Valutazione dell’uguaglianza verde urbana utilizzando il portale dati aperti di Vienna
Urban green equality evaluation using Vienna's open data portal
Nonostante i loro molti vantaggi, l’accesso alla natura e agli spazi verdi sta diventando sempre più difficile nelle aree altamente urbanizzate. Alcuni temono che le comunità svantaggiate siano più esposte a questi problemi. Qui propongo un modo basato su dati per esplorare questo.
In particolare, pongo una domanda di sviluppo urbano che di recente sta guadagnando interesse tra i professionisti e i governi locali, ora denominata uguaglianza verde. Questo concetto si riferisce alle disparità nell’accesso delle persone agli spazi verdi in diverse parti di una particolare città. Qui, esploro la sua dimensione finanziaria e vedo se ci sono relazioni chiare tra l’area verde disponibile per abitante e il livello economico della stessa unità urbana.
Esplorerò due diverse risoluzioni spaziali della città – distretti e distretti censuari – utilizzando i file Shapefile di Esri forniti dal Portale dei dati aperti del governo austriaco. Incorporerò anche dati statistici tabulari (popolazione e reddito) nelle aree amministrative georeferenziate. Quindi, sovrapporrò le aree amministrative con un dataset ufficiale delle aree verdi, registrando la posizione di ogni spazio verde in formato geospaziale. Infine, combinerò queste informazioni e quantificherò la dimensione totale degli spazi verdi per abitante di ogni distretto urbano. Infine, relazionerò lo stato finanziario di ciascuna area, catturato dal reddito netto annuale, al rapporto tra l’area verde per abitante per vedere se emergono alcuni schemi.
1. Fonte dei dati
Diamo un’occhiata al Portale dei dati aperti del governo austriaco qui.
Quando ho scritto questo articolo, la traduzione in inglese del sito web non funzionava molto bene, quindi invece di fare affidamento sui miei ormai dimenticati 12 anni di lezioni di tedesco, ho usato DeepL per navigare tra le sottopagine e migliaia di dataset.
- L’IA sta potenziando le capacità delle telecamere di sicurezza
- L’IA generativa nell’industria sanitaria ha bisogno di una dose di spiegabilità
- AnomalyGPT Rilevare anomalie industriali utilizzando LVLM
Poi, ho raccolto un paio di file di dati, sia georeferenziati (shapefile di Esri) che dati tabulari semplici, che utilizzerò per l’analisi successiva. I dati che ho raccolto:
Confini – i confini amministrativi delle seguenti unità spaziali a Vienna:
- I confini amministrativi di Vienna
- I confini amministrativi dei 23 distretti di Vienna
- I confini amministrativi dei 250 distretti censuari di Vienna
Utilizzo del suolo – informazioni sulla posizione degli spazi verdi e delle aree edificate:
- Green Belt Vienna City of Vienna visualizzando le aree verdi esistenti e dedicate, costituite da 1539 file poligonali geospaziali che racchiudono gli spazi verdi
Statistiche – dati sulla popolazione e sul reddito corrispondenti al livello socio-economico di un’area:
- Popolazione per distretto, registrata annualmente dal 2002 e suddivisa in base a gruppi di età di 5 anni, genere e nazionalità originale
- Popolazione per distretto censuario, registrata annualmente dal 2008 e suddivisa in base a tre gruppi di età irregolari, genere e origine
- Reddito netto medio dal 2002 nei distretti di Vienna, espresso in euro per dipendente all’anno
Inoltre, ho memorizzato i file di dati scaricati in una cartella locale chiamata “data”.
