione chiamato torch.nn.functional.scaled_dot_product_attention o SDPA. A seconda della natura dell’input, questa funzione sfrutta diverse ottimizzazioni sottostanti. Le sue prestazioni e l’efficienza della memoria superano il modello di attenzione tradizionale. In modo sorprendente, la funzione SDPA riflette le caratteristiche della tecnica di attenzione flash, come evidenziato nell’articolo di ricerca “Fast and Memory-Efficient Exact Attention with IO-Awareness” scritto da Dao e dal suo team.
Se stai utilizzando Diffusers con PyTorch 2.0 o una versione successiva e la funzione SDPA è accessibile, questi miglioramenti vengono applicati automaticamente. Inizia impostando torch 2.0 o una versione più recente seguendo le linee guida ufficiali!
images = pipeline(caption, height=1024, width=1536, prior_timesteps=DEFAULT_STAGE_C_TIMESTEPS, prior_guidance_scale=4.0, num_images_per_prompt=4).imagesPer una panoramica approfondita di come diffusers sfrutta SDPA, consulta la documentazione.
Se stai utilizzando una versione di Pytorch precedente alla 2.0, puoi comunque ottenere un’attenzione efficiente in termini di memoria utilizzando la libreria xFormers:
pipeline.enable_xformers_memory_efficient_attention()Tecnica di ottimizzazione 2: Compilazione di Torch
Se sei alla ricerca di un ulteriore aumento delle prestazioni, puoi utilizzare torch.compile. È meglio applicarlo sia al modello principale del Prior che del Decoder per ottenere il maggior aumento delle prestazioni.
pipeline.prior_prior = torch.compile(pipeline.prior_prior , mode="reduce-overhead", fullgraph=True)
pipeline.decoder = torch.compile(pipeline.decoder, mode="reduce-overhead", fullgraph=True)Tieni presente che la fase iniziale di inferenza richiederà molto tempo (fino a 2 minuti) mentre i modelli vengono compilati. Dopo di ciò, puoi eseguire normalmente l’inferenza:
images = pipeline(caption, height=1024, width=1536, prior_timesteps=DEFAULT_STAGE_C_TIMESTEPS, prior_guidance_scale=4.0, num_images_per_prompt=4).imagesE la buona notizia è che questa compilazione è un’esecuzione di una tantum. Dopo di ciò, sei pronto per sperimentare inferenze più veloci in modo coerente per le stesse risoluzioni delle immagini. L’investimento iniziale di tempo nella compilazione viene rapidamente compensato dai successivi vantaggi in termini di velocità. Per una panoramica più approfondita di torch.compile e delle sue sfumature, consulta la documentazione ufficiale.
Risorse
- Ulteriori informazioni su questo modello possono essere trovate nella documentazione ufficiale di diffusers.
- Tutti i punti di controllo possono essere trovati sul hub
- Puoi provare la demo qui.
- Unisciti al nostro Discord se vuoi discutere di progetti futuri o contribuire con le tue idee!