2. Esplorazione dei dati di base
2.1 Confini amministrativi
Prima, leggi e visualizza i diversi file shape contenenti ciascun livello di confine amministrativo per avere una visione più ravvicinata della città in questione:
folder = 'data'admin_city = gpd.read_file(folder + '/LANDESGRENZEOGD')admin_district = gpd.read_file(folder + '/BEZIRKSGRENZEOGD')admin_census = gpd.read_file(folder + '/ZAEHLBEZIRKOGD')display(admin_city.head(1))display(admin_district.head(1))display(admin_census.head(1))Qui facciamo una nota che i nomi delle colonne BEZNR e ZBEZ corrispondono all’ID del distretto e all’ID del distretto censuario, rispettivamente. Inaspettatamente, sono memorizzati/elaborati in formati diversi, numpy.float64 e str:
print(type(admin_district.BEZNR.iloc[0]))print(type(admin_census.ZBEZ.iloc[0]))pythVerifichiamo se abbiamo effettivamente 23 distretti e 250 distretti di censimento come dichiarato nella documentazione dei file di dati:
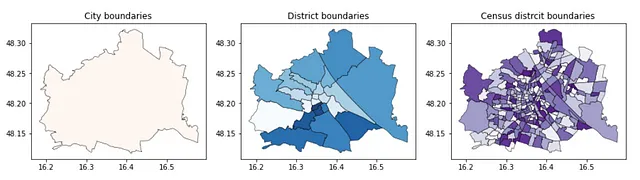
print(len(set(admin_district.BEZNR)))print(len(set(admin_census.ZBEZ)))Ora visualizziamo i confini: prima la città, poi i distretti e infine i distretti di censimento ancora più piccoli.
f, ax = plt.subplots(1,3,figsize=(15,5))admin_city.plot(ax=ax[0], edgecolor = 'k', linewidth = 0.5, alpha = 0.9, cmap = 'Reds')admin_district.plot(ax=ax[1], edgecolor = 'k', linewidth = 0.5, alpha = 0.9, cmap = 'Blues')admin_census.plot(ax=ax[2], edgecolor = 'k', linewidth = 0.5, alpha = 0.9, cmap = 'Purples')ax[0].set_title('Confini della città')ax[1].set_title('Confini del distretto')ax[2].set_title('Confini del distretto di censimento')Questo codice produce le seguenti visualizzazioni di Vienna:
2.2 Aree verdi
Adesso, diamo un’occhiata anche alla distribuzione delle aree verdi:
gdf_green = gpd.read_file(folder + '/GRUENFREIFLOGD_GRUENGEWOGD')display(gdf_green.head(3))Qui, si può notare che non c’è un modo diretto per collegare le aree verdi (ad esempio, nessun id del distretto aggiunto) ai quartieri – quindi in seguito, lo faremo manipolando le geometrie per trovare sovrapposizioni.
Ora visualizziamo questo:
f, ax = plt.subplots(1,1,figsize=(7,5))gdf_green.plot(ax=ax, edgecolor = 'k', linewidth = 0.5, alpha = 0.9, cmap = 'Greens')ax.set_title('Aree verdi a Vienna')Questo codice mostra dove si trovano le aree verdi all’interno di Vienna:
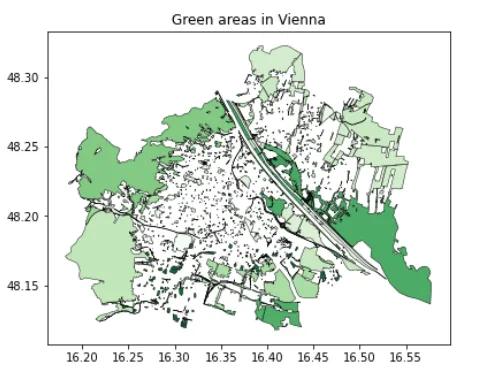
Possiamo notare che i segmenti forestali sono ancora all’interno del confine amministrativo, il che implica che non ogni parte della città è urbanizzata e significativamente popolata. In seguito, torneremo su questo quando valuteremo l’area verde pro capite.
2.3 Dati statistici – popolazione, reddito
Infine, diamo un’occhiata ai file dei dati statistici. La prima differenza principale è che questi non sono georeferenziati ma semplici tabelle csv:
df_pop_distr = pd.read_csv('vie-bez-pop-sex-age5-stk-ori-geo4-2002f.csv', sep = ';', encoding='unicode_escape', skiprows = 1)df_pop_cens = pd.read_csv('vie-zbz-pop-sex-agr3-stk-ori-geo2-2008f.csv', sep = ';', encoding='unicode_escape', skiprows = 1)df_inc_distr = pd.read_csv('vie-bez-biz-ecn-inc-sex-2002f.csv', sep = ';', encoding='unicode_escape', skiprows = 1)display(df_pop_distr.head(1))display(df_pop_cens.head(1))display(df_inc_distr.head(1))3. Preelaborazione dei dati
3.1. Preparazione dei file di dati statistici
La precedente sottosezione mostra che le tabelle dei dati statistici utilizzano diverse convenzioni di denominazione: utilizzano gli identificatori DISTRICT_CODE e SUB_DISTRICT_CODE invece di cose come BEZNR e ZBEZ. Tuttavia, dopo aver letto la documentazione di ciascun set di dati, diventa chiaro che è facile trasformare uno nell’altro, per cui presento due brevi funzioni nella cella successiva. Elaborerò contemporaneamente i dati a livello di distretti e distretti di censimento.
Inoltre, sarò interessato solo ai valori e ai punti dati aggregati (più recenti) delle informazioni statistiche, come la popolazione totale nell’ultimo snapshot. Quindi, puliamo questi file di dati e conserviamo le colonne che userò in seguito.
# queste funzioni convertono gli identificatori distretto e distretto del censimento in modo compatibile con quelli trovati nei file di shapefiledef transform_district_id(x): return int(str(x)[1:3])def transform_census_district_id(x): return int(str(x)[1:5])# seleziona l'anno più recente del datasetdf_pop_distr_2 = df_pop_distr[df_pop_distr.REF_YEAR \ ==max(df_pop_distr.REF_YEAR)]df_pop_cens_2 = df_pop_cens[df_pop_cens.REF_YEAR \ ==max(df_pop_cens.REF_YEAR)]df_inc_distr_2 = df_inc_distr[df_inc_distr.REF_YEAR \ ==max(df_inc_distr.REF_YEAR)]# converte gli identificatori distrettidf_pop_distr_2['district_id'] = \ df_pop_distr_2.DISTRICT_CODE.apply(transform_district_id)df_pop_cens_2['census_district_id'] = \ df_pop_cens_2.SUB_DISTRICT_CODE.apply(transform_census_district_id)df_inc_distr_2['district_id'] = \ df_inc_distr_2.DISTRICT_CODE.apply(transform_district_id)# aggrega i valori della popolazionedf_pop_distr_2 = df_pop_distr_2.groupby(by = 'district_id').sum()df_pop_distr_2['district_population'] = df_pop_distr_2.AUT + \ df_pop_distr_2.EEA + df_pop_distr_2.REU + df_pop_distr_2.TCNdf_pop_distr_2 = df_pop_distr_2[['district_population']]df_pop_cens_2 = df_pop_cens_2.groupby(by = 'census_district_id').sum()df_pop_cens_2['census_district_population'] = df_pop_cens_2.AUT \ + df_pop_cens_2.FORdf_pop_cens_2 = df_pop_cens_2[['census_district_population']]df_inc_distr_2['district_average_income'] = \ 1000*df_inc_distr_2[['INC_TOT_VALUE']]df_inc_distr_2 = \ df_inc_distr_2.set_index('district_id')[['district_average_income']]# visualizza le tabelle finalizzatedisplay(df_pop_distr_2.head(3))display(df_pop_cens_2.head(3))display(df_inc_distr_2.head(3))# e unificare le convenzioni di denominazionedistricto_amministrativo['district_id'] = distretto_amministrativo.BEZNR.astype(int)censimento_amministrativo['census_district_id'] = censimento_amministrativo.ZBEZ.astype(int)print(len(set(censimento_amministrativo.ZBEZ)))Verifica i valori della popolazione totale calcolati ai due livelli di aggregazione:
print(sum(df_pop_distr_2.district_population))print(sum(df_pop_cens_2.census_district_population))Questi due dovrebbero fornire lo stesso risultato: 1931593 persone.
3.1. Preparazione dei file di dati geospaziali
Ora che abbiamo finito con la preparazione essenziale dei file statistici, è il momento di abbinare i poligoni delle aree verdi ai poligoni delle aree amministrative. Successivamente, calcoliamo la copertura totale delle aree verdi di ciascuna area amministrativa. Inoltre, aggiungerò la copertura relativa delle aree verdi di ciascuna area amministrativa per curiosità.
Per ottenere aree espresse in unità SI, è necessario passare a un cosiddetto CRS locale, che nel caso di Vienna è EPSG:31282. Puoi leggere di più su questo argomento, sulla proiezione cartografica e sui sistemi di riferimento delle coordinate qui e qui.
# convertire tutti i GeoDataFrame nel CRS localeadmin_district_2 = \ admin_district[['district_id', 'geometry']].to_crs(31282)admin_census_2 = \ admin_census[['census_district_id', 'geometry']].to_crs(31282)gdf_green_2 = gdf_green.to_crs(31282)Calcola l’area dell’unità amministrativa misurata in unità SI:
admin_district_2['admin_area'] = \ admin_district_2.geometry.apply(lambda g: g.area)admin_census_2['admin_area'] = \ admin_census_2.geometry.apply(lambda g: g.area)display(admin_district_2.head(1))display(admin_census_2.head(1))4. Calcola il rapporto tra area verde e abitanti
4.1 Calcola la copertura dell’area verde in ciascuna unità amministrativa
Utilizzerò la funzione di sovrapposizione di GeoPandas per sovrapporre queste due GeoDataFrame di confini amministrativi con il GeoDataFrame che contiene i poligoni dell’area verde. Quindi calcolo l’area di ciascuna sezione dell’area verde che ricade in diverse regioni amministrative. Successivamente, sommo queste aree al livello di ciascuna area amministrativa, sia distretti che distretti censuari. Nell’ultimo passaggio, per ciascuna unità di risoluzione, aggiungo le aree delle unità amministrative precedentemente calcolate e calcolo il rapporto tra l’area totale e l’area verde per ciascun distretto e distretto censuario.
gdf_green_mapped_distr = gpd.overlay(gdf_green_2, admin_district_2)gdf_green_mapped_distr['green_area'] = \ gdf_green_mapped_distr.geometry.apply(lambda g: g.area) gdf_green_mapped_distr = \ gdf_green_mapped_distr.groupby(by = 'district_id').sum()[['green_area']]gdf_green_mapped_distr = \ gpd.GeoDataFrame(admin_district_2.merge(gdf_green_mapped_distr, left_on = 'district_id', right_index = True))gdf_green_mapped_distr['green_ratio'] = \ gdf_green_mapped_distr.green_area / gdf_green_mapped_distr.admin_areagdf_green_mapped_distr.head(3)
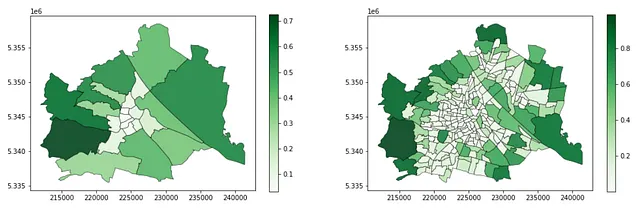
gdf_green_mapped_cens = gpd.overlay(gdf_green_2, admin_census_2)gdf_green_mapped_cens['green_area'] = \ gdf_green_mapped_cens.geometry.apply(lambda g: g.area)gdf_green_mapped_cens = \ gdf_green_mapped_cens.groupby(by = 'census_district_id').sum()[['green_area']]gdf_green_mapped_cens = \ gpd.GeoDataFrame(admin_census_2.merge(gdf_green_mapped_cens, left_on = 'census_district_id', right_index = True))gdf_green_mapped_cens['green_ratio'] = gdf_green_mapped_cens.green_area / gdf_green_mapped_cens.admin_areagdf_green_mapped_cens.head(3)Infine, visualizza il rapporto tra area verde e abitanti per distretto e distretto censuario! I risultati sembrano avere molto senso, con un alto livello di aree verdi nelle parti esterne e molto più basso nelle aree centrali. Inoltre, i 250 distretti censuari mostrano chiaramente un’immagine più dettagliata e articolata delle caratteristiche dei diversi quartieri, offrendo approfondimenti più profondi e localizzati agli urbanisti. D’altra parte, le informazioni a livello di distretto, con un numero di unità spaziali dieci volte inferiore, mostrano invece medie più generali.
f, ax = plt.subplots(1,2,figsize=(17,5))gdf_green_mapped_distr.plot(ax = ax[0], column = 'green_ratio', edgecolor = 'k', linewidth = 0.5, alpha = 0.9, legend = True, cmap = 'Greens')gdf_green_mapped_cens.plot(ax = ax[1], column = 'green_ratio', edgecolor = 'k', linewidth = 0.5, alpha = 0.9, legend = True, cmap = 'Greens')Questo blocco di codice produce le seguenti mappe:
4.2 Aggiungi informazioni sulla popolazione e sul reddito per ciascuna unità amministrativa
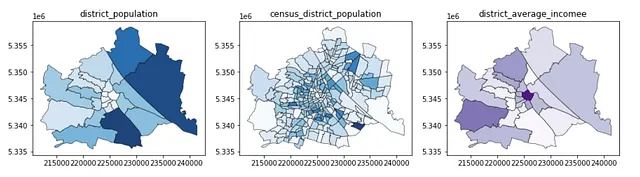
Nell’ultimo passaggio di questa sezione, mappiamo i dati statistici nelle aree amministrative. Promemoria: abbiamo dati sulla popolazione sia a livello di distretti che a livello di distretti censuari. Tuttavia, sono riuscito a trovare solo il reddito (indicatore di livello socioeconomico) a livello di distretti. Questo è un compromesso comune nella scienza dei dati geospaziali. Mentre una dimensione (area verde) offre molte più informazioni a risoluzioni più elevate (distretti censuari), le limitazioni dei dati possono costringerci comunque a utilizzare la risoluzione inferiore.
display(admin_census_2.head(2))display(df_pop_cens_2.head(2))
gdf_pop_mapped_distr = admin_district_2.merge(df_pop_distr_2, \ left_on = 'district_id', right_index = True)gdf_pop_mapped_cens = admin_census_2.merge(df_pop_cens_2, \ left_on = 'census_district_id', right_index = True)gdf_inc_mapped_distr = admin_district_2.merge(df_inc_distr_2, \ left_on = 'district_id', right_index = True)f, ax = plt.subplots(1,3,figsize=(15,5))gdf_pop_mapped_distr.plot(column = 'district_population', ax=ax[0], \ edgecolor = 'k', linewidth = 0.5, alpha = 0.9, cmap = 'Blues')gdf_pop_mapped_cens.plot(column = 'census_district_population', ax=ax[1], \ edgecolor = 'k', linewidth = 0.5, alpha = 0.9, cmap = 'Blues')gdf_inc_mapped_distr.plot(column = 'district_average_income', ax=ax[2], \ edgecolor = 'k', linewidth = 0.5, alpha = 0.9, cmap = 'Purples')ax[0].set_title('district_population')ax[1].set_title('census_district_population')ax[2].set_title('district_average_incomee')Questo blocco di codici produce la seguente figura:
4.3. Calcolo dell’area verde per abitante
Riassumiamo ciò che abbiamo adesso, il tutto integrato in shapefile decenti corrispondenti ai distretti e ai distretti di censimento di Vienna:
Al livello dei distretti, abbiamo il rapporto di area verde, la popolazione e i dati sul reddito
Al livello dei distretti di censimento, abbiamo il rapporto di area verde e i dati sulla popolazione
Per catturare semplicemente l’uguaglianza verde, unisco le informazioni sulla dimensione assoluta dell’area verde e la popolazione nei distretti e nei distretti di censimento e calcolo la quantità totale di area verde per abitante.
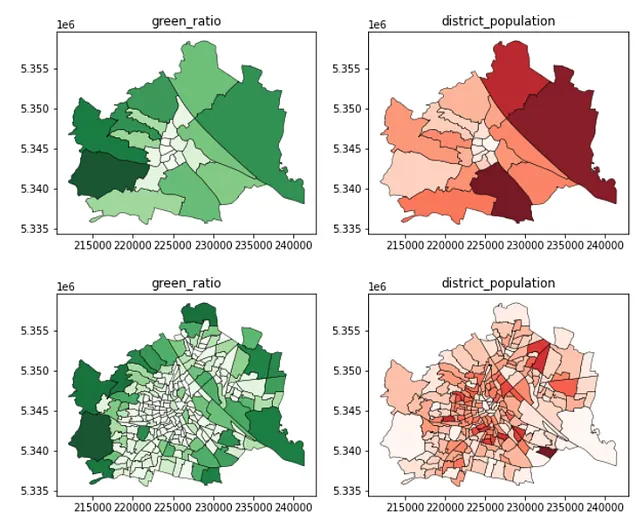
Diamo un’occhiata al nostro input – copertura verde e popolazione:
# un grafico per i distretti
fig, ax = plt.subplots(1,2,figsize=(10,5))
gdf_green_mapped_distr.plot(ax=ax[0], column='green_ratio', edgecolor='k', linewidth=0.5, alpha=0.9, cmap='Greens')
gdf_pop_mapped_distr.plot(ax=ax[1], column='district_population', edgecolor='k', linewidth=0.5, alpha=0.9, cmap='Reds')
ax[0].set_title('green_ratio')
ax[1].set_title('district_population')
# un grafico per i distretti di censimento
fig, ax = plt.subplots(1,2,figsize=(10,5))
gdf_green_mapped_cens.plot(ax=ax[0], column='green_ratio', edgecolor='k', linewidth=0.5, alpha=0.9, cmap='Greens')
gdf_pop_mapped_cens.plot(ax=ax[1], column='census_district_population', edgecolor='k', linewidth=0.5, alpha=0.9, cmap='Reds')
ax[0].set_title('green_ratio')
ax[1].set_title('district_population')Questo blocco di codici produce la seguente figura:
Per calcolare l’area verde per abitante, unirò prima i frame di dati sull’area verde e sulla popolazione seguendo i seguenti passaggi. Lo farò tramite l’esempio dei distretti di censimento perché la loro maggiore risoluzione spaziale ci permette di osservare meglio i modelli (se ce ne sono). Assicuriamoci di non dividere per zero e di seguire anche il buon senso; eliminiamo quelle aree che sono disabitate.
gdf_green_pop_cens = \
gdf_green_mapped_cens.merge(gdf_pop_mapped_cens.drop( \
columns=['geometry', 'admin_area']), left_on='census_district_id', \
right_on='census_district_id')[['census_district_id', \
'green_area', 'census_district_population', 'geometry']]
gdf_green_pop_cens['green_area_per_capita'] = \
gdf_green_pop_cens['green_area'] / \
gdf_green_pop_cens['census_district_population']
gdf_green_pop_cens = \
gdf_green_pop_cens[gdf_green_pop_cens['census_district_population'] > 0]
f, ax = plt.subplots(1,1,figsize=(10,7))
gdf_green_pop_cens.plot(column='green_area_per_capita', ax=ax, cmap='RdYlGn', edgecolor='k', linewidth=0.5)
admin_district.to_crs(31282).plot(ax=ax, color='none', edgecolor='k', linewidth=2.5)Questo blocco di codici produce la seguente figura:
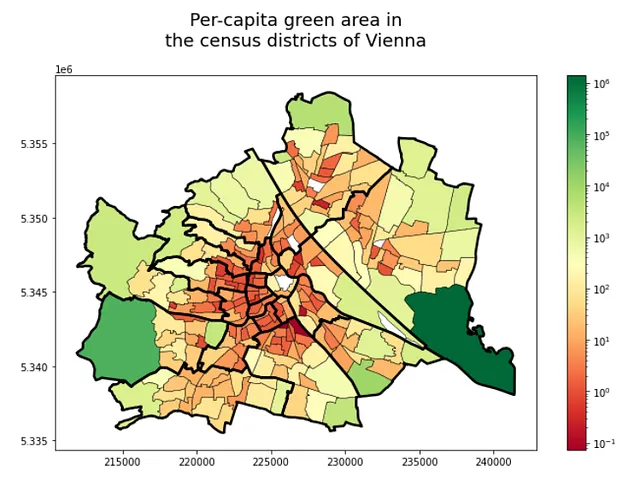
Modifichiamo un po’ la visualizzazione:
f, ax = plt.subplots(1,1,figsize=(11,7))
ax.set_title("Area verde per abitante\nnei distretti di Vienna", fontsize=18, pad=30)
gdf_green_pop_cens.plot(column='green_area_per_capita', ax=ax, cmap='RdYlGn', edgecolor='k', linewidth=0.5, legend=True, norm=matplotlib.colors.LogNorm(vmin=gdf_green_pop_cens.green_area_per_capita.min(), vmax=gdf_green_pop_cens.green_area_per_capita.max()))
admin_district.to_crs(31282).plot(ax=ax, color='none', edgecolor='k', linewidth=2.5)Questo blocco di codice produce la seguente figura:
Lo stesso vale per i distretti:
# calcola i punteggi di area verde per abitante
gdf_green_pop_distr = gdf_green_mapped_distr.merge(gdf_pop_mapped_distr.drop(columns=['geometry', 'admin_area']), left_on='district_id', right_on='district_id')[['district_id', 'green_area', 'district_population', 'geometry']]
gdf_green_pop_distr = gdf_green_pop_distr[gdf_green_pop_distr.district_population > 0]
gdf_green_pop_distr['green_area_per_capita'] = gdf_green_pop_distr['green_area'] / gdf_green_pop_distr['district_population']
# visualizza la mappa a livello di distretto
f, ax = plt.subplots(1,1,figsize=(10,8))
ax.set_title("Area verde per abitante\nnei distretti di Vienna", fontsize=18, pad=26)
gdf_green_pop_distr.plot(column='green_area_per_capita', ax=ax, cmap='RdYlGn', edgecolor='k', linewidth=0.5, legend=True, norm=matplotlib.colors.LogNorm(vmin=gdf_green_pop_cens.green_area_per_capita.min(), vmax=gdf_green_pop_cens.green_area_per_capita.max()))
admin_city.to_crs(31282).plot(ax=ax, color='none', edgecolor='k', linewidth=2.5)Questo blocco di codice produce la seguente figura:
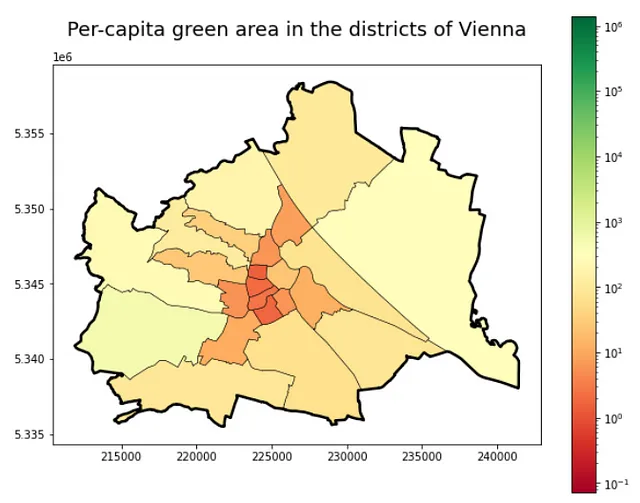
Anche se i trend significativi sono chiari — periferia, maggior spazio verde per tutti, centro abitato, inverso — questi due grafici, specialmente quello più dettagliato a livello di distretti di censimento, mostrano chiaramente una variazione nella quantità di spazio verde di cui le persone godono nelle diverse aree. Ulteriori ricerche e l’inclusione di ulteriori fonti di dati, ad esempio sull’uso del territorio, potrebbero aiutare a spiegare meglio perché queste aree hanno una maggiore area verde o popolazione. Per ora, godiamoci questa mappa e speriamo che tutti possano trovare la giusta quantità di verde nella propria casa!
# unione dei dati sull'area verde, la popolazione e le finanze
gdf_district_green_pip_inc = gdf_green_pop_distr.merge(gdf_inc_mapped_distr.drop(columns=['geometry']))Visualizza la relazione tra le dimensioni finanziarie e quelle relative all’area verde:
f, ax = plt.subplots(1,1,figsize=(6,4))ax.plot(gdf_district_green_pip_inc.district_average_income, \ gdf_district_green_pip_inc.green_area_per_capita, 'o')ax.set_xscale('log')ax.set_yscale('log')ax.set_xlabel('district_average_income')ax.set_ylabel('green_area_per_capita')Il risultato di questo blocco di codice è il seguente grafico a dispersione:
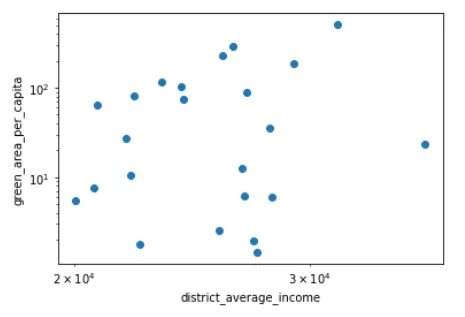
A prima vista, il grafico a dispersione non indica particolarmente che le finanze determinino l’accesso delle persone agli spazi verdi. Sinceramente, sono un po’ sorpreso da questi risultati — tuttavia, alla luce degli sforzi consapevoli e a lungo termine di Vienna per rendere la propria città più verde, potrebbe essere il motivo per cui non vediamo alcuna tendenza significativa qui. Per confermare, ho anche controllato le correlazioni tra queste due variabili:
print(spearmanr(gdf_district_green_pip_inc.district_average_income, gdf_district_green_pip_inc.green_area_per_capita))print(pearsonr(gdf_district_green_pip_inc.district_average_income, gdf_district_green_pip_inc.green_area_per_capita))A causa della distribuzione pesantemente coda lunga dei dati finanziari, prenderei più seriamente la correlazione di Spearman (0,13) qui, ma anche la correlazione di Pearson (0,30) implica una tendenza relativamente debole, in linea con le mie osservazioni precedenti.






